Real World Dataset
다양한 네트워크 데이터 수집 자료 중, "Beyond Throughput, The Next Generation: A 5G Dataset with Channel and Context Metrics"라는 논문에서 제공하는 Dataset을 사용하기로 결정했다.

이 데이터셋은 아일랜드의 주요 이동통신 사업자로부터 수집한 5G Trace Dataset이라고 한다.
총 3가지 Application Pattern (Netflix, Download, Amazon)에서 각각 2가지 이동패턴 (Car, Static)을 가지고 생성되었다.
이 Dataset은 Client 측 Cellular KPI로 구성된다.

여기서 주요 KPI는 1초마다 수집되는 Time series Dataset으로, (위도, 경도 값), 속도, RSRP, RSRQ, SNR, CQI, RSSI, DL_bitrate, UL_bitrate, 다른 인접 셀의 RSRP 등이 있다.
전처리 과정
# Amazon_Prime 폴더 경로
folder_path = "Amazon_Prime/Driving"
# 최종 LSTM feature 컬럼
feature_cols = ["Longitude", "Latitude", "Speed", "NetworkMode", "RSRP", "RSRQ", "DL_bitrate", "UL_bitrate", "NRxRSRP", "NRxRSRQ"]
# 삭제할 컬럼 목록
drop_cols = [
"Operatorname", "CellID", "SNR", "CQI", "RSSI", "State", "PINGAVG",
"PINGMIN", "PINGMAX", "PINGSTDEV", "PINGLOSS", "CELLHEX", "NODEHEX",
"LACHEX", "RAWCELLID"
]
# Amazon_Prime 폴더의 모든 CSV 파일
file_list = glob.glob(os.path.join(folder_path, "*.csv"))
print(f"발견된 CSV 파일 수: {len(file_list)}")
for file_path in file_list:
print(f"\n===== Processing: {file_path} =====")
# 1. CSV 파일 읽기
df = pd.read_csv(file_path)
print("원본 컬럼명:", list(df.columns)) # 디버깅용 컬럼명 확인
# 2. 불필요한 컬럼 삭제
cols_to_drop = [c for c in drop_cols if c in df.columns]
df = df.drop(columns=cols_to_drop, errors="ignore")
print("삭제한 컬럼:", cols_to_drop)
# 3. "-" → NaN 변환
df = df.replace("-", np.nan)
# 4. NetworkMode 매핑 (5G→0, LTE→1, 3G 계열→2)
if "NetworkMode" in df.columns:
mapping = {
"5G": 0,
"LTE": 1,
"HSPA+": 2,
"HSDPA": 2,
"HSUPA": 2,
"UMTS": 2
}
df["NetworkMode"] = df["NetworkMode"].map(mapping)
# 5. 숫자형 변환
for col in feature_cols:
if col in df.columns:
df[col] = pd.to_numeric(df[col], errors="coerce")
else:
print(f"경고: {col} 컬럼이 없음")
# 6. NaN 행 제거
before_rows = len(df)
df = df.dropna(subset=[c for c in feature_cols if c in df.columns]).reset_index(drop=True)
print(f"NaN 제거: {before_rows} → {len(df)} 행 남음")
# 7. CSV 덮어쓰기
df.to_csv(file_path, index=False)
print(f"저장 완료: {file_path}")
print("\n모든 CSV 파일 처리 완료!")
| 단계 | 작업 내용 | 목적 |
| 1️⃣ 파일 검색 | Amazon_Prime/Driving/*.csv 경로에서 모든 CSV 파일 탐색 | 처리 대상 자동 수집 |
| 2️⃣ 파일별 반복 처리 | 각 CSV를 순회하며 전처리 수행 | 개별 파일 정제 |
| 3️⃣ 불필요 컬럼 제거 | Operatorname, CellID, RSSI, PING*, CELLHEX 등 삭제 | LSTM에 불필요한 메타 정보 제거 |
| 4️⃣ 결측 기호 처리 | "-" 값을 NaN으로 변환 | 비정상 문자열 → 결측값 표준화 |
| 5️⃣ NetworkMode 매핑 | 5G→0, LTE→1, HSPA+/HSDPA/HSUPA/UMTS→2 | 네트워크 기술을 정수형으로 |
| 6️⃣ 숫자형 변환 | Longitude, Speed, RSRP, DL_bitrate 등 feature 컬럼을 float로 변환 | 문자열 숫자 → 실수(float) |
| 7️⃣ NaN 제거 | feature 컬럼 중 하나라도 NaN인 행 삭제 | LSTM 입력값의 결측 제거 |
| 8️⃣ 덮어쓰기 저장 | 전처리된 DataFrame을 원래 파일 경로에 저장 | CSV 정제 결과 반영 |
기본적인 파일의 전처리를 다음과 같이 수행했다.
우선, 모든 CSV 파일에 대해 남길 Column을 선정하고, 나머지 Column들을 삭제한다.
(PINGAVG와 같은 값들은 대부분 결측치이므로 삭제, RawCellID 등도 항상 일정한 값이므로 삭제)
그 다음으로 "-"를 NaN 값으로 변환한 후, NetworkMode에 대한 값을 매핑한다 (5G는 0, LTE는 1, 3G는 2).
이후 모든 데이터를 숫자형으로 변환한 다음 결측치를 제거하고 저장한다.

전처리 후의 값은 위와 같다.
예측에 사용된 Feature들
여기서 Downlink Traffic 예측을 위해 다음 4가지 특징을 선택해서 LSTM 모델을 학습하였다.
- 업링크 처리량 (uplink throughput)
- 현재 연결된 셀의 기준 신호 수신 전력 (RSRP of the current cell)
- 인접 셀의 RSRP (RSRP of the neighboring cell)
- 네트워크 모드 (network mode)
이런 선택은 "Mobile Traffic Prediction using LLMs with Efficient In-context Demonstration Selection" 논문을 참조했다.
그리고 나서 앞선 O-RAN Dataset과 유사한 모델을 통해 학습을 진행했는데 학습 결과가 다음과 같이 나왔다.

실제 추론 결과를 나타내는 CSV 파일을 보면 이상한 점이 명확하게 드러난다.
대부분의 예측값이 평균인 774 부근에서 이동하는 형태이다. (뭔가 이상하다!)

그래서 일단 LSTM 모델이 학습할 때 쓰인 Data에 대한 Inference 결과를 확인했다. (확실히 이상하다!)

해결 과정
일단 Train data와 Test data의 통계 분포를 살펴본다.
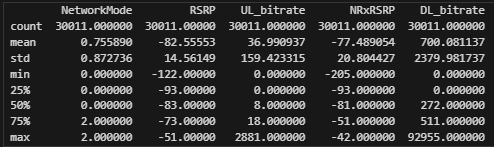

왼쪽이 train data의 describe() 결과이고, 오른쪽이 test data의 describe 결과이다.
Train 데이터와 Test 데이터를 보면 bitrate 값이 굉장히 특이한 분포를 보인다.
25%의 값들이 0일 정도로 0의 개수가 상당히 많지만, max값은 2000대에서 90000까지 올라갈정도로 Scale이 크다.
이처럼 값의 범위가 수천, 수만 단위인 동시에 0이 많은, 분포가 치우친 값들은 LSTM 모델이 제대로 학습할 수 없다.
이것이 문제인 이유는 다음으로 정리할 수 있다.
- 스케일 차이가 너무 크면 → 큰 값이 loss를 지배
- 예: 90000 vs 100 → MSE 기준으로 큰 값 쪽만 맞추려 함
- 모델이 평균 근처 값만 출력하게 됨 (현재 774만 출력되는 것처럼.)
- 0 값이 많으면 → log 변환 시 log(0) 에러
- 그래서 log(1+x) 를 사용해 0도 안전하게 변환
- 비대칭 분포(skew) → 모델이 평균에만 수렴
- DL_bitrate가 90% 이상 0~500인데 10%는 90000이면
→ 예측이 “중간값만 고정”되는 경향을 보이게 된다.
- DL_bitrate가 90% 이상 0~500인데 10%는 90000이면
첫 번재 해결책. 따라서 bitrate와 관련된 데이터를 log1p transform을 통해 Scaling을 진행했다.
# Downlink Bitrate 변수에 log transform 적용
# Throughput 데이터는 스케일이 크고 0값이 많아 log(1+x) 변환이 효과적
train_df['DL_bitrate_log'] = np.log1p(train_df['DL_bitrate'])

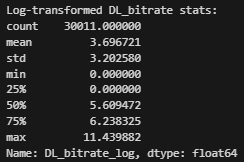
이를 통해 다음을 기대할 수 있게 된다.
| 문제 | 변환 후 효과 |
| 값이 너무 큼 | 로그를 취하면 스케일 축소 → log(1+90000) ≈ 11.4 |
| 값의 차이가 너무 큼 | 큰 값과 작은 값의 비율이 완화됨 |
| 0값 존재 | log(1+0)=0 → 안전 |
| 분포가 한쪽으로 치우침 | 오른쪽 꼬리가 줄어듦 → 근사적으로 정규분포화 |
이후, 이미 범주형 변수인 NetworkMode(0, 1, 2)를 제외하고, 나머지 값들(log 변환된 bitrate 포함)을 MinMaxScaling을 진행함.
이게 log transform 없이 모든 값에 MinMaxScaling을 적용하고 LSTM 모델을 학습한 결과값.
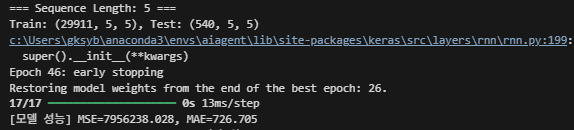
DL_bitrate와 UL_bitrate 모두에 log transform을 진행한 결과값은 다음과 같다.


마지막으로 DL_bitrate에 log transform을 진행한 결과값은 아래와 같다.

마지막 DL_bitrate만 log transform한 결과가 성능이 소폭 개선되었다.

또한, 0인 데이터와 10000이 넘는 데이터를 어느정도 예측하는 경향을 확인할 수 있다.
(아마 UL_bitrate는 최댓값이 2000 정도밖에 되지 않아서 log transform을 하면 오히려 성능이 떨어지는 듯)

이제 어느정도의 경향성을 띠는 형태를 보인다. 하지만 여전히 성능은 아쉬운 상황.
두번째 해결책. DL_bitrate의 단위를 kbps에서 Mbps로 바꾸자.

이 데이터셋을 이용해 LLM의 정확도를 측정한 논문에서는 Downlink throughput을 kbps에서 Mbps로 변환하여 성능평가를 진행하였다.

해당 논문에서 제시하는 LLM과 LSTM의 MAE, RMSE, R2 Score 값은 위와 같았다.
이처럼 현재 90000이라는 값이 존재하는 kbps Scale을 Mbps로 변환하여 학습을 진행하였다.
# Amazon_Prime 폴더 경로
folder_path = "Amazon_Prime/Driving"
# 최종 LSTM feature 컬럼
feature_cols = ["Longitude", "Latitude", "Speed", "NetworkMode", "RSRP", "RSRQ", "DL_bitrate", "UL_bitrate", "NRxRSRP", "NRxRSRQ"]
# 삭제할 컬럼 목록
drop_cols = [
"Operatorname", "CellID", "SNR", "CQI", "RSSI", "State", "PINGAVG",
"PINGMIN", "PINGMAX", "PINGSTDEV", "PINGLOSS", "CELLHEX", "NODEHEX",
"LACHEX", "RAWCELLID"
]
# Amazon_Prime 폴더의 모든 CSV 파일
file_list = glob.glob(os.path.join(folder_path, "*.csv"))
print(f"발견된 CSV 파일 수: {len(file_list)}")
for file_path in file_list:
print(f"\n===== Processing: {file_path} =====")
# 1. CSV 파일 읽기
df = pd.read_csv(file_path)
print("원본 컬럼명:", list(df.columns)) # 디버깅용 컬럼명 확인
# 2-1. DL_bitrate와 UL_bitrate를 KB에서 MB로 변환 (1/1000)
if "DL_bitrate" in df.columns:
df["DL_bitrate"] = df["DL_bitrate"] / 1000
if "UL_bitrate" in df.columns:
df["UL_bitrate"] = df["UL_bitrate"] / 1000
# 7. CSV 덮어쓰기
df.to_csv(file_path, index=False)
print(f"저장 완료: {file_path}")
print("\n모든 CSV 파일 처리 완료!")


Scale이 1/1000로 줄었을 때 MAE가 0.818으로, kbps와 비교하면 MAE가 818정도로 성능이 나왔다.
그런데 일정한 값만을 예측하는 문제가 다시 생겼다. (이건 기각)
오히려 scale을 줄이면서 log transform + MinMaxScale을 동시에 하는 건 성능을 악화시킨다.
세번째 해결책. Training Epoch의 수를 늘리자
이번에는 Early Stopping을 적용하지 않고, Epoch을 총 100번 수행한 다음, 그 중 최고 성능의 모델을 저장했다.
이런 경우에도 최고 성능을 보이는 Epoch는 41에 머무르며, MAE값도 개선되지 않는다.

네번째 해결책. 모델의 사이즈를 키우자
현재 LSTM 모델의 사이즈는 다음과 같다.
# 현재 LSTM 모델 구조
def build_model(input_shape):
model = Sequential([
LSTM(120, activation='tanh', recurrent_activation='sigmoid', return_sequences=True, input_shape=input_shape),
Dropout(0.2),
LSTM(50, activation='tanh', recurrent_activation='sigmoid', return_sequences=True),
Dropout(0.2),
LSTM(50, activation='tanh', recurrent_activation='sigmoid', return_sequences=True),
Dropout(0.2),
LSTM(50, activation='tanh', recurrent_activation='sigmoid'),
Dropout(0.2),
Dense(64, activation='linear'),
Dense(1, activation='linear') # 최종 DL_bitrate_log 예측
])
optimizer = RMSprop(learning_rate=0.01)
model.compile(optimizer=optimizer, loss='mean_squared_error')
return model
여기서 모델의 사이즈를 조금 더 키워서 학습을 진행해보았다.
# Hidden Unit 수 늘리기
def build_model(input_shape):
model = Sequential([
LSTM(256, activation='tanh', recurrent_activation='sigmoid', return_sequences=True, input_shape=input_shape),
Dropout(0.3),
LSTM(128, activation='tanh', recurrent_activation='sigmoid', return_sequences=True),
Dropout(0.3),
LSTM(64, activation='tanh', recurrent_activation='sigmoid', return_sequences=True),
Dropout(0.3),
LSTM(64, activation='tanh', recurrent_activation='sigmoid'),
Dropout(0.3),
Dense(128, activation='relu'),
Dense(1, activation='linear')
])
optimizer = RMSprop(learning_rate=0.005)
model.compile(optimizer=optimizer, loss='mean_squared_error')
return model
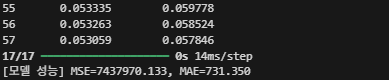

다섯번째 해결책. Amazon_Prime 말고 더 많은 Data로 Training을 진행해보자.
이제 Driving과 관련된 모든 Training Data를 가지고 학습을 진행했다.


크게 달라지지는 않은 모습.
일단은 DL_bitrate에 Log Transform을 적용한 것이 가장 주효한 것으로 보인다.
To be continued..
'딥러닝 모델 > LSTM for Traffic Prediction' 카테고리의 다른 글
| LSTM 학습과 관련된 몇 가지 Technique (0) | 2025.10.27 |
|---|---|
| Downlink Throughput 예측 Task에 대한 LSTM과 LLM의 비교 (0) | 2025.10.27 |
| LSTM 모델의 UE Location Prediction과 Systemic bias 문제 (0) | 2025.10.14 |
| ns3-oran 시뮬레이션 데이터 기반의 RSRP 예측 (0) | 2025.10.13 |
| LSTM : 긴 문맥을 놓치지 않는 RNN의 진화 버전 (0) | 2025.09.30 |