논문 : Bandwidth Prediction in 5G Mobile Networks Using Informer

현재 내가 진행하고 있는 Real world Dataset에 대한 예측에 대해 다룬 선행 연구가 있어서 읽어봤다.
2022년 10월 논문인데 이미 해당 Dataset에 대한 풍부한 분석과 비교 모델들간의 분석이 잘 이뤄진 듯 하다.
5G 네트워크는 고주파를 사용하기 때문에 간섭, 경로 손실, 차단 등으로 인해 채널 품질이 시시각각 변화하는데,
이런 변동성은 전송 가능한 데이터 속도(throughput)의 급격한 변화로 이어진다.
따라서 향후 몇 초 후의 대역폭을 미리 예측해야 끊김 없는 통신, 안정적인 전송률 유지가 가능하다.
이것이 Traffic prediction이 중요한 이유!
기존의 Regression 및 Machine Learning 기반 방법들

2019년 7월에 게재된 위 논문은 packet-level metrics로 구성된 데이터셋을 이용하여, 자기회귀누적이동평균(ARIMA) 모델과 LSTM 모델의 성능을 비교한 논문이다. LSTM이 ARIMA보다 우수한 예측 성능을 보였다.

2022년 2월에 게재된 논문. Recursive Least Squares(RLS), Random Forest(RF), LSTM, Temporal Pattern Attention LSTM (TPA-LSTM)을 적용하여 5G 데이터셋과 같은 다변량 시계열을 예측한 결과 TPA-LSTM이 가장 뛰어난 성능을 보였다고 한다.
내가 진행하는 데이터셋은 다르지만 결과 지표를 확인하면 아래와 같다.
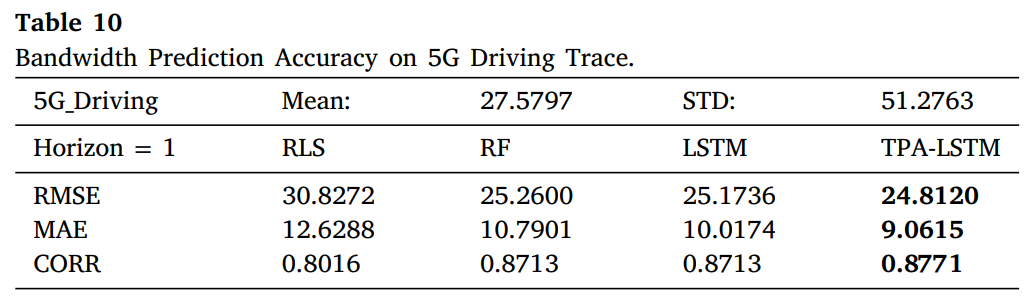
TPA-LSTM이 왜 그렇게 좋은가 보니, 네트워크 채널이나 Context 정보 속 숨겨진 Temporal Pattern을 효과적으로 추출하는데 강점이 있는데, 이것이 multivariate forecasting에 유리하기 때문이다.
해당 논문에서 제시하는 Transformer 기반 시계열 예측 방법
"Bandwidth Prediction in 5G Mobile Networks Using Informer" 논문에서는 Transformer 기반의 시계열 예측 문제를 다룬다.
Transformer는 변수 간의 시간 변화 패턴이나 상호 영향 관계를 정교하게 학습할 수 있지만,
장기 시계열 예측 (Long Sequence Time Series Forecasting, LSTF)에서는 시간 및 메모리 소모가 매우 심하다.
이를 해결하기 위해 Informer라는 모델이 새롭게 등장했는데, 이는 ProbSparse Self-Attention 메커니즘과 generative Decoder 구조를 도입했다.

제시하는 논문에서는 이 Informer 구조에 "Realtime mobile bandwidth and handoff prediction in 4G/5G networks"에서 제안된 Random Forest 기반 Feature Selection에다가 LASSO 회귀 및 새로운 하이퍼파라미터를 적용한 Optimized Random Forest를 TPA-LSTM과 Informer 모델에 결합한 새로운 조합을 탐색한다.
즉, TPA-LSTM이랑 Informer 구조에 각각 3가지 방식을 적용해서 총 6개의 모델을 비교하겠다는 것.

결과에서 보이듯, 2022년 당시 LSTM 중의 SOTA 모델보다 Informer 모델이 훨씬 성능이 뛰어남을 보이고 있다.
"Beyond Throughput, The Next Generation: A 5G Dataset with Channel and Context Metrics" 논문의 데이터셋 분석

1. 시계열 분해
이 논문에서는 Time Series Data를 분석하기 위해 시계열 분해를 사용하였다. (Time Series Decomposition)
시계열 분해란, 하나의 복잡한 시계열 데이터를 여러 Component로 나누어,
데이터의 구조적 특성과 변동 요인을 파악하는 분석 기법이다.
기본적으로 시계열 데이터는 단순히 시간에 따라 변화하는 값들의 집합이지만, 그 안에는 서로 다른 요인이 섞여있다.
시계열 분해는 이를 다음과 같이 분리해주는 과정이다.
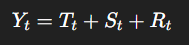
(덧셈형의 경우) - 변화의 크기가 일정할 때 사용
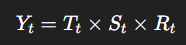
(곱셈형의 경우) - 변화의 폭이 데이터 크기에 비례할 때 사용.
여기서 Yt란 시계열의 실제 값, Tt란 추세 (장기적인 증가 혹은 감소 경향), St는 계절성 (주기적 반복 패턴), Rt는 잔차 (추세와 계절성을 제외한 불규칙한 요인을 뜻한다.
시계열 분해를 하면 다음과 같은 분석이 가능해진다.
- 추세 분석 → 데이터가 장기적으로 증가하는지, 감소하는지 파악
- 계절성 분석 → 주기적 변동이 있는지 확인 (예: 요일, 계절, 시간대별 패턴)
- 잔차 분석 → 노이즈나 이상치(outlier)를 탐지

본 논문에서 진행한 시계열 분석의 경우, 데이터가 2019년 11월, 12월, 1월, 2월에 일정 간격을 가지고 수집된 형태이다.
따라서 데이터가 특정한 추세와 계절적 패턴을 따르지는 않는다고 한다.
2. 정상적 검정 (Stationarity test)
정상성이란 시간이 흘러도 그 통계적 특성(평균, 분산, 자기상관 등)이 변하지 않는 시계열을 의미한다.
이는 곧 다음의 조건들을 만족한다.
| 구분 | 설명 |
| 평균의 일정성 | 시간이 지나도 평균값이 일정하다. |
| 분산의 일정성 | 데이터의 변동 폭(variance)이 일정하다. |
| 공분산의 일정성 | 두 시점 간의 상관관계가 시간 간격(lag)에만 의존하고, 절대 시점에는 의존하지 않는다. |
예를 들어, 온도가 하루 주기로 변하는 데이터(주기적 변동)은 평균이 계속 바뀌는 비정상 시계열이다.
반면, 평균이 0 근처에서 랜덤하게 출렁이는 white noise의 경우 정상 시계열이라고 할 수 있다.
정상성 검정은 이 데이터가 통계적으로 안정적인지, 혹은 시간에 따라 특성이 바뀌는지를 통계적으로 검증하는 절차이다.
많은 시계열 모델들 (AR, ARIMA 등)은 정상성을 전제로 한다.
만약 데이터가 비정상이라면, 먼저 차분 등의 변환으로 정상화해야 예측이 안정적으로 된다.
해당 논문에서는 아래 2개의 정상적 검정 기법을 사용했다.

우선, ADF 검정은 데이터가 비정상이라는 가정을 두고 시작해서 p값이 0.05보다 작다면 '비정상이라는 가설'을 기각하는,
'비정상이다'라는 가정을 뒤집는 테스트이다.
반대로, KPSS는 데이터가 정상이라는 가정에서 시작해서 p값이 0.05보다 작다면 '정상이라는 가설'을 기각하는,
'정상이다'라는 가정을 뒤집는 테스트이다.
이 두 Test는 서로 정반대 방향이기 때문에 둘을 모두 사용해야 확실하게 판정할 수 있다.
| ADF 결과 | KPSS 결과 | 의미 |
| 정상 | 정상 | 완전히 정상적인 데이터 |
| 비정상 | 비정상 | 확실히 비정상적인 데이터 |
| 엇갈림 | 엇갈림 | 애매함 → 추세 제거(Trend 제거)나 차분(Differencing) 필요 |
이 두 테스트를 진행한 결과, "Beyond Throughput, The Next Generation: A 5G Dataset with Channel and Context Metrics"에서 제시하는 5G 데이터셋은 Bandwidth 데이터의 평균과 분산이 시간에 따라 계속 변하고, Spike나 급격한 변화가 자주 발생하여 안정된 패턴이 없다는 뜻이다.
이런 경우 단순한 회귀나 AR 모델보다, Transformer, Informer, LSTM과 같은 복합 신경망 기반 예측 모델이 더 적합하다.
3. Feature Selection
그렇다면 모델의 학습에 있어서 사용되는 Feature는 어떻게 선택해야 하는 걸까?
여기서는 Grid Search를 이용한 하이퍼파라미터 튜닝과 LASSO라는 기법을 사용했다고 한다.

1. Grid Search를 이용한 하이퍼파라미터 튜닝
“그리드 서치(Grid Search)”는 모델의 하이퍼파라미터(설정값) 조합을 전부 시도해 보고,
가장 좋은 성능을 내는 조합을 자동으로 찾아주는 방법이다.
Random Forest 모델에는 여러 Hyperparmeter 값들이 있다.
| 하이퍼파라미터 | 의미 | 예시값 |
| n_estimators | 트리 개수 | 100, 200, 300 |
| max_depth | 트리의 최대 깊이 | 5, 10, 15 |
| min_samples_split | 분기 최소 샘플 수 | 2, 4, 6 |
예시의 값들을 모두 조합하면 3*3*3 총 27가지의 조합이 된다.
Grid Search는 이 27개의 조합 전부를 시험(training + validation) 해서 가장 성능이 좋은 하이퍼파라미터 세트를 자동으로 찾는다.
2. LASSO (Least Absolute Shrinkage and Selection Operator)
LASSO 회귀는 불필요한 변수의 가중치를 자동으로 0으로 줄이는 회귀 기법이다.
이는 곧 Feature Selection을 자동으로 수행하는 모델이다.

보통 회귀모델은 아래처럼 “오차를 최소화”하려고 학습한다.

LASSO는 여기에 규제항(regularization term)을 하나 더 추가한다.
여기서 βi는 각 특성(feature)의 계수이고, λ는 얼마나 강하게 규제할지 정하는 파라미터이다.
이때 λ가 커질수록, 중요하지 않은 특성의 βi가 0이 되어 자동으로 제외된다.
- Random Forest + Grid Search → 모델 성능을 최대화하면서, 어떤 특성이 중요한지를 평가
- LASSO → 중요하지 않은 변수를 자동으로 제거해 핵심 피처만 남기기
두 방법 모두 “중요한 특성을 찾는다”는 점에서 내재형(embedded) 특성 선택 기법으로 분류된다.

현재 내 모델은 NetworkMode, RSRP, UL_bitrate, NRxRSRP, DL_bitrate를 사용하고 있다.
이는 "[2025.06] Mobile Traffic Prediction using LLMs with Efficient In-context Demonstration Selection"이라는 동일한 데이터셋을 가지고 LLM Prediction을 수행한 논문에서 비교 스킴으로 LSTM을 설계할 때의 Feature를 참고한 것이다.
Informer 모델이란?
Informer (Zhou et al, AAAI 2021)은 Transformer를 긴 시계열 예측에 맞게 대폭 개선한 모델이다.
| 특징 | 설명 |
| ProbSparse Self-Attention | 모든 시점 간의 주의를 계산하지 않고, 가장 중요한 일부 시점만 선택해서 계산함 → 연산량이 O(n log n) 으로 줄어듦 |
| Distilling Layer (Layer-wise Distillation) |
각 계층(layer)에서 불필요한 정보를 압축(distill)하여 더 짧고 효율적인 시퀀스를 다음 층에 전달 |
| Long-range Dependency | 긴 기간의 의존 관계(예: 과거 몇 시간~며칠 전 트래픽 패턴)를 효율적으로 학습 |
| Memory Efficient Encoder-Decoder | 시계열 예측에 특화된 구조로, 일반 Transformer보다 GPU 메모리 사용량 1/5 이하 |
쉽게 이야기해 Transformer가 모든 시점을 다 보면서 예측하는 방식이라면, Informer는 그 중 정보량이 큰 중요한 시점만 뽑아서 예측하는 느낌이다. (Informer가 핵심 정보만 보고 미래를 더 정확하고 빠르게 예측함)

논문의 결론

위 그래프가 본 논문에서 제시하는 최종 결론이다.
Informer가 대체로 LSTM보다는 월등한 퍼포먼스를 보인다.
1. 모델의 구조 + Feature Selection
주목할 점은 TPA-STM + RF와 O-TPA-LSTM + O-RF의 성능 차이가 상당히 크게 난다는 것.
이는 단순히 "같은 모델 구조를 썼느냐"보다 하이퍼파라미터 최적화나 Feature Selection의 정밀도, 모델 복잡도 차이에 기인한다.
The O-TPALSTM neural network structure consists of 1 layer with 128 units, while the TPA-LSTM model from the paper [3] contains three layers, each having 32 units.
- 기존 TPA-LSTM + RF: 3-layer × 32 unit
- O-TPA-LSTM + O-RF: 1-layer × 128 unit
이는 기존 모델은 얕지만 깊은 구조 (3층, 좁은 폭)를 가지는데 이는 시간적 의존성은 학습이 가능하지만 일반화가 약하고,
최적화된 모델(O-TPA-LSTM)은 얕고 넓은 구조 (1층, 폭이 큼)를 가지는데, 이것이 비선형 패턴을 잘 표현하고 과적합 위험을 줄인다고 이야기하고 있다.
즉, O-TPA-LSTM은 더 단순하지만 expressive capacity가 높은 구조로 재설계되어 성능이 향상된 것.
또한, 하이퍼파라미터를 최적화했다는 부분이다.
논문에서 다음과 같이 명시되어 있다.
“Afterward, we used grid search to tune the hyper-parameters of the TPA-LSTM and Random Forest Regression and denote them as O-TPA-LSTM and O-RF, respectively.”
이 부분은 기존 RF / TPA-LSTM은 default 설정을 따른 반면, O-TPA-LSTM, O-RF는 Grid Search로 최적화된 설정값을 사용했다는 내용이다. 이는 곧 최적의 learning rate, batch size, optimizer, dropout 값 등을 사용했음을 뜻한다.

특히, O-TPA-LSTM 구조에 LASSO를 사용한 모델이 가장 정확도가 높았는데,
기존 TPA-LSTM의 구조와 입력 특성(feature set)을 “최적화된 LSTM + 정규화 기반 특성 선택(LASSO)”으로 재설계한 결합형 접근법이 가장 뛰어난 성능을 보였다.
-> Point. 꼭 모델의 크기가 크다고 능사가 아니다!
2. Window Size를 어떻게 할 것인지?
지금까지는 5개의 Window Size만을 가지고 학습을 진행했다.
본 논문에서는 다양한 Window Size에 더해, 미래의 몇 개의 Throughput 값을 예측할 것인지를 동적으로 변화시키며 학습을 진행했다. (다른 논문들을 찾아봐도 Window Size가 16, 32, 100을 넘어가는 것도 있었음. 미래에 몇 개를 예측할지도 가변적)
이 부분도 다양하게 변화해가면서 실험을 진행하는 것이 중요할 듯!
'딥러닝 모델 > LSTM for Traffic Prediction' 카테고리의 다른 글
| RSRP 예측 Task에 대한 LSTM과 LLM의 비교 (0) | 2025.10.28 |
|---|---|
| 실제 RSRP 예측을 위한 Feature Selection (0) | 2025.10.27 |
| Downlink Throughput 예측 Task에 대한 LSTM과 LLM의 비교 (0) | 2025.10.27 |
| LSTM 모델로 실제 Downlink Throughput 예측하기 (0) | 2025.10.24 |
| LSTM 모델의 UE Location Prediction과 Systemic bias 문제 (0) | 2025.10.14 |