UE의 위치를 추정하는 LSTM 모델
RSRP 값을 예측하는 모델에 이어서, 그 다음으로는 UE의 위치를 추정하는 LSTM 모델을 생각할 수 있다.
이 역시 무선 네트워크 운영에서 매우 중요한데,
일단 이 정보를 이용하면 GPS 없이도 실내나 도시 환경에서의 UE의 위치를 추정할 수 있다.
네트워크는 이 정보를 활용해 핸드오버 최적화, 빔포밍, 자원 재할당 등을 지능적으로 수행할 수 있게 된다.
UE Localization

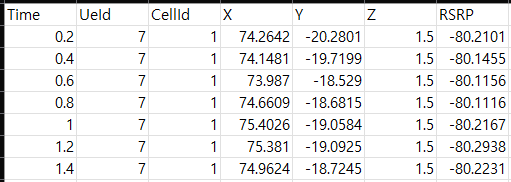
이제 총 4개의 기지국에서 측정된 RSRP값 를 기반으로 UE의 X, Y 좌표의 Location을 찾는 LSTM 모델을 생각할 수 있다.
이를 위해 ns3-oran에서 생성된 각 기지국 별 Dataset을 모두 합쳐 X, Y 좌표에 따른 RSRP 값으로 전처리를 진행했다.

마찬가지로 기지국 근처에서 랜덤하게 움직이는 ue7을 Testset으로 삼았고, Trainset을 변화해가면서 모델의 성능을 테스트했다.
Training 결과와 Systemic bias 문제

결과를 보면 LSTM의 예측값과 실제값이 일정한 offset을 가짐을 확인할 수 있었다.
이는 곧 모델이 "추세"는 잘 따라가지만 절대적인 "기준선"을 잘못 학습함을 뜻한다.
원인 분석
# 전체 feature (RSRP1, RSRP2, RSRP3, RSRP4, X, Y) 스케일링
scaler_all = MinMaxScaler(feature_range=(0, 1))
scaler_all.fit(train_df.values)
# X, Y 복원용 스케일러 (target만 따로)
scaler_xy = MinMaxScaler(feature_range=(0, 1))
scaler_xy.fit(train_df[['X', 'Y']].values)
===========================================================
# 예측 (스케일된 값)
y_pred_all_scaled = m_all.predict(X_test_all)
y_pred_loc_scaled = m_location.predict(X_test_loc)
# 스케일링 복원 (X, Y 2차원)
y_pred_all = scaler_xy.inverse_transform(y_pred_all_scaled) # (N, 2)
y_true_all = scaler_xy.inverse_transform(y_test_all) # (N, 2)
y_pred_loc = scaler_xy.inverse_transform(y_pred_loc_scaled) # (N, 2)
y_true_loc = scaler_xy.inverse_transform(y_test_loc) # (N, 2)
현재 코드에서는 데이터셋을 MinMax Scaler를 이용해서 학습을 했다.
MinMaxScaler의 공식은 다음과 같다.
X_scaled = (X - X_min_train) / (X_max_train - X_min_train)
여기서 문제는 Train set (ue9~uef16)의 X, Y 범위로 Scaler를 학습했는데,
Test set (ue7)의 X, Y 범위가 Train set과 다르면 문제가 발생한다는 것이다.

Dataset을 보면 알겠지만 ue9에서 ue16의 경우 기지국보다 훨씬 먼 위치까지 이동을 한다.
그러나 ue7과 ue8은 빨간색 X로 표시된 기지국 주변에서만 움직이는 것을 확인할 수 있다.
즉, Train Set의 ue 범위가 X, Y 값이 2000을 넘어가기도 하는 상황에서,
Test Set의 범위가 (X는 -73 ~ 81, Y는 -20~-18) 이보다 훨씬 작은 Scale로 이루어진다는 것이다.
결국, Train과 Test의 공간적 분포가 상당히 다르다는 것!
Train Set의 중심과 Test Set의 중심이 서로 다른 상황인데 MinMaxScaler는 절대적 위치를 기준으로 스케일링하므로,
모델은 train 범위의 상태적 위치를 학습하게 되고, 이를 Test set에 적용했기에 일정한 offset만큼 shift됨을 알 수 있다.
해결 : StandardScaler 사용
# 전체 feature (RSRP1, RSRP2, RSRP3, RSRP4, X, Y) 스케일링
# StandardScaler: 평균=0, 표준편차=1로 정규화 → 분포 변화에 덜 민감
scaler_all = StandardScaler()
scaler_all.fit(train_df.values)
# X, Y 복원용 스케일러 (target만 따로)
scaler_xy = StandardScaler()
scaler_xy.fit(train_df[['X', 'Y']].values)
================================================================
# 예측 (스케일된 값)
y_pred_all_scaled = m_all.predict(X_test_all)
y_pred_loc_scaled = m_location.predict(X_test_loc)
# 스케일링 복원 (X, Y 2차원)
y_pred_all = scaler_xy.inverse_transform(y_pred_all_scaled) # (N, 2)
y_true_all = scaler_xy.inverse_transform(y_test_all) # (N, 2)
y_pred_loc = scaler_xy.inverse_transform(y_pred_loc_scaled) # (N, 2)
y_true_loc = scaler_xy.inverse_transform(y_test_loc) # (N, 2)
위를 적용해서 LSTM 모델을 학습한 결과는 다음과 같다.


Test Dataset과 유사한 움직임을 가지는 ue8을 학습에 포함시키면 MinMaxScaler보다 조금 더 Offset 없이 Ground Truth에 가깝게 이동함을 확인할 수 있다.
반면, ue8을 학습에 포함시키지 않은 오른쪽 그래프의 경우 Offset이 더 커졌을 뿐만 아니라, 찌그러진 형태도 관찰된다.
이는 StandardSclaer를 적용할 때 Train Datset과 Test Dataset의 평균 뿐만 아니라 분산도 다르기 때문이다.
StandardScaler는 각 feature에 대해 다음 연산을 수행한다.

이때, (x, y) 좌표처럼 서로 다른 단위나 분산을 가진 feature가 있을 경우,
Scaling 후 상대적인 축 비율이 깨질 수 있다.
그렇다면 왜 초록색 (Position-only)의 경우만 찌그러졌을까?
파란색 (All Features) 모델은 RSRP, RSRQ, SINR 같은 다른 feature들과 함께 정규화되었기 때문에
좌표 단독의 스케일링 비율 차이가 상대적으로 완화되는 효과가 있다.
반면 초록색(Position-only) 모델은 (x, y) 두 feature만 정규화되면서
각 축이 독립적으로 평균 0, 분산 1로 맞춰졌기 때문에 원래의 거리 비율(X:Y)이 달라졌기 때문이다.
Robust Scaler를 사용했을 경우

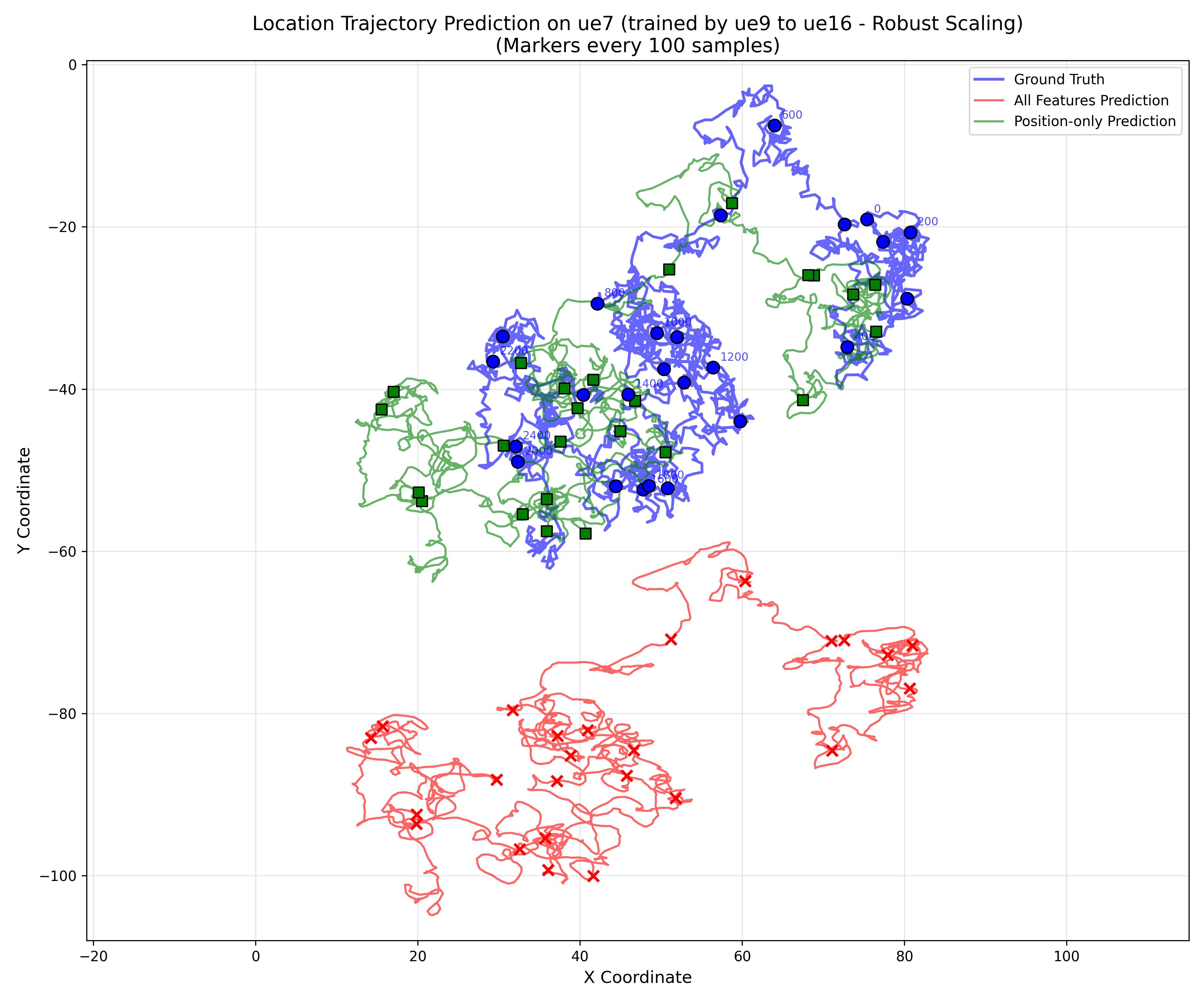
RobustScaler는 평균과 표준편차 대신 중앙값과 IQR로 정규화된다.

이는 곧 중앙값을 0으로 이동시키고, 중간 50% 범위(IQR)을 ±1 단위로 Scaling한다.
이렇게 하면 outlier의 영향을 줄이고 중간 분포에 집중할 수 잇게 된다.
그런데 우리가 사용한 좌표 데이터는 outlier 제거형 데이터가 아니다.
UE Trajectory의 경우 다음과 같은 특성이 있다.
- X, Y 좌표의 분포가 편향(skewed) 되어 있음 (예: 한 방향으로만 이동)
- 값의 범위가 물리적으로 유의미함 (절대 거리/위치가 의미를 가짐)
- 시간에 따라 누적 이동 → 데이터 대부분이 한쪽에 치우침
이런 데이터에 중앙값/사분위 기반 스케일링을 적용하면 문제가 생기게 됨을 확인할 수 있다.
Robust Scaler에서 RSRP를 포함한 모든 feature를 사용하는 것이 아니라 좌표 데이터만 쓴 경우가 더 학습이 잘 진행된 것 처럼 보이는데, 그 이유는 다음과 같이 생각할 수 있다.
- All-feature 모델은 RobustScaler가 각 feature마다 다른 스케일 기준을 적용해서 좌표의 영향력이 상대적으로 약화됨.
- 반면 Position-only 모델은 (x, y) 두 축만 동일 스케일에서 학습하므로 상대적 좌표 구조를 유지할 수 있었음
→ 그래서 더 안정적 trajectory.
'딥러닝 모델 > LSTM for Traffic Prediction' 카테고리의 다른 글
| Downlink Throughput 예측 Task에 대한 LSTM과 LLM의 비교 (0) | 2025.10.27 |
|---|---|
| LSTM 모델로 실제 Downlink Throughput 예측하기 (0) | 2025.10.24 |
| ns3-oran 시뮬레이션 데이터 기반의 RSRP 예측 (0) | 2025.10.13 |
| LSTM : 긴 문맥을 놓치지 않는 RNN의 진화 버전 (0) | 2025.09.30 |
| RNN: 시간의 흐름을 기억하며 미래를 예측하는 모델 (0) | 2025.09.30 |