지금까지 우리는 강화학습에서 Value Function을 딥러닝으로 근사하는 방법을 중심으로 살펴보았다.
여기서는 딥러닝을 활용하여 Value Function을 근사함하여 Agent가 상태의 가치를 추정하고 행동을 선택할 수 있었다.
이러한 접근 방식은 일반적으로 Value 기반 강화학습(Value-based Reinforcement Learning)이라 불린다.
Value 기반 강화학습의 대표적인 예는 다음과 같았다.
- Value Function을 학습하는 Value Network
- Action Value Function을 학습하는 Q Network
- Bellman Optimality Equation을 이용한 Q-Learning
- Deep Learning과 결합한 Deep Q-Learning (DQN)
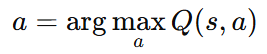
이 중 Q-Learning에서는 최적의 Action Value Function Q를 직접 학습함으로서 policy를 명시적으로 정의하지 않고도 가장 좋은 행동을 선택할 수 있다.
그러나 우리가 직접 Policy를 정의해서 Policy 자체를 뉴럴넷으로 표현하거나, Policy를 직접 학습하는 방식이 더 유효할 때가 있다.
이를 Value Function을 거치지 않고 정책 자체를 학습하는 Policy-based Reinforcement Learning 이라고 한다.
정책 (Policy) 기반의 뉴럴 네트워크
정책 기반 Agent는 왜 필요한가?
실제 문제에서는 정책 기반 접근이 반드시 필요한 상황이 존재한다. 대표적으로 두 가지 경우가 있다.

1. 확률적인 Action이 필요한 경우
Value 기반 Agent는 기본적으로 다음과 같은 행동 선택 방식을 사용한다.

즉, Value 기반 Agent는 항상 가장 높은 value를 가지는 행동을 선택한다.
이 방식의 특징은 다음과 같다.
- 동일한 상태에서는 항상 동일한 행동을 선택한다.
- policy가 deterministic하다.
예를 들어 가위바위보를 하는 환경을 생각해보자.
이 경우 가위/바위/보 중 3개의 Action을 선택할 수 있지만,
Value 기반 Agent는 특정 상태에서 항상 가위, 혹은 항상 바위, 혹은 항상 보를 선택한다.
즉 항상 동일한 행동만 선택하는 deterministic policy가 되는 셈이다.
하지만 실제로는 다음과 같은 정책이 더 바람직할 수 있다.
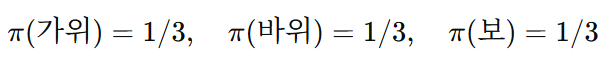
즉 확률적으로 행동을 선택하는 stochastic policy이다.
이처럼 행동을 확률적으로 선택해야 하는 문제에서는 Value 기반 방법만으로는 정책을 표현하기 어렵다.
이때 정책 기반 Agent가 필요하다.
2. Action Space가 Continuous한 경우
두 번째로 정책 기반 접근이 필요한 상황은 Action Space가 Continuous한 경우이다.
예를 들어 행동이 다음과 같은 값이라고 가정해보자.

즉 행동이 0과 1 사이의 연속적인 실수값이다.
Value 기반 접근에서는 다음과 같은 문제를 해결해야 한다.

하지만 이 문제는 단순한 선택 문제가 아니라 연속 공간에서의 최적화 문제가 되기 때문에 다음과 같은 어려움이 발생한다.
- 가능한 action이 무한하다.
- 어떤 action이 Q-value를 최대화하는지 찾기 어렵다.
- 매 step마다 최적화 문제를 풀어야 한다.
반면 정책 기반 방법에서는 policy를 다음과 같이 표현한다.
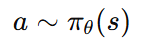
이 식의 의미는 곧 상태 s가 주어지면 정책 네트워크 π_θ가 행동 a를 만들어낸다는 뜻이다.
즉 행동을 선택하기 위해 따로 최적화를 할 필요가 없이 Policy network a = 0.37과 같이 행동을 출력한다.
따라서 Agent는
- 상태 s를 policy network에 입력하고
- 출력된 행동 a를 그대로 환경에 적용하면 된다.
즉 가능한 action을 탐색하거나 최적의 action을 계산할 필요 없이 policy network가 생성한 행동을 그대로 사용하면 된다.
Policy Network의 표현 : 𝜋_𝜃(𝑠)
정책 기반 강화학습에서는 policy를 다음과 같이 표현한다.

여기서 의미는 다음과 같다.
- π : policy
- θ : policy를 구성하는 파라미터
- π_ : 파라미터화된 policy
즉 policy 자체를 Neural Network로 표현한 것이다.

이때 입력은 상태 s, 출력은 행동에 대한 확률 분포 또는 행동 값이 된다.
예를 들어 action이 3개라면 policy network는 다음과 같은 확률을 출력할 수 있다.
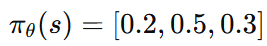
Policy Network는 어떻게 학습할까?
딥러닝에서 모델을 학습하려면 반드시 Loss Function이 필요하다.
일반적인 지도학습에서는 다음과 같이 loss를 정의한다: Loss = 정답 - 예측값
하지만 강화학습에서는 상황이 좀 다른데, 우리가 정답 Policy가 무엇인지를 모른다는 것이다.
따라서 정책 기반 강화학습에서는 정답 policy 없이 학습할 수 있는 목적함수(Objective Function)를 정의해야 한다.
그렇다면 Loss를 정의하기 위해 우리가 실제로 원하는 것이 무엇인지를 목적 함수로 정의해보자.
강화학습에서 궁극적인 목표는 단순히 리워드를 많이 받는 것이다.
이를 좀 더 정확히 말하면 리턴(Return)의 기댓값이 크도록 하는 것이다.
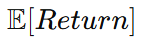
Return의 기댓값이라고 표현하는 이유는 policy가 확률적으로 행동을 선택하므로 다음이 모두 확률적으로 결정되기 때문이다.
- 어떤 action이 선택되는지
- 환경이 어떻게 반응하는지
- 어떤 trajectory가 만들어지는지
따라서 리턴 역시 확률 변수가 된다.
이 값을 policy 파라미터 에 대한 함수로 표현하면 다음과 같이 정의할 수 있다.
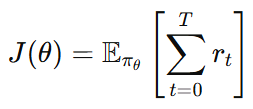
각각의 기호는 다음을 의미한다.
- π_θ: 현재 policy
- r_t : 시점 t에서의 reward
즉, 우리의 목적함수는 현재 policy(π_θ)로 경험을 쌓았을 때 얻는 총 reward(r_t)의 기댓값를 의미한다.
그런데 이는 사실 초기 상태에서의 Value와 같은 의미를 가진다.
따라서 이 값은 또 다른 관점에서 다음과 같이 해석할 수 있다.

즉 우리의 목적함수 초기 상태의 Value와 동일하다.
결국 정책 기반 강화학습의 목표는 다음과 같다.
현재 policy를 사용했을 때 처음 상태에서 기대되는 총 reward 최대화하는 policy를 찾는 것
Policy Gradient Theorem
지금까지 우리는 다음을 정의했다.
- policy network 𝜋_𝜃(𝑠)
- 목적함수 J(𝜃)
이제 남은 질문은 하나다.
어떻게 J(θ)를 최대화할 것인가?
이를 해결하는 핵심 이론이 바로 Policy Gradient Theorem이다.
Gradient Ascent로 J(𝜃)를 최대화하기
딥러닝에서 어떤 값을 최대화하고 싶다면 Gradient Ascent를 사용한다.
일반적인 파라미터 업데이트 식은 다음과 같다.


보통 지금까지의 딥러닝에서는 Gradient Descent를 사용했다.
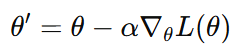
이는 Loss를 최소화하기 때문이다.
하지만 강화학습에서는 Reward를 최대화해야 하므로 Gradient Ascent를 활용해 Gradient 방향으로 파라미터를 이동시킨다.
Policy Gradient를 계산하기 어려운 이
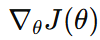
를 어떻게 계산할 것인가?
이것이 바로 Policy Gradient 문제다.
목적함수 J(θ)를 조금 더 풀어보면 다음과 같이 표현할 수 있다.


이때 Value는 다음과 같이 표현될 수 있다.

이 두 식을 합치면 다음과 같이 표현된다.

문제는 여기서 Gradient를 구하려고 하면 발생한다.
이 식을 그대로 계산하려면 모든 상태 든 행동 a에 대해 계산해야 한다.
하지만 현실의 문제에서는 상태 공간이 매우 크고 행동 공간도 크다.
따라서 이 식을 직접 계산하는 것은 사실상 불가능하다.
Policy Gradient Theorem의 핵심 : Log Trick
Policy Gradient Theorem의 핵심은 다음 변형이다.

이 식을 이용하면 gradient를 다음과 같이 바꿀 수 있다.

<유도과정>
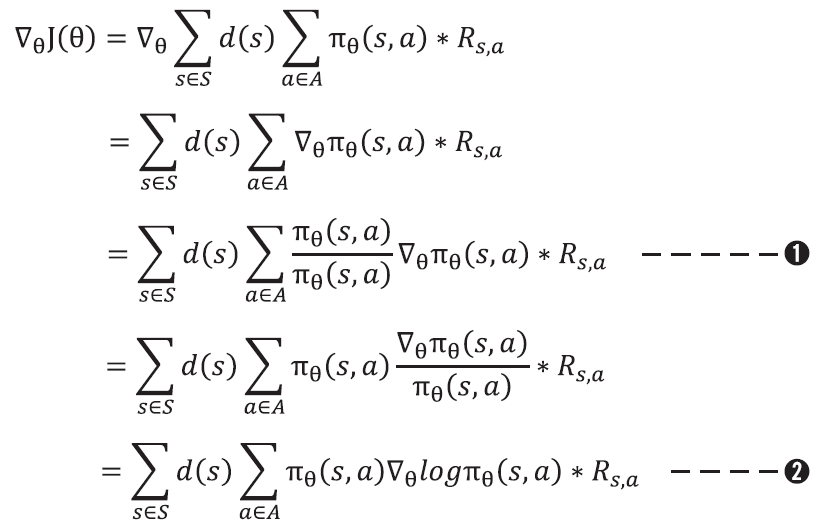

이 식이 중요한 이유 : Sample 기반 방법론을 가능하게 한다

위 식을 보면 두 개의 시그마(Σ)가 있다.
- 첫 번째 시그마는 ∑d(s)로, 이는 상태가 나타날 확률을 의미한다. (= 상태가 등장할 확률만큼 weighted sum)
- 두 번째 시그마는 ∑πθ(s,a)로, 이는 상태 s에서 행동 a를 선택할 확률이다. (= policy에 따라 행동을 선택했으 때의 평균)
이 식은 사실 다음 의미와 같다.
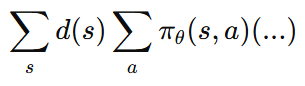
policy를 따라 상태와 행동을 샘플링했을 때의 평균
즉 수학적으로는 다음과 같이 쓸 수 있다.

그래서 첫 번째 식 다음처럼 바꿀 수 있다.


즉, 정리하면 처음 식은 모든 상태와 모든 행동에 대해 계산해야 한다.
하지만 현실에서는 상태 수가 매우 많고 행동 수도 많아 이 계산을 직접 할 수 없다.
하지만 expectation 형태로 바꾸면 이야기가 달라진다.
우리는 이제 이렇게 할 수 있다.
- 현재 policy πθ로 행동을 선택한다
- 환경에서 reward를 얻는다
- 그 값으로 gradient를 계산한다
즉, policy로 실제 경험을 샘플링해서 gradient를 근사할 수 있다.
따라서 직관적으로 보면 아래 식은 다음과 같은 의미를 가진다.

- reward가 크면
→ 그 행동의 확률을 높인다 - reward가 작으면
→ 그 행동의 확률을 낮춘다
이는 곧 다음을 뜻한다.
좋은 행동은 더 자주 선택하게 만들고
나쁜 행동은 덜 선택하게 만드는 학습 규칙
한 줄로 요약하면 Policy Gradient Theorem의 핵심은 다음과 같다.
모든 state와 action을 계산하는 대신, policy로 샘플링한 경험만으로 gradient를 계산할 수 있게 만든다.
'딥러닝 모델 > DQN for Cloud-Edge Caching' 카테고리의 다른 글
| [강화학습 기초 11] Actor-Critic 알고리즘 총정리 (Q, Advantage, TD) (0) | 2026.03.09 |
|---|---|
| [강화학습 기초 10] Policy Gradient와 REINFORCE 알고리즘 구현 (0) | 2026.03.04 |
| [강화학습 기초 8] 딥마인드 DQN의 구조와 학습 테크닉 (Replay Buffer, Target Network) (0) | 2026.03.03 |
| [강화학습 기초 7] Deep Reinforcement Learning의 핵심 (Value Network와 Deep-Q Learning) (0) | 2026.03.03 |
| [강화학습 기초 6] Temporal Difference를 통한 step 기반 가치 평가 (MDP를 모를 때) (0) | 2026.03.03 |