지금까지 Policy Gradient, REINFORCE, Actor-Critic, 그리고 TD Actor-Critic까지 살펴보았다.
이 알고리즘들은 모두 Agent 하나가 환경을 돌아다니며 경험을 모으고, 그 경험을 이용해 학습하는 방식이었다.
하지만 이러한 구조에는 한 가지 한계가 있다.
경험을 쌓는 속도가 결국 단일 Agent의 속도에 제한된다는 점이다.

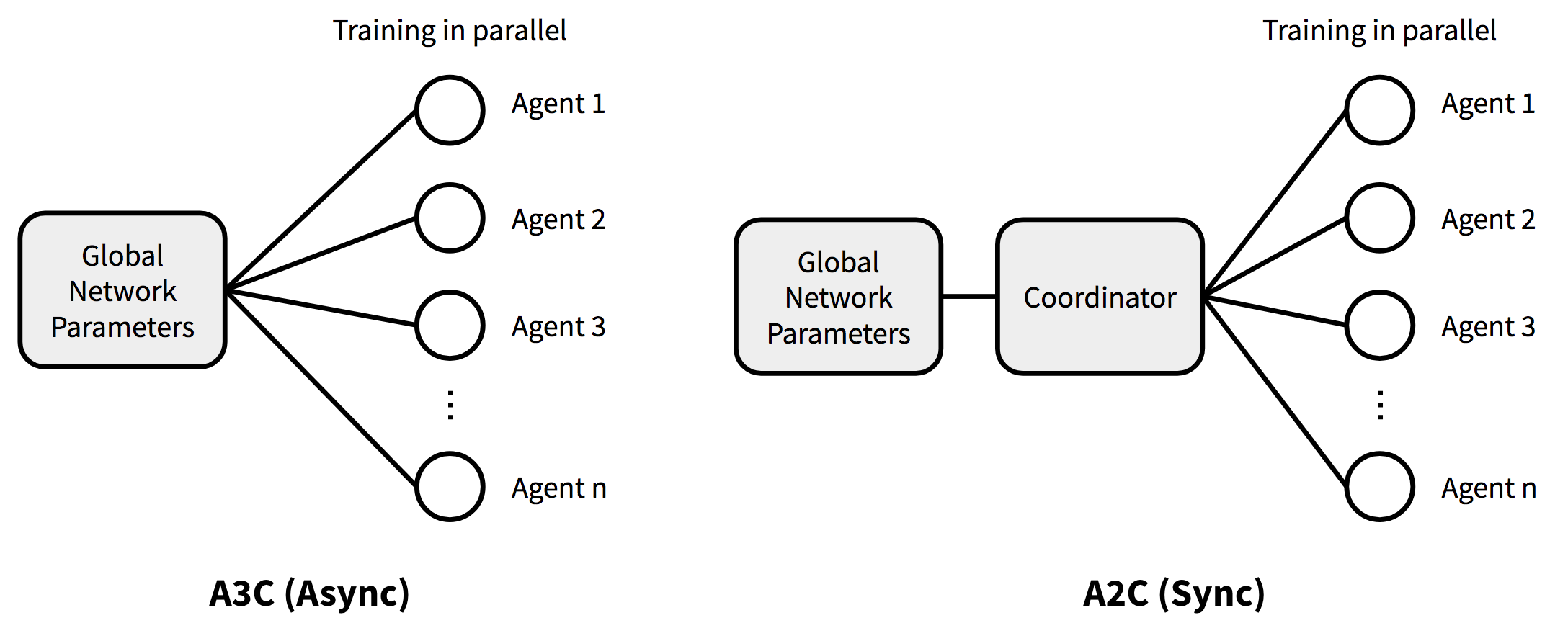
이러한 문제를 해결하기 위해 A3C (Asynchronous Advantage Actor-Critic)라는 알고리즘이 제시되었다.
이 알고리즘은 2016년에 Google DeepMind 연구진이 발표한 논문으로,당시 강화학습에서 State-of-the-Art 성능을 달성하였다.
A3C (Asynchronous Advantage Actor-Critic)
A3C의 핵심 아이디어
지금까지의 강화학습은 다음과 같은 방식으로 진행되었다.
- Agent 하나가 환경을 돌아다니며 경험을 수집
- 수집된 경험으로 네트워크 업데이트
- 업데이트된 Agent가 다시 경험 수집
즉 경험 수집과 학습이 순차적으로 진행되는 구조였다.
A3C는 이 과정을 다음처럼 바꾼다.
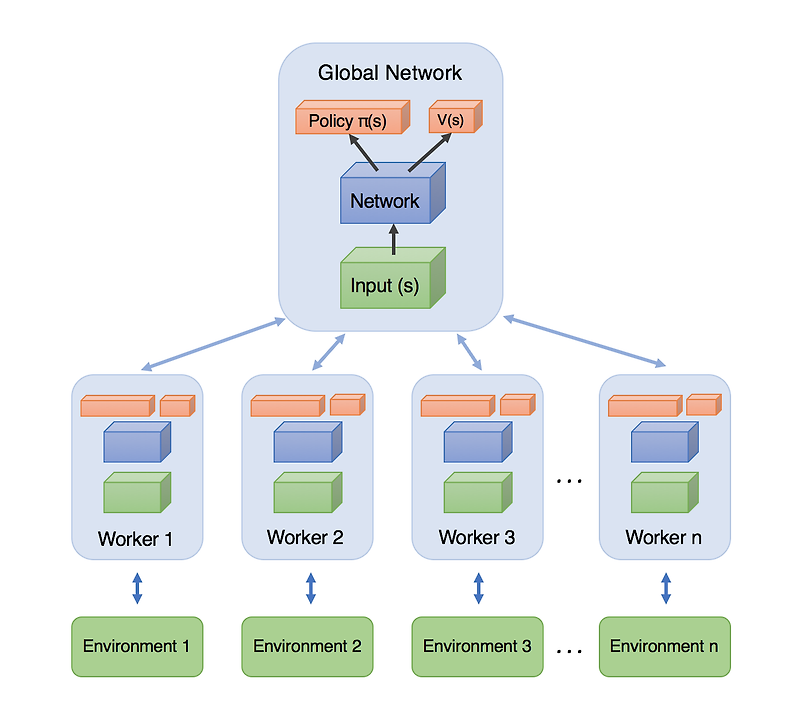
각 Agent는 독립적으로 환경을 탐색하면서 경험을 모은다.
그리고 자신이 모은 경험을 이용해 gradient를 계산한 뒤 중앙 네트워크를 업데이트한다.
즉 하나의 Agent 대신 여러 개의 Agent가 동시에 학습을 진행한다.
이를 쉽게 비유하면 나를 100명으로 복제해서 동시에 학습을 진행해서 학습속도를 빠르게 하는 것이다.
위 방법론으로 해당 논문에서는 총 4가지의 학습 알고리즘을 제시했다.
Asynchronous One-step Q-learning, Asynchronous N-step Q-learning, Asynchronous one-step SARSA, Asynchronous Advantage Actor-Critic 방법론이 바로 그것이다.
이 중 Asynchronous Advantage Actor-Critic이 가장 성능이 높은 대표적인 방법이고,
이것이 앞글자를 때서 AAAC = A3C라 한다.
A3C 학습 구조 (Advantage 기반 방법론)
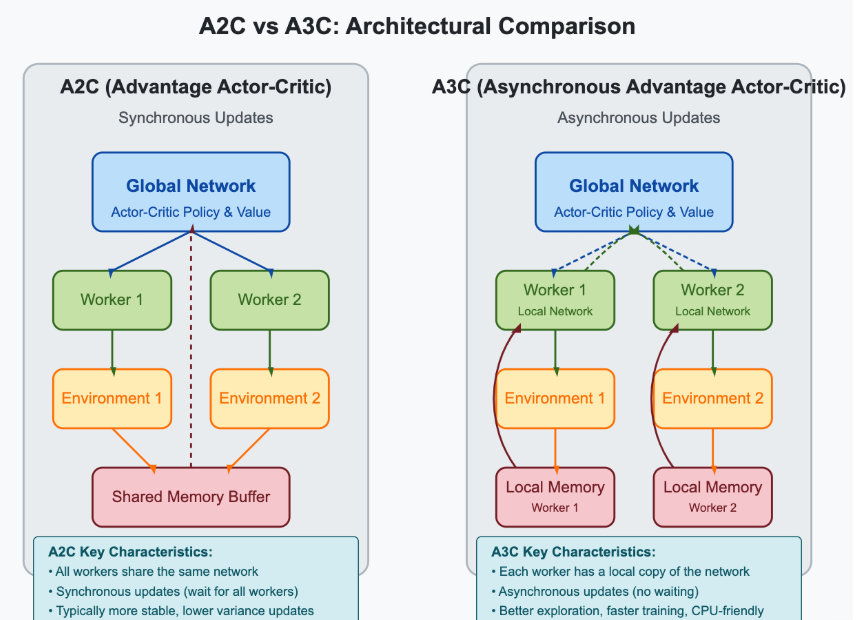
A3C의 이름에서 A (Asynchronous) 는 비동기 학습을 의미한다.
기본적으로 Synchronous 방식은 모든 Agent가 일정 step 동안 경험을 모은다.
그 다음 모든 gradient를 모아서 한 번에 업데이트한다.
즉 서로 동기화된 상태에서 학습이 진행된다.
반면 Asynchronous 방식은 A3C는 동기화하지 않는다.
각 Agent는 경험을 모으고 → gradient 계산 후 → 중앙 네트워크를 바로 업데이트한다.
- 어떤 Agent는 경험을 모으고 있고
- 어떤 Agent는 gradient를 계산하고 있고
- 어떤 Agent는 네트워크를 업데이트하고 있을 수도 있다.
이처럼 각 프로세스가 독립적으로 움직이기 때문에 asynchronous(비동기식)라고 부른다.
A3C에서는 각 학습 프로세스를 Actor-Learner Thread라고 부른다.
각 Thread는 다음 역할을 수행한다.
- 최신 정책 네트워크를 가져온다
- 환경에서 경험을 수집한다
- gradient를 계산한다
- 중앙(Global) 네트워크를 업데이트한다
여기서 중요한 구조가 Global Network인데, 이는 모든 Thread가 공유하는 중앙 모델이다.
각 Thread는 다음 과정을 반복한다.
- Global network 파라미터 복사
- 환경 탐색
- gradient 계산
- global network 업데이트
- 다시 최신 파라미터 가져오기
이 과정을 계속 반복하면서 학습이 진행된다.
Advantage Actor-Critic 기반 알고리즘과 똑같다
A3C는 이름에서 알 수 있듯이 Advantage Actor-Critic 알고리즘을 기반으로 한다.
앞서 Policy Gradient 식은 다음과 같았다.

그리고 이때 Advantage는 TD error로 근사할 수 있다.

따라서 Policy update는 다음과 같이 이루어진다.
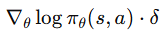
이때 Value 네트워크는 TD learning을 통해 학습된다.

즉 A3C는 기본적으로 Advantage Actor-Critic 구조를 그대로 사용하면서 병렬성만 추가한 알고리즘이다.
N-step TD 사용
A3C에서는 단순한 1-step TD뿐만 아니라 N-step TD를 사용한다.
예를 들어 transition이 다음과 같다고 하자: s0→s1→s2→s3→s4→s5
이때,
- s4 → 1-step TD : 𝛿 = 𝑟 + 𝛾∗𝑉(𝑠′) − 𝑉(𝑠)
- s3 → 2-step TD : 𝛿 = 𝑟 + 𝛾∗𝑟′ + 𝛾^2𝑉(𝑠′′) − 𝑉(𝑠)
- s2 → 3-step TD : : 𝛿 = 𝑟 + 𝛾∗𝑟′ + 𝛾^2∗𝑟′′ + 𝛾^3∗𝑉(𝑠′′′) − 𝑉(𝑠)
와 같이 뒤에서부터 계산한다.
이 방식은 TD 방법의 낮은 variance와 Monte-Carlo 방법의 낮은 bias 사이의 균형을 맞추는 효과가 있다.
Experience Replay 없이도 안정적이고 빠 학습
기존 DQN에서는 Experience Replay Buffer가 필요했다.
그 이유는 다음과 같다.
- 연속된 경험은 서로 강하게 상관되어 있음
- 학습 데이터가 편향될 수 있음
Replay Buffer는 과거 경험을 섞어서 이러한 문제를 해결했다.
하지만 A3C에서는 여러 Agent가 동시에 경험을 수집하기 때문에 자연스럽게 다양한 경험이 생성된다.
즉 여러 환경 탐색이 동시에 이루어지면서 경험 간 상관성이 줄어드는 효과가 생긴다.
그래서 Replay Buffer 없이도 안정적인 학습이 가능하다.
A3C의 가장 큰 장점은 학습 속도 향상이다.
여러 Actor-Learner Thread가 동시에 경험을 수집하기 때문에 경험 수집 속도 증가 및 학습 속도 증가라는 효과가 발생한다.

실제로 논문에서는 CPU 코어 수를 늘릴수록 학습 성능이 거의 선형적으로 증가하는 결과가 나타났다.
또한 Atari 게임 환경에서 DQN, Double DQN, Dueling DQN 등 기존 알고리즘보다 훨씬 높은 성능을 기록했다.
A3C 알고리즘
아래는 Advantage Actor-Critic을 여러 개의 worker가 병렬로 돌리는 구조인 A3C의 pseudocode이다.
핵심은 아주 단순한데,
각 worker가 global network의 최신 parameter를 복사해오고, 자기 환경에서 몇 step 경험을 쌓고,
그 경험으로 gradient를 계산한 뒤, 그 gradient를 global netork에 반영하는 과정을 반복하는 것이다.

1. Global parameter와 thread-specific parameter

맨 위를 보면 다음이 있다.

여기서 의미는 다음과 같다.

즉 중앙의 뇌가 하나 있고, 각 worker는 그 뇌를 복사해서 자기 손에 들고 다니는 구조다.
중앙 파라미터를 매 step 직접 건드리기보다, 일단 로컬 복사본으로 행동하고 각 thread가 환경을 따로 돌면서 경험을 쌓아 gradient를 계산한 뒤 중앙에 반영하는 방식이이다.
2. thread step counter와 global counter

그 다음을 보면 다음과 같다.
- thread step counter t←1
- global shared counter T=0
이것의 의미는 다음과 같다.
- t: 현재 thread가 몇 step 진행했는지 세는 로컬 시간
- : 전체 학습이 총 몇 step 진행됐는지 세는 전역 시간
3. gradient 초기화 및 중앙 파라미터 로컬에 복
반복문 안으로 들어가면 먼저

반복문 안으로 들어가면 먼저 dθ←0, dθv←0를 한다.
이 뜻은 이번 라운드에서 계산할 gradient를 0으로 초기화하겠다는 뜻이다.
즉 지금부터 몇 step 경험을 모으고, 그 경험들로 policy gradient와 value gradient를 누적해서 계산하겠다는 의미다.
그 다음으로 중앙에 있는 최신 파라미터를 각 thread의 로컬 파라미터로 복사한다. (θ′=θ, θv′=θv)
worker는 항상 최신 정책으로 경험을 쌓는 것이 가장 바람직하기 때문에 경험을 모으기 직전에 중앙의 최신 네트워크를 받아온다.
4. 경험 수집 시작점 저장 (t_start) 및 state를 받고 rollout 수행

그 다음 t_{start} = t를 설정한다.
이건 이번에 경험을 쌓기 시작한 시점을 기억해두겠다는 뜻이다.
왜 필요하냐면 이 thread가 이번 라운드에서 최대 t_{max}까지만 경험을 모으기로 했기 때문이다.
그래서 현재 시작 시점을 저장해두고, t - t_{start} == t_{max}가 되면 경험 수집을 멈춘다.
예를 들어 t_{max}=5라면 최대 5 step만 모으겠다는 뜻이다.
이후 이제 실제로 환경과 상호작용한다.
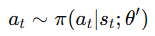
즉 현재 상태 s_t에서 로컬 policy πθ′를 이용해 action을 샘플링한다.
그리고 환경에 그 action을 실제로 넣으면 reward r_t와 다음 상태 s_{t+1}을 받는다.
이걸 반복하면서 로컬 시간과 전역 시간을 모두 1 증가시킨다. (
5. t_{max} step만 모으고 R 초기화

이 경험 수집은 언제까지 하냐면 아래 조건 중 하나를 만족할 때까지 한다.
- terminal state에 도달할 때까지
- t - t_{start} == t_{max}가 될 때까지
즉 “에피소드가 끝나거나, 아니면 정해진 step 수만큼만 모으겠다”는 것이다.
이때 t_{max} step만 모으는 이유는 무엇일까?
A3C는 episode가 완전히 끝날 때까지 기다리지 않고, 짧은 rollout 단위로 gradient를 계산한다.
예를 들어 5 step만 모으고도 업데이트할 수 있다.
이렇게 하면 다음과 같은 이점이 있다.
- 업데이트가 더 자주 일어나고
- 병렬 worker들이 더 빠르게 중앙 파라미터를 밀어줄 수 있고
- 완전한 Monte Carlo보다 variance를 줄일 수 있다
즉 REINFORCE처럼 episode 끝까지 기다리는 것이 아니라, n-step bootstrap을 이용해 더 자주 업데이트하는 구조다.
경험 수집이 끝나면 바로 gradient를 계산하는데, 먼저 RR을 초기화한다.
pseudocode에서는 다음과 같다.

이게 무슨 뜻이냐면, rollout이 끝난 마지막 지점에서 future return의 시작값을 정하는 것이다.
terminal인 경우 에피소드가 끝나서 그 뒤 미래 보상은 없으니
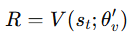
즉 “여기 이후의 미래 보상은 일단 현재 value network가 예측한 값으로 대신하자”는 뜻이다.
이게 A3C의 핵심 중 하나다. Monte Carlo처럼 끝까지 가지 않고, 마지막 state의 value를 이용해 이어붙인다.
6. 뒤에서부터 return 계산 후 Policy Gradient 계산 → Value network gradient 계

이제 for loop가 나온다.
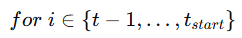
즉 마지막 step부터 시작해서 처음 step 방향으로 거꾸로 간다.
그리고 매 step마다 R을 업데이트한다.
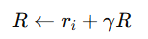
이 식은 REINFORCE에서 return을 뒤에서부터 계산하던 것과 완전히 같은 아이디어다.
예를 들어 rollout이 5 step이고 마지막 bootstrap value가 이미 R에 들어있다면,
- 맨 마지막 reward를 더해 one-step target을 만들고
- 그걸 다시 이전 step으로 넘겨 two-step target을 만들고
- 또 넘겨 three-step target을 만든다
이런 식으로 뒤에서부터 계산하면 자연스럽게 n-step return이 만들어진다.
즉 이 RR은 단순히 하나의 숫자가 아니라, 현재 시점 s_i에서 본 미래 return target이 된다.
이제 policy network의 gradient를 누적한다.

위 식은 Advantage Actor-Critic과 동일한데, 여기서 R - V가 advantage 역할을 한다.
R은 현재 시점에서의 미래 return target이고, V(s_i)는 현재 상태의 baseline으로,
이 둘의 차이는 “이 행동을 해서 얻은 결과가, 이 상태의 평균적인 기대값보다 얼마나 더 좋았는가?”를 나타낸다.
- R - V(s_i)가 양수면: 생각보다 좋은 결과였다 → 그 action의 log 확률을 올린다
- R - V(s_i)가 음수면: 생각보다 나쁜 결과였다 → 그 action의 log 확률을 내린다
즉 Advantage Actor-Critic의 업데이트를 rollout 구간 전체에 대해 뒤에서부터 계산하는 것이다.
그 다음 줄은 value network 업데이트다.

이 부분은 target R과 현재 value prediction V(s_i)의 차이를 줄이도록 value network를 학습하는 것이다.
정리하면 아래와 같다.
- policy network는 advantage로 학습
- value network는 squared error loss로 학습
이제 누적한 gradient를 가지고 중앙 파라미터를 업데이트한다.

즉 각 thread가 자기 경험으로 계산한 gradient를 글로벌 파라미터에 반영한다.
그리고 다시 처음으로 돌아가서 중앙 파라미터를 복사하고 → 경험을 쌓고 → gradient를 계산하고 → 중앙에 반영하는 과정을 반복하는 것이 바로 asynchronous update다.
왜 A3C가 잘 작동하는가
이 알고리즘이 강력한 이유는 세 가지다.
- 여러 worker가 동시에 경험을 쌓으므로 데이터 수집 속도가 빠르다.
- 서로 다른 worker들이 각자 다른 trajectory를 경험하므로 데이터의 decorrelation 효과가 있다. DQN에서 replay buffer가 하던 역할 일부를 병렬 경험이 대신해준다.
- full Monte Carlo가 아니라 n-step bootstrap을 쓰므로 bias와 variance 사이의 절충이 가능하다.
A3C의 한계: Off-Policy 문제
하지만 A3C에는 한 가지 문제가 있다.
각 Thread는 최신 네트워크를 복사한 뒤 경험을 모은다.
그런데 그 사이에 다른 Thread가 네트워크를 업데이트할 수 있다.
예를 들어 Thread가 θ₁ 파라미터로 경험을 수집했는데 그 사이에 Global Network가 θ₂, θ₃, θ₄로 업데이트될 수 있다.
그러면 Thread는 θ₁ 기준으로 계산된 gradient를 θ₄ 네트워크에 적용하게 된다.
이렇게 되면 학습이 Off-Policy 형태가 된다.
하나의 CPU에서 16, 32 Core를 사용하는 것처럼 Thread 수가 적을 때는 문제가 크지 않지만
수백 대의 컴퓨터를 연결해 1000개가 넘어가는 Thread처럼 병렬성이 매우 커지면 학습이 불안정해질 수 있다.
그래서 이후 연구에서는 이를 보정하는 알고리즘인 ACER, IMPALA (V-trace)가 등장했다.
'딥러닝 모델 > DQN for Cloud-Edge Caching' 카테고리의 다른 글
| Edge–Cloud 패러다임에서의 Offloading의 개념 (0) | 2026.03.12 |
|---|---|
| [강화학습 기초 13] Proximal Policy Optimization (PPO) (0) | 2026.03.11 |
| [강화학습 기초 11] Actor-Critic 알고리즘 총정리 (Q, Advantage, TD) (0) | 2026.03.09 |
| [강화학습 기초 10] Policy Gradient와 REINFORCE 알고리즘 구현 (0) | 2026.03.04 |
| [강화학습 기초 9] Policy 기반 강화학습과 Policy Gradient 이론 (Value 기반 vs Policy 기반) (0) | 2026.03.04 |