전체적인 데이터 개요
Downlink Throughput을 위한 데이터셋은 크게 6가지 종류로 나뉜다.
크게는 Amazon_Prime 데이터, Download 데이터, Netflix 데이터로 구분되고,
이들은 다시 각각 Driving Data와 Static Data로 구분된다.

각 csv 데이터마다 다양한 feature 값들이 있는데, 이미 선행연구에서 제시한대로, 이 중 가장 DL_bitrate와 상관관계가 높은
Speed, NetworkMode, RSRP, UL_bitrate, NRxRSRP를 LSTM 학습에 사용하였다.
DL_bitrate의 형태를 고려해서 DL_bitrate에만 log Transform을 진행하였다.
MinMaxScaling을 적용하여 학습하였다.
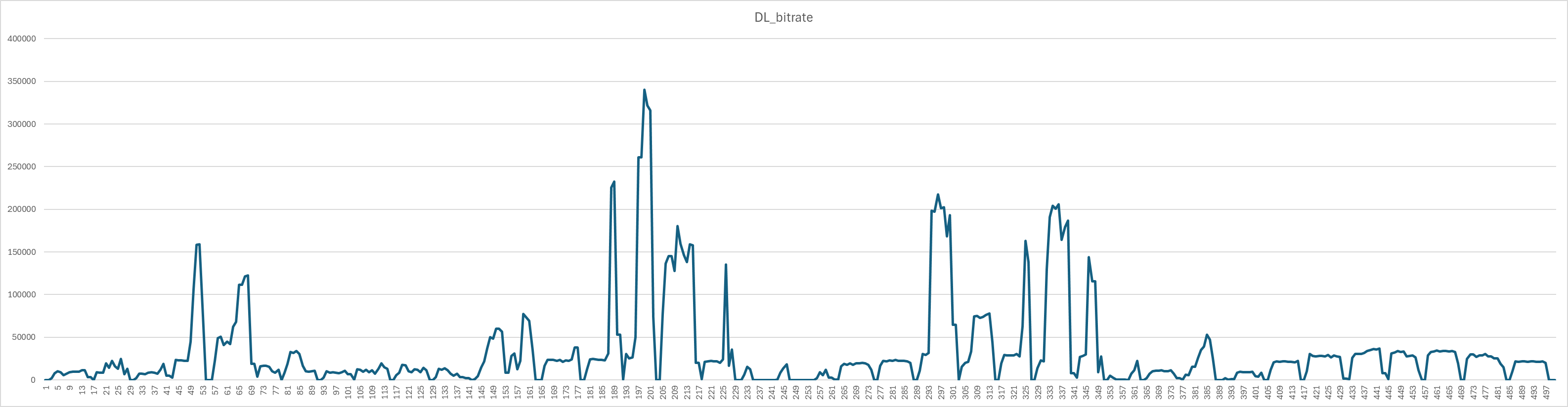
Test 데이터로는 DL_bitrate의 Burst한 현상을 잘 보여주는 값으로 500초간의 연속적인 Timestamp를 선정했다.
LSTM과 LLM의 비교
이 Task의 목적은 LLM의 Generalization 능력을 확인하는 것이다.
LLM은 하나의 Pretrained 모델로서 다양한 Task에 일반화 능력을 가지지만,
LSTM은 자신이 학습하지 않은 데이터에 대해서는 매우 떨어지는 성능을 가질 것이라고 가정할 수 있다.
1. Seen-LSTM
우선, Download Data를 학습한 LSTM을 Download Data Testset에 적용한 결과는 아래와 같다.

2. LLM
그 다음으로, LLM을 Download Traffic Prediction에 활용한 결과는 아래와 같다.
LLM 모델로 Phi-3-mini 모델을 사용하였으며, Prompt는 아래와 같이 제시하였다.
prompt = ChatPromptTemplate.from_messages([
("system",
"You are a precise Downlink Bitrate forecaster. "
"Given the last 5 Downlink Bitrate measurements, predict the NEXT timestep's Downlink Bitrate (kbps). "
"Use temporal patterns, handle noise/spikes robustly. "
"Output Number only; no explanation."),
("human",
f"Here are the training examples:\n{examples_text}\n\nQuestion:\n{target_text}")
])
결과 그래프는 아래와 같다.
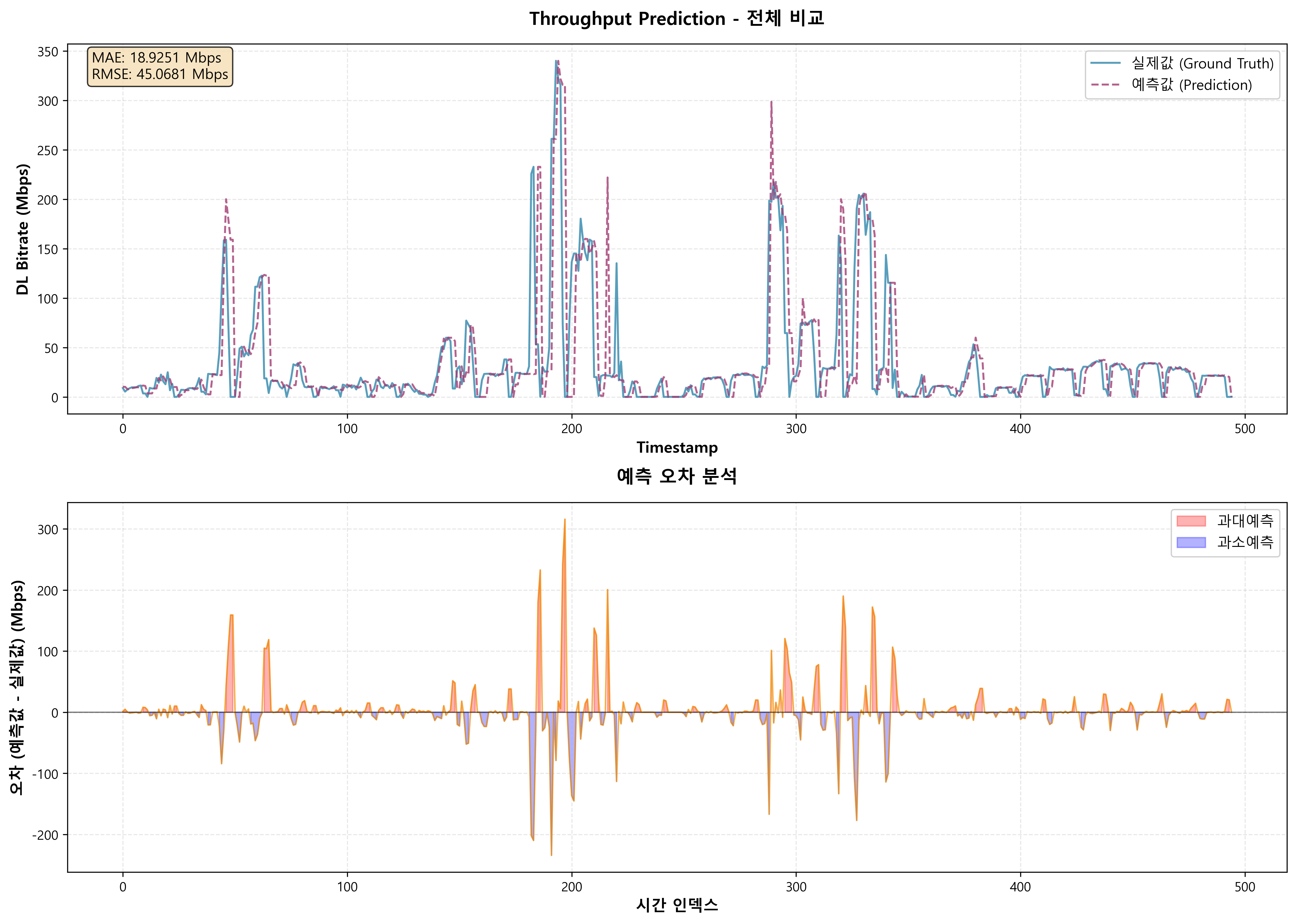
언듯 보기에는 잘 예측한 것 처럼 보이지만, 오차를 분석하면, 실제값보다 조금씩 늦은 타이밍으로 Traffic을 예측하는 모습이다.
(이전 Timestamp의 실제값을 답습하는 경향이 있음)
또한 LSTM 모델보다 과대예측하는 경향이 현저히 큼을 확인할 수 있다.
3. Unseen-LSTM
마지막으로 Amazon_Prime과 Netflix 데이터로 학습하고, Download 데이터에 대한 예측값이다.
이는 LSTM이 실제 테스트 데이터에 대한 지식을 학습하지 않은 상황을 나타낸다.

이 경우에는 가장 큰 오차가 발생하였다.
각 3가지 Case의 MAE와 RMSE 값을 정리하면 아래와 같다.
| Seen-LSTM | LLM | Unseen-LSTM | |
| MAE | 16.0950 | 18.9251 | 27.8196 |
| RMSE | 35.5650 | 45.0681 | 54.2901 |
'딥러닝 모델 > LSTM for Traffic Prediction' 카테고리의 다른 글
| 실제 RSRP 예측을 위한 Feature Selection (0) | 2025.10.27 |
|---|---|
| LSTM 학습과 관련된 몇 가지 Technique (0) | 2025.10.27 |
| LSTM 모델로 실제 Downlink Throughput 예측하기 (0) | 2025.10.24 |
| LSTM 모델의 UE Location Prediction과 Systemic bias 문제 (0) | 2025.10.14 |
| ns3-oran 시뮬레이션 데이터 기반의 RSRP 예측 (0) | 2025.10.13 |