Actor-Critic 알고리즘
앞선 챕터에서는 Policy Gradient Theorem과 이를 실제 학습 알고리즘으로 구현한 REINFORCE 알고리즘을 살펴보았다. REINFORCE는 정책(policy)을 직접 학습하는 매우 직관적인 방법이지만, 한 가지 단점이 있다.
바로 Return을 이용한 평가가 분산(variance)이 크다는 점이다.
이러한 문제를 완화하기 위해 등장한 Actor-Critic 알고리즘이다.
Actor-Critic은 정책을 학습하는 네트워크와 행동의 가치를 평가하는 네트워크를 동시에 학습하는 구조를 가진다.
이를 통해 정책 업데이트를 보다 안정적으로 수행할 수 있다.
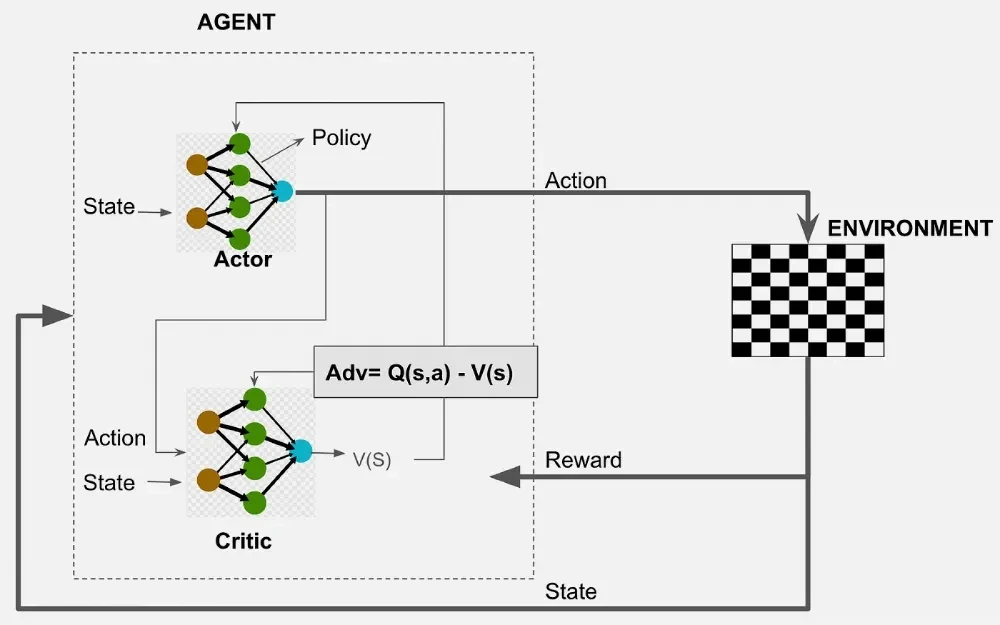
Actor-Critic 알고리즘의 핵심 아이디어
REINFORCE 알고리즘에서는 다음과 같은 정책 업데이트가 이루어졌다.
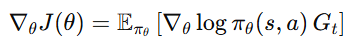
여기서 G_t는 Return이다. 즉, 한 에피소드가 끝난 뒤에 얻은 누적 보상을 이용해 정책을 업데이트했다.
하지만 Return은 에피소드가 끝나야 계산할 수 있고, 값의 변동도 크다.
그래서 Actor-Critic에서는 Return 대신 Value Function을 이용해 행동의 가치를 평가한다.
이를 다시 Policy Gradient 형태로 쓰면 다음과 같다.
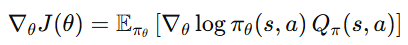
문제는 Q값을 우리는 알 수 없다는 것이다.
어떤 policy에서 특정 상태와 행동의 미래 가치를 정확히 계산하는 것은 일반적으로 불가능하다.
그래서 Q Actor-Critic에서는 Q값 자체를 뉴럴 네트워크로 근사한다.
이때 Actor-Critic 계열 알고리즘은 이 Q 대신 어떤 값을 사용하느냐에 따라 여러 종류로 나뉜다.
Actor Critic 알고리즘의 종류
Actor-Critic 계열 알고리즘은 크게 다음 세 가지로 나눌 수 있다.
- Q Actor-Critic
- Advantage Actor-Critic
- TD Actor-Critic
세 알고리즘의 차이는 Policy Gradient 식에서 Q 대신 어떤 값이 들어가는지에 있다.
| 알고리즘 | 사용되는 값 |
| Q Actor-Critic | Q(s,a) |
| Advantage Actor-Critic | A(s,a) |
| TD Actor-Critic | TD Error |
Actor와 Critic의 역할
Actor-Critic 구조에서는 두 개의 네트워크가 등장한다.

- Actor (파라미터 : θ)
- 정책을 학습하는 네트워크
- 현재 상태에서 어떤 행동을 선택할 확률을 출력한다.

- Critic (파라미터 : w)
- 행동의 가치를 평가하는 네트워크
- 상태 s에서 행동 a를 했을 때 기대되는 미래 보상의 크기를 예측한다.
이때 Actor와 Critic의 역할은 다음과 같다.
- Actor : 행동을 선택한다
- Critic : 그 행동이 얼마나 좋은지 평가한다
이 두 네트워크가 서로 협력하면서 학습이 진행된다.
Q Actor-Critic
Q Actor-Critic은 앞서 배운 Policy Gradient Theorem과 매우 유사하다.
이때, Q 함수를 우리가 알 수 없기 때문에 이를 뉴럴넷으로 근사한다.
이후 Q값을 업데이트나가는데, 처음에는 랜덤한 값이 나오다가 Q가 학습됨에 따라 이 업데이트도 점점 정확해진다.
Q Actor-Critic의 학습 구조
Q Actor-Critic의 핵심은 두 네트워크가 번갈아가며 학습된다는 점이다.
학습 과정은 다음과 같이 진행된다.
Actor 파라미터 θ 와 Critic 파라미터 w 초기화 후 다음을 반복
- Actor가 행동을 선택한다. 𝑎 ~ 𝜋𝜃(𝑠)
- 환경에서 보상과 다음 상태를 얻는다. 𝑟, 𝑠′ 관측
- Critic이 해당 행동의 가치를 평가한다.
- Actor는 Critic의 평가를 이용해 정책(θ)을 업데이트한다. 𝑙𝑜𝑠𝑠 = −𝑙𝑜𝑔𝜋𝜃(𝑠, 𝑎) * 𝑄𝑤(𝑠, 𝑎)
- 다음 행동 선택 𝑎′ ~ 𝜋𝜃(𝑠′)
- Critic은 TD learning을 통해 자신의 Q값 예측(w)을 개선한다. 𝑙𝑜𝑠𝑠 = [𝑟 + γ ∗ 𝑄𝑤 (𝑠′, 𝑎′) − 𝑄𝑤(𝑠, 𝑎)]^2
| 항목 | 의미 | 출처 |
| r | 실제 reward | 환경 |
| s' | 다음 상태 | 환경 |
| Qw(s,a) | 현재 Q값 추정 | Critic 뉴럴넷 |
| Qw(s',a') | 다음 상태 Q값 추정 | Critic 뉴럴넷 |
Advantage Actor-Critic
앞에서 Q Actor-Critic을 통해 Actor와 Critic 두 개의 네트워크를 함께 학습하는 구조를 살펴보았다.
Actor는 정책을 학습하고, Critic은 행동의 가치를 평가하는 Q function을 학습했다.
Actor는 Critic이 예측한 Q값을 이용해 정책을 업데이트하였다.
하지만 Q Actor-Critic에는 한 가지 비효율적인 상황이 존재한다.
알고리즘이 틀린 것은 아니지만, 정책을 업데이트하는 방식이 항상 효율적인 것은 아니다.
이러한 문제를 해결하기 위해 등장한 방법이 Advantage Actor-Critic이다.
Q Actor-Critic의 비효율적인 상황
예를 들어 어떤 상태 s′가 매우 좋은 상태라고 가정해보자.
이 상태에서는 어떤 행동을 하더라도 높은 보상을 얻을 수 있다고 하자.
예를 들어 가능한 행동이 두 개라고 하자.
| 행동 | Q value |
| (a0) | 5000 |
| (a1) | 5500 |
이 경우 두 행동 모두 매우 좋은 행동이다. 하지만 a1이 조금 더 좋은 행동이다.
우리가 원하는 것은 다음과 같다.
- a1의 확률은 증가
- a0의 확률은 감소
즉 두 행동의 차이를 학습하는 것이 중요하다.
하지만 Q Actor-Critic에서는 정책 업데이트가 다음과 같이 이루어진다.

이 경우
- a0 → Q = 5000
- a1 → Q = 5500
둘 다 매우 큰 값이기 때문에 두 행동의 확률이 둘 다 크게 증가하는 방향으로 업데이트된다.
이 경우 a0와 a1의 차이를 학습하기 위해서는 매우 많은 샘플을 필요로 한다.
즉 두 행동의 차이를 제대로 반영하지 못해 비효율적이다.
Advantage의 아이디어
이 문제를 해결하는 방법은 매우 직관적이다.
행동의 가치를 절대적인 값(Q)으로 평가하지 않고 해당 상태의 평균 가치와 비교하는 것이다.
이를 위해 다음 값을 Advantage로 정의한다.
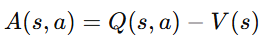

즉 Advantage는 "이 행동이 평균적인 행동보다 얼마나 더 좋은가?" 에 대한 답이다.
앞에서 사용한 예시로 살펴보면, 상태 s'에서 a0의 Q value는 5000, a1의 Q value는 5500이었다.
그렇다면 이 상태의 평균 value는 V(s') = (5000 + 5500) / 2 = 5250이 된다.
그럼 Advantage는 a0의 경우 -250, a1의 경우 250으로 계산된다.
이제 의미가 명확해진다.
- a1 → 평균보다 좋은 행동 → 확률 증가
- a0 → 평균보다 나쁜 행동 → 확률 감소
즉 행동 간의 차이가 훨씬 명확하게 드러난다.
따라서 기존의 Policy Gradient Theorem과 Advantage Actor-Critic을 비교하면 다음과 같다.

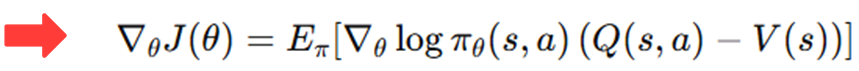
Q(s, a) 대신 Q(s, a) - V(s)를 넣어도 되는 이유
그런데 Q − V를 이렇게 막 빼도 되는걸까? Q에서 값을 하나 빼면 gradient가 바뀌는 거 아닐까?
이것이 가능한 이유는 Policy Gradient에서 state에만 의존하는 값은 빼도 gradient가 변하지 않는다는 성질 때문이다.
olicy Gradient 식을 다음처럼 나눌 수 있다.

그런데 여기서 중요한 성질이 있다.

왜 0이냐면, 모든 action의 확률을 더하면 항상 1이 나오기 때문이다.
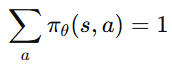
따라서 다음이 성립한다.



결국 state에만 의존하는 값을 빼도 gradient는 변하지 않는다.
따라서 아래와 같이 바꿀 수 있고, Q-V를 Advantage라고 한다.
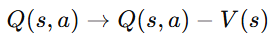
따라서 최종적으로 다음과 같은 식을 얻는다.
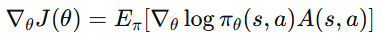
Advantage Actor-Critic의 학습 구조
Advantage Actor-Critic을 실제로 학습하려면 총 세 개의 뉴럴 네트워크가 필요하다.
첫 번째는 행동을 선택하는 정책 함수 πθ(s,a) 네트워크이고,
두 번째는 상태와 행동의 가치를 예측하는 액션-가치 함수 Qw(s,a) 네트워크이다.
마지막으로 상태 자체의 가치를 예측하는 상태-가치 함수 Vφ(s) 네트워크가 필요하다.
여기서 θ, w, φ는 각각의 네트워크 파라미터를 의미한다.
학습 과정은 다음과 같이 진행된다.
Actor 파라미터 θ, Q Critic 파라미터 w, Value Critic 파라미터 φ 초기화 후 다음을 반복한다.
- Actor가 행동을 선택한다. 𝑎 ~ 𝜋𝜃(𝑠)
- 환경에서 보상과 다음 상태를 얻는다. 𝑟, 𝑠′ 관측
- Critic이 해당 행동의 가치를 평가한다.
- Actor는 Critic의 평가를 이용해 정책(θ)을 업데이트한다. 𝑙𝑜𝑠𝑠 = −𝑙𝑜𝑔𝜋𝜃(𝑠, 𝑎) ∗ {𝑄𝑤(𝑠, 𝑎) − 𝑉𝜙(𝑠)}
- 다음 행동 선택 𝑎′ ~ 𝜋𝜃(𝑠′)
- Q Critic은 TD learning을 통해 자신의 Q값 예측(w)을 개선한다. 𝑙𝑜𝑠𝑠 = [𝑟 + γ ∗ 𝑄𝑤 (𝑠′, 𝑎′) − 𝑄𝑤(𝑠, 𝑎)]^2
- Value Critic은 TD learning을 통해 상태 가치(φ)를 학습한다. 𝑙𝑜𝑠𝑠 = [𝑟 + γ ∗ 𝑉𝜙(𝑠′) − 𝑉𝜙(𝑠)]^2
| 항목 | 의미 | 출처 |
| r | 실제 reward | 환경 |
| s' | 다음 상태 | 환경 |
| Qw(s,a) | 현재 Q값 추정 | Q Critic 뉴럴넷 |
| Qw(s',a') | 다음 상태 Q값 추정 | Q Critic 뉴럴넷 |
| Vφ(s) | 현재 상태 가치 추정 | Value Critic 뉴럴넷 |
| Vφ(s') | 다음 상태 가치 추정 | Value Critic 뉴럴넷 |
| Qw(s,a) − Vφ(s) | Advantage | 두 Critic의 차이 |
TD Actor-Critic
Advantage Actor Critic의 단점
Advantage Actor-Critic은 Q Actor-Critic의 비효율적인 업데이트 문제를 해결하기 위해 등장한 방법이다.
하지만 Advantage Actor-Critic에도 단점이 존재한다. 이 방법을 실제로 구현하려면 다음 세 가지 함수를 모두 근사해야 한다.
- 정책 함수 πθ(s,a)
- 액션-가치 함수 Qw(s,a)
- 상태-가치 함수 Vϕ(s)
즉 총 세 개의 뉴럴 네트워크가 필요하다.
네트워크 수가 많아질수록 학습 구조가 복잡해지고 계산 비용도 증가하게 된다.
또한 Q와 V 두 가치 함수를 동시에 학습해야 하므로 구현 난이도 역시 높아진다.
TD Actor-Critic이 효과적인 이유
TD Actor-Critic은 Advantage Actor-Critic의 이러한 단점을 해결하기 위해 등장한 방법이다.
핵심 아이디어는 Q 함수를 직접 학습하지 않아도 Advantage를 계산할 수 있다는 점이다.
이를 이해하기 위해 상태 가치 함수 V(s)의 TD error를 생각해보자.


이 TD target과 V(s)의 차이가 바로 TD error(δ)이다.
TD error(δ)의 기댓값을 계산해보면 다음과 같은 관계가 성립한다.
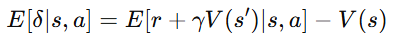
여기서 중요한 점은 보상과 다음 상태 가치의 기댓값이 결국 Q value라는 점이다.
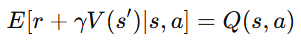
따라서 위 수식은 다음과 같이 정리된다. (V 자체가 기댓값이니 V의 Expectation은 V)

즉, TD error(δ)의 기댓값이 곧 Advante와 같다는 결론에 이르게 된다.

이 의미는 다음과 같다.
- TD error(δ) 자체는 정확한 Advantage 값은 아니다.
- 하지만 그 기대값이 Advantage와 동일하다.
이를 직관적으로 보면 다음과 같다.
- A(s,a) : 행동의 진짜 Advantage
- δ : 실제 transition에서 얻은 Advantage의 샘플
이 구조는 REINFORCE에서 보았던 상황과 완전히 동일하다.
- Q(s,a) : 상태 s에서 행동 를 했을 때 얻는 미래 return의 기댓값
- G_t : 실제 에피소드에서 얻은 return의 샘플 (Q(s,a)의 샘플)
따라서 Policy Gradient 식에서 Advantage 대신 δ를 넣어도 기댓값은 동일하게 유지된다.
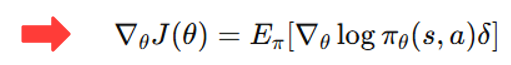
이 방법의 가장 큰 장점은 Q 네트워크가 더 이상 필요 없다는 점이다.
Advantage Actor-Critic에서는 정책, Q 함수, V 함수 총 세 개의 네트워크가 필요했지만,
TD Actor-Critic에서는 다음 두 개의 네트워크만 있으면 된다.
- 정책 네트워크 πθ(s,a)
- 상태 가치 네트워크 Vϕ(s)
즉 Advantage 계산을 위해 Q를 직접 학습할 필요가 없고, V만으로도 Advantage의 샘플을 얻을 수 있다.
때문에 TD Actor-Critic은 Advantage Actor-Critic과 동일한 효과를 유지하면서도 네트워크 구조를 단순화하고 계산 효율을 크게 향상시킨다. 이러한 이유로 TD Actor-Critic은 Actor-Critic 계열 알고리즘에서 매우 중요한 발전 단계로 볼 수 있다.
TD Actor Critic의 학습 구조
- Actor 파라미터 θ, Value Critic 파라미터 ϕ 초기화 후 다음을 반복한다.
- Actor가 행동을 선택한다. 𝑎 ~ 𝜋𝜃(𝑠)
- 환경에서 보상과 다음 상태를 얻는다. 𝑟, 𝑠′ 관측
- TD error δ를 계산한다. 𝛿 = 𝑟 + γ ∗ 𝑉𝜙(𝑠′) − 𝑉𝜙(𝑠)
- Actor는 TD error를 이용해 정책(θ)을 업데이트한다. 𝑙𝑜𝑠𝑠 = −𝑙𝑜𝑔𝜋𝜃(𝑠,𝑎) * 𝛿 (Advantage 자리에 δ - 샘플 역할을 하는 숫자)
- Value Critic은 TD learning을 통해 상태 가치 Vϕ를 학습한다. 𝑙𝑜𝑠𝑠 = [𝑟 + γ ∗ 𝑉𝜙(𝑠′) − 𝑉𝜙(𝑠)]^2
정리하면 TD Actor-Critic에서는 다음 두 단계가 반복된다.
- 정책 업데이트 (Actor) - policy 업데이트 1번
- 상태 가치 업데이트 (Critic) - value 업데이트 1번
| 항목 | 의미 | 출처 |
| r | 실제 reward | 환경 |
| s' | 다음 상태 | 환경 |
| Vφ(s) | 현재 상태 가치 추정 | Value Critic 뉴럴넷 |
| Vφ(s') | 다음 상태 가치 추정 | Value Critic 뉴럴넷 |
| δ | TD error (Advantage의 샘플) | Value 함수 계산 |
TD Actor-Critic 코드
1. 네트워크 구조
TD Actor-Critic에서는 정책 함수 πθ\pi_\theta와 상태 가치 함수 VϕV_\phi 두 개의 네트워크가 필요하다.
이 코드에서는 두 네트워크의 **초기 feature extraction 부분을 공유(shared layer)**하도록 구성되어 있다.
self.fc1 = nn.Linear(4,256)
self.fc_pi = nn.Linear(256,2)
self.fc_v = nn.Linear(256,1)
구조는 입력 상태 → 공통 hidden layer → 정책 네트워크 / 가치 네트워크 분기의 형태이다.
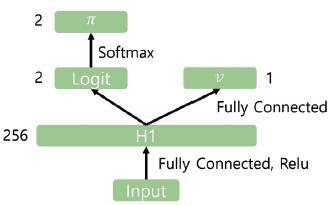
CartPole 환경의 상태는 4차원이기 때문에 입력은 4차원이고, 네트워크 흐름은 다음과 같다.
State (4차원) → FC layer (256) → 두 개의 head로 분기
- Policy head → 2차원 출력 (좌/우 행동 확률)
- Value head → 1차원 출력 (상태 가치)
Policy 함수(𝜋)는 다음과 같이 계산된다.
def pi(self, x, softmax_dim = 0):
x = F.relu(self.fc1(x))
x = self.fc_pi(x)
prob = F.softmax(x, dim=softmax_dim)
return prob
여기서 softmax를 통해 행동 확률 분포가 만들어진다.
Value 가치 함수(φ)는 다음과 같이 계산된다.
def v(self, x):
x = F.relu(self.fc1(x))
v = self.fc_v(x)
return v
2. 데이터 저장 구조
환경에서 얻은 transition은 다음 형태로 저장된다: (s, a, r, s', done)
이를 put_data() 함수로 list에 저장한다.
def put_data(self, transition):
self.data.append(transition)
여기서 n_rollout = 10 이라는 하이퍼파라미터가 있다.
이는 transition(s, a, r, s')을 10개를 모은 뒤 한 번에 학습하도록 하는 것이다.
즉 10 step 단위로 mini batch 학습을 수행한다.
3. Batch 생성
make_batch() 함수는 transition 데이터를 tensor로 변환하는 역할을 한다.
s_lst, a_lst, r_lst, s_prime_lst, done_lst = [], [], [], [], []
transition을 상태, 행동, 보상 등으로 분리한 뒤 tensor로 변환한다.
특히 중요한 부분은 done mask이다.
done_mask = 0.0 if done else 1.0
에피소드가 끝난 경우 γ * V(s′) 항이 사라지도록 만들기 위해 사용된다.
따라서 TD target 계산 시 r + γV(s′) × done이 되며, 마지막 상태에서는 다음 상태 가치가 0이 된다.
4. TD Target과 TD Error 계산
학습에서 가장 중요한 부분은 TD error 계산이다.
td_target = r + gamma * self.v(s_prime) * done
delta = td_target - self.v(s)
여기서 TD target은 r + γV(s′), 현재 value의 estimation은 V(s)이며,
이 두 값의 차이가 바로 TD error 𝛿이다.
이 TD error는 Advantage의 sample의 역할을 한다.
5. Policy Loss
정책 업데이트는 다음 식을 따른다.

코드에서는 다음과 같이 구현되어 있다.
pi = self.pi(s, softmax_dim=1)
pi_a = pi.gather(1,a)
loss = -torch.log(pi_a) * delta.detach()
여기서 중요한 부분은 delta.detach() 부분인데 detach는 계산 그래프에서 gradient 전달을 끊는 역할을 한다.
이유는 다음과 같다.
- 𝛿는 Critic이 계산한 평가 값
- Actor는 이 평가를 가중치로만 사용
따라서 𝛿 가 역전파에 참여하면 Critic까지 함께 업데이트되어 학습이 꼬일 수 있다.
그래서 𝛿 를 숫자 값처럼 사용하기 위해 detach를 적용한다.
6. Value Loss
Value 네트워크는 TD learning으로 학습된다.
F.smooth_l1_loss(self.v(s), td_target.detach())이는 다음 식과 동일하다.

여기서도 delta.detach() 가 사용되는데 이 이유는 TD target은 정답값 역할을 해야 하기 때문이다.
- TD target은 gradient를 받으면 안 되고
- 현재 Value prediction만 target 방향으로 이동해야 한다.
그래서 detach를 사용한다.
7. 최종 Loss
정책 loss와 value loss는 합쳐서 한 번에 업데이트된다.
loss = -torch.log(pi_a) * delta.detach() \
+ F.smooth_l1_loss(self.v(s), td_target.detach())
수식적으로는 Policy Loss + Value Loss으로 표현된다.
그리고 역전파를 수행한다.
self.optimizer.zero_grad()
loss.mean().backward()
self.optimizer.step()8. 학습 루프
학습 루프는 다음과 같은 흐름을 가진다.
- 1. 현재 정책으로 행동 샘플링
prob = model.pi(torch.from_numpy(s).float())
m = Categorical(prob)
a = m.sample().item()
- 2. 환경 실행
s_prime, r, done, truncated, info = env.step(a)
- 3. transition 저장
model.put_data((s,a,r,s_prime,done))
- 4. n_rollout이 10이 되면 학습
model.train_net()
이 과정을 반복하면서 policy와 value가 동시에 개선된다.
전체 코드
import gym
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
#Hyperparameters
learning_rate = 0.0002
gamma = 0.98
n_rollout = 10
class ActorCritic(nn.Module):
def __init__(self):
super(ActorCritic, self).__init__()
self.data = []
self.fc1 = nn.Linear(4,256)
self.fc_pi = nn.Linear(256,2)
self.fc_v = nn.Linear(256,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, softmax_dim = 0):
x = F.relu(self.fc1(x))
x = self.fc_pi(x)
prob = F.softmax(x, dim=softmax_dim)
return prob
def v(self, x):
x = F.relu(self.fc1(x))
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
s_lst, a_lst, r_lst, s_prime_lst, done_lst = [], [], [], [], []
for transition in self.data:
s,a,r,s_prime,done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r/100.0])
s_prime_lst.append(s_prime)
done_mask = 0.0 if done else 1.0
done_lst.append([done_mask])
s_batch, a_batch, r_batch, s_prime_batch, done_batch = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst, dtype=torch.float), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float)
self.data = []
return s_batch, a_batch, r_batch, s_prime_batch, done_batch
def train_net(self):
s, a, r, s_prime, done = self.make_batch()
td_target = r + gamma * self.v(s_prime) * done
delta = td_target - self.v(s)
pi = self.pi(s, softmax_dim=1)
pi_a = pi.gather(1,a)
loss = -torch.log(pi_a) * delta.detach() + F.smooth_l1_loss(self.v(s), td_target.detach())
self.optimizer.zero_grad()
loss.mean().backward()
self.optimizer.step()
def main():
env = gym.make('CartPole-v1')
model = ActorCritic()
print_interval = 20
score = 0.0
for n_epi in range(10000):
done = False
s, _ = env.reset()
while not done:
for t in range(n_rollout):
prob = model.pi(torch.from_numpy(s).float())
m = Categorical(prob)
a = m.sample().item()
s_prime, r, done, truncated, info = env.step(a)
model.put_data((s,a,r,s_prime,done))
s = s_prime
score += r
if done:
break
model.train_net()
if n_epi%print_interval==0 and n_epi!=0:
print("# of episode :{}, avg score : {:.1f}".format(n_epi, score/print_interval))
score = 0.0
env.close()
if __name__ == '__main__':
main()
학습 결과
학습 속도는 조금 느리지만, 굉장히 적은 에피소드만으로 훌륭한 score를 기록한다.
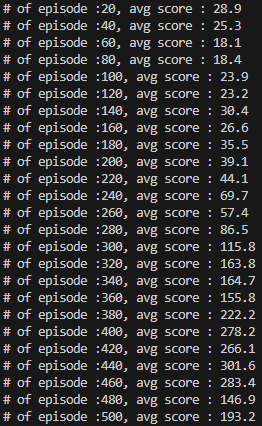
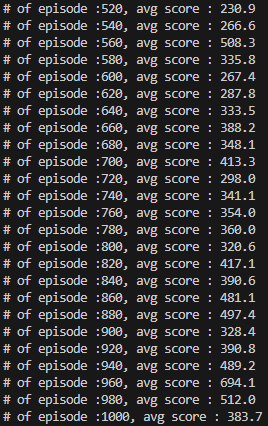
출처 : https://product.kyobobook.co.kr/detail/S000000555527
바닥부터 배우는 강화 학습 | 노승은 - 교보문고
바닥부터 배우는 강화 학습 | 강화 학습 기초 이론부터 블레이드 & 소울 비무 AI 적용까지 이 책은 강화 학습을 모르는 초보자도 쉽게 이해할 수 있도록 도와주는 입문서입니다. 현업의 강화 학습
product.kyobobook.co.kr
'딥러닝 모델 > DQN for Cloud-Edge Caching' 카테고리의 다른 글
| [강화학습 기초 13] Proximal Policy Optimization (PPO) (0) | 2026.03.11 |
|---|---|
| [강화학습 기초 12] Asynchronous Advantage Actor-Critic (A3C) (0) | 2026.03.11 |
| [강화학습 기초 10] Policy Gradient와 REINFORCE 알고리즘 구현 (0) | 2026.03.04 |
| [강화학습 기초 9] Policy 기반 강화학습과 Policy Gradient 이론 (Value 기반 vs Policy 기반) (0) | 2026.03.04 |
| [강화학습 기초 8] 딥마인드 DQN의 구조와 학습 테크닉 (Replay Buffer, Target Network) (0) | 2026.03.03 |