강화학습 분야에서 PPO는 현재까지도 매우 널리 사용되는 대표적인 알고리즘 중 하나이다.
어떤 문제를 강화학습으로 해결하려 할 때 특별한 이유가 없다면 가장 먼저 시도해볼 만한 baseline 알고리즘으로 자주 언급된다.
실제로 대규모 강화학습 연구에서는 크게 두 계열의 접근이 많이 사용된다.
하나는 OpenAI의 PPO이고, 다른 하나는 DeepMind의 IMPALA 계열의 알고리즘이다.
우선 IMPALA는 A3C를 확장한 형태의 알고리즘이라고 볼 수 있다.
A3C는 하나의 노드 내부에서 여러 개의 프로세스를 실행하여 병렬 학습을 수행하는 방식이다.
IMPALA는 이러한 구조를 여러 노드(Macine)로 확장하여 대규모 분산 환경에서 학습을 수행할 수 있도록 만든 구조이다.
이처럼 학습 시스템이 큰 규모로 확장되면 업데이트 속도는 빨라지지만, 동시에 off-policy 문제가 발생한다.
이는 데이터를 생성한 policy와 현재 학습 중인 policy가 서로 달라지는 상황에서 발생하는 문제이다.
IMPALA에서는 이를 해결하기 위해 V-trace라는 방법을 사용하여 value function 계산 시 발생하는 오차를 보정한다.
PPO는 off-policy 문제를 직접 보정하는 방식이 아니라,
정책 업데이트의 변화를 제한하여 안정적인 on-policy 학습을 수행하는 접근을 사용한다.
정리하면 대규모 강화학습 학습 구조를 보면 한쪽에는 PPO, 다른 한쪽에는 IMPALA 계열의 알고리즘이 있다고 볼 수 있다.
PPO (Proximal Policy Optimization)의 특징

PPO는 존 슐만이 쓴 2017년 논문으로 2016년 초 기준 36000회가 넘게 인용이 된 RL의 근본있는 알고리즘이다.
다양한 환경에서 안정적으로 동작하며, 현재까지도 많은 논문에서 baseline으로 사용된다.
강화학습 알고리즘이 실용적으로 사용되기 위해서는 다음과 같은 특징을 만족해야 한다.
- 다양한 환경에서 안정적인 성능을 보여야 한다.
- action space가 continuous이든 discrete이든 모두 잘 동작해야 한다.
- 여러 번 실행하더라도 성능 편차가 크지 않아야 한다.
- 구현이 단순해야 하며, 버그 가능성이 낮아야 한다.
PPO는 이러한 조건을 상당히 잘 만족하는 알고리즘인데, 특히 구현이 매우 단순하다는 장점이 있다.
PPO의 핵심은 policy 업데이트에 사용되는 loss function에 있는데,
이 loss function을 계산하는 코드가 비교적 짧고 단순하여 구현 부담이 적다.
또한 PPO는 매우 복잡한 이론적 보장을 강조하기보다는,
정책 업데이트를 안정적으로 제한하는 근사 방법을 통해 실제 학습에서 좋은 성능을 얻는 실용적인 접근을 취하고 있다.
즉, 이론적으로 완벽한 최적화를 수행하기보다는 정책이 너무 크게 변하지 않도록 제한하면서 안정적으로 학습하도록 설계된 알고리즘이라고 볼 수 있다.
PPO의 핵심 아이디어
PPO의 기본 취지는 Policy Gradient 방법의 데이터 효율성을 높이는 것이다.
Policy Gradient에서는 어떤 πθ가 있다고 하자. 이 policy는 파라미터 θ\로 parameterization 되어 있다.
먼저 πθ를 환경에서 실행하여 trajectory 데이터를 수집하고,
그 데이터를 이용해 gradient를 계산하여 policy parameter θ를 업데이트한다.
여기서 자연스럽게 떠오르는 질문이 있다.
수집한 데이터를 이용해 policy를 여러 번 업데이트하면 더 효율적이지 않을까?
왜 Policy Gradient에서는 데이터를 여러 번 쓰기 어려울까?
강화학습에서 DQN을 떠올려 보면 replay buffer를 사용하여 경험을 여러 번 재사용할 수 있었다. 이는 두 가지 장점을 가진다.
- 경험 간의 correlation을 줄여 학습 안정성을 높일 수 있다.
- 같은 데이터를 여러 번 사용할 수 있어 sample efficiency가 높다.
이러한 방식이 가능한 이유는 DQN이 off-policy 알고리즘이기 때문이다.
DQN에서 학습하려는 값은 최적의 Q-function Q∗이다.
이 값은 현재 policy가 무엇인지와는 직접적인 관계가 없는 MDP의 고유한 속성이다.
따라서 어떤 policy로 수집한 데이터라도 Bellman optimal equation을 이용해 업데이트할 수 있으며,
과거의 경험도 문제없이 사용할 수 있다.
Policy Gradient에서 발생하는 문제와 PPO의 목
하지만 policy 기반 방법론에서는 상황이 다르다.
Policy Gradient theorem을 보면, gradient는 현재 policy πθ에 의해 수집된 데이터로 계산된다.
따라서 πθ로 데이터를 모은 뒤 θ를 업데이트하면, 방금 사용했던 데이터는 이전 policy에서 생성된 outdated data가 된다.
이 때문에 일반적인 policy gradient 알고리즘에서는 데이터를 한 번 사용하고 버리는 방식을 사용한다.
PPO는 이러한 문제를 해결하면서도 on-policy 학습을 유지하는 것을 목표로 한다.
즉 PPO는 off-policy 알고리즘이 아니지만,
- 데이터를 한 번만 사용하고 버리는 대신
- 같은 데이터를 여러 번 사용하여 policy를 업데이트하고
- data efficiency를 높이려는 접근을 취한다.
PPO의 Solution
PPO의 핵심 아이디어는 다음과 같다.
현재 policy를 θ_{old}라고 하고, 업데이트된 policy를 θ라고 하자.
PPO는 policy 업데이트를 수행할 때 새로운 policy와 기존 policy가 너무 많이 달라지지 않도록 제한하면서 업데이트한다.
이렇게 하면 같은 데이터로 여러 번 업데이트를 수행하더라도 policy distribution이 크게 변하지 않기 때문에 학습이 안정적으로 유지된다.
PPO의 아이디어는 TRPO(Trust Region Policy Optimization)에서 발전한 것이다.

TRPO 역시 policy가 한 번에 크게 변하지 않도록 제한하는 trust region 기반 업데이트 방법을 제안한다.
다만 TRPO는 계산 과정이 복잡하고 구현 난이도가 높은 편이다.
반면 PPO는 이러한 아이디어를 간단한 트릭으로 근사하여 구현을 크게 단순화한 알고리즘이다.
즉 PPO의 특징을 요약하면 다음과 같다.
- 새로운 policy가 기존 policy와 가깝도록 유지하면서 업데이트를 수행하고
- 구현이 매우 단순하며
- 실제 실험에서도 안정적인 성능을 보여주는 강화학습 알고리즘이라고 볼 수 있다.
PPO의 이론
Policy Gradient
Policy gradient는 log policy의 gradient에 Advantage를 곱한 형태로 계산된다.

여기서 Advantage 자리에는 다양한 값이 들어갈 수 있다. 예를 들어 Q(s,a)를 사용할 수도 있지만,
단순히 Q값만 사용할 경우 variance가 매우 커지는 문제가 있다.
따라서 보통은 Q(s,a)−V(s) 형태의 Advantage를 사용한다.
경우에 따라서는 trajectory에서 얻은 Return 값이 직접 사용되기도 한다.
결국 이 값들은 해당 trajectory가 얼마나 좋은 결과를 가져왔는지를 평가하는 scalar 값이라고 볼 수 있다.
수식에서 사용된 hat(ˆ) 기호는 estimate(추정값)을 의미한다.
실제 환경이 복잡해질수록 정확한 gradient를 직접 계산하는 것은 사실상 불가능하다.
따라서 여러 trajectory에서 수집한 샘플들을 이용해 Expectation을 근사적으로 추정하여 gradient를 계산한다.
Advantage 또한 정확한 값을 알 수 없기 때문에 estimate로 계산된다.
예를 들어 Advantage를 Q(s,a)−V(s)로 정의하더라도,
이 두 값은 모두 policy πθ를 따랐을 때 얻을 기대 리턴의 값이므로 실제 값을 직접 알 수 없다.
따라서 실제 구현에서는 신경망을 이용해 Q-function이나 Value function을 학습하고,
학습된 값이 실제 Q와 V에 근접한다고 가정하여 Advantage를 계산한다.
이러한 방식으로 trajectory의 품질을 평가할 수 있는 기준을 얻고, 이를 이용해 policy gradient를 계산하게 된다.
Policy Gradient를 Loss 형태로 표현
실제 구현에서는 위의 Policy Gradient 식을 loss 형태로 표현하여 사용한다.
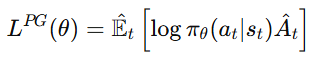
실제로 PyTorch와 같은 딥러닝 프레임워크로 policy gradient 알고리즘을 구현할 때는,
이 loss 함수를 구현한 뒤 자동 미분을 사용하여 gradient를 계산한다.
즉, 이 loss를 미분하면 위에서 본 policy gradient 식이 그대로 나오게 된다.
프레임워크가 자동으로 미분을 수행하기 때문에 우리는 loss 식만 정의하면 된다.
정확히 말하면 이 값을 maximize해야 하므로 실제 구현에서는 보통 부호를 바꿔서 minimize 형태로 사용한다.
Chain rule을 이용한 식의 변형
이 식은 chain rule을 이용하여 다른 형태로도 표현할 수 있다.

여기서 핵심은 다음 관계이다. (logf(θ)를 미분하면 1/f(θ)이 됨을 사용)
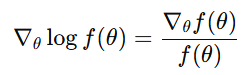
이 관계를 policy probability πθ(a∣s)에 적용하면 policy gradient 식을 확률 비율(ratio) 형태로 다시 쓸 수 있다.
와 θ_{old}
여기서 중요한 점은 두 개의 policy 파라미터가 등장한다는 것이다.

trajectory 데이터는 θ_{old} 정책으로 수집되었기 때문에 expectation 역시 그 분포를 기준으로 계산된다.
따라서 policy gradient를 다음과 같은 ratio 형태의 objective로 표현할 수 있다.

이때 πθ(at∣st)\를 일반적으로 f(θ)로 두어 표현하기도 한다.
Importance Sampling 관점
앞에서 얻은 objective는 importance sampling 관점에서도 해석할 수 있다.
우리가 실제로 최대화하고 싶은 것은 다음과 같은 값이다.
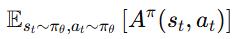
즉 현재 policy πθ 를 기준으로 계산된 Advantage의 expectation을 최대화하고 싶다.
하지만 실제 데이터는 πθ_{old} 로 수집되었다.
즉 우리가 가진 샘플은 다른 분포에서 생성된 데이터이다.
이처럼 한 분포의 expectation을 계산하고 싶지만 다른 분포에서 샘플을 얻은 경우 사용하는 방법이 바로 importance sampling이며, 이를 이용하면 expectation을 다음과 같이 변형할 수 있다.
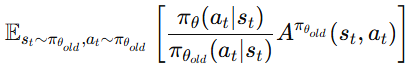
여기서 Advantage의 정확한 값은 알 수 없기 때문에 실제 구현에서는 추정값 를 사용한다.
따라서 최종 objective는 다음과 같이 표현된다.
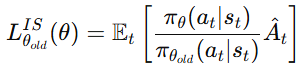
여기서 앞의 확률 비율을 importance sampling ratio라고 한다.
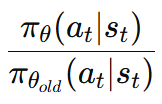
이 objective는 importance sampling 관점에서도 해석될 수 있다.
우리가 실제로 계산하고 싶은 것은
- 현재 policy πθ 기준의 expectation
이지만, 실제 데이터는
- 이전 policy πθ_{old} 로 수집되었다.
이처럼 다른 분포에서 얻은 샘플로 expectation을 계산해야 할 때 사용하는 기법이 바로 importance sampling이다.
따라서 위 식은 아래와 같이 부르며, 여기서 IS는 Importance Sampling을 의미한다.
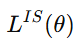
문제 상황
여기서 중요한 점은 이 식이 θ\ 와 θ_{old}가 서로 가까울 때만 잘 성립한다는 것이다.
만약 두 policy가 크게 달라지기 시작하면,
이 objective를 이용해 업데이트를 하더라도 policy의 실제 성능이 향상된다는 보장이 사라진다.
그 이유는 크게 두 가지가 있다.
- Advantage의 불일치 문제
현재 사용되는 Advantage는 θold\theta_{old} 정책으로 수집된 데이터를 기반으로 계산된 값이다.
하지만 우리가 평가하려는 것은 현재 policy θ 이다.
따라서 두 policy가 크게 달라질수록 Advantage 추정값의 정확도가 떨어지게 된다. - Policy improvement 보장의 붕괴
Policy gradient가 전체 성능 향상을 보장하기 위한 조건에 대해서는 Kakade가 2002년에 제시한 이론적 결과가 있다.
이 결과에서도 policy가 한 번에 너무 크게 변하지 않아야 한다는 조건이 등장한다
결국 우리가 풀고 싶은 문제는 다음과 같다.
- L^{IS} 를 최대화하고 싶다.
- 동시에 θ와 θ_{old} 가 너무 멀어지지 않도록 해야 한다.
이를 정리하면 다음과 같은 형태의 문제가 된다.
Importance sampling objective를 최대화하면서 policy가 크게 변하지 않도록 제한해야 한다.
이때 편의를 위해 다음과 같이 ratio를 기호 로 정의한다.

이 ratio가 바로 PPO에서 핵심적으로 등장하는 값이다.
PPO의 선행 연구인 Trust Region Policy Optimization (TRPO)
우리가 해결하고 싶은 문제는 다음과 같다.
- Importance sampling objective L^{IS}를 최대화하고 싶다.
- 동시에 현재 policy θ 와 이전 policy θ_{old} 가 너무 멀어지지 않도록 해야 한다.
이 문제를 해결하기 위해 2015S년에 제안된 방법이 TRPO (Trust Region Policy Optimization) 이다.

Constrained Optimization Probelm
TRPO는 이 문제를 constrained optimization 문제로 바꾸어 해결한다.

subject to

여기서 KL divergence는 두 확률 분포 사이의 차이를 측정하는 값이다.
따라서 이 조건은 "새로운 policy가 이전 policy와 너무 크게 달라지지 않도록 제한한다"는 의미를 가진다.
즉 TRPO는 다음의 방식을 사용한다,
- policy 성능을 증가시키는 objective를 최대화하면서
- policy 업데이트의 크기를 trust region 안으로 제한하는 방식.
하지만 이러한 constraint optimization 문제는 실제로 풀기가 상당히 어렵다.
Penalty Problem 형태로의 변형
이 문제는 constraint 대신 penalty 형태로도 표현할 수 있다.

여기서 β\beta는 penalty coefficient이다.
이 식의 의미는 다음과 같다.
- objective는 최대화하려고 한다
- 하지만 policy가 이전 policy와 너무 멀어질수록 penalty를 부여한다
즉, policy improvement와 policy stability 사이의 trade-off를 조절하는 방식이다.
라그랑주 승수법(Lagrange multipliers)에 따르면 constraint problem와 penalty problem는,
적절한 δ 와 β 가 존재할 경우 동일한 최적해를 갖는다.
하지만 실제 구현에서는
- δ\delta 를 직접 설정하는 방식이 더 안정적이며
- 고정된 β\beta 를 사용하는 것보다 fixed δ\delta 가 튜닝하기 쉽다고 알려져 있다.
PPO의 알고리즘
앞에서 본 TRPO의 아이디어는 policy가 너무 크게 변하지 않도록 제한하면서 objective를 최대화하는 것이었다.
하지만 TRPO는 constrained optimization 문제를 풀어야 하기 때문에 구현이 복잡하다.
PPO는 이러한 아이디어를 훨씬 간단한 방식으로 근사한 알고리즘이다.
PPO의 핵심 objective는 다음과 같다.

여기서

Original Loss
먼저 기본이 되는 objective는 다음과 같다.

즉 policy probability ratio × advantage이다.
이 값만 사용하여 업데이트하면 policy gradient 방식으로 학습이 가능하다.
하지만 이 경우 ratio가 크게 변하면서 policy가 급격히 변하는 문제가 발생할 수 있다.
Clipped Loss
이를 방지하기 위해 PPO는 ratio를 일정 범위 안으로 제한하는 clipping 기법을 사용한다.

예를 들어 ϵ=0.2라면 ratio는 0.8 ≤ rt(θ) ≤ 1.2 범위로 제한된다.
이 범위를 벗어나면 ratio는 더 이상 증가하거나 감소하지 않고 경계값으로 잘린다.
따라서 r > 1 + ϵ 나 r < 1 − ϵ 인 경우에는 gradient가 더 이상 흐르지 않게 된다.
이로 인해 policy가 한 번에 크게 업데이트되는 것을 막을 수 있다.
PPO Final Loss
PPO에서는 Original loss와 Clipped loss 중 더 작은 값을 사용한다.

이렇게 하는 이유는 clipped objective가 original objective의 lower bound 역할을 하기 때문이다.
즉 우리가 최대화하고 싶은 값이 있을 때, 그 값의 lower bound를 최대화하면 결과적으로 원래 objective도 증가하게 된다.
Advantage의 부호에 따른 동작
Clipping이 실제로 어떻게 동작하는지는 Advantage의 부호에 따라 달라진다.
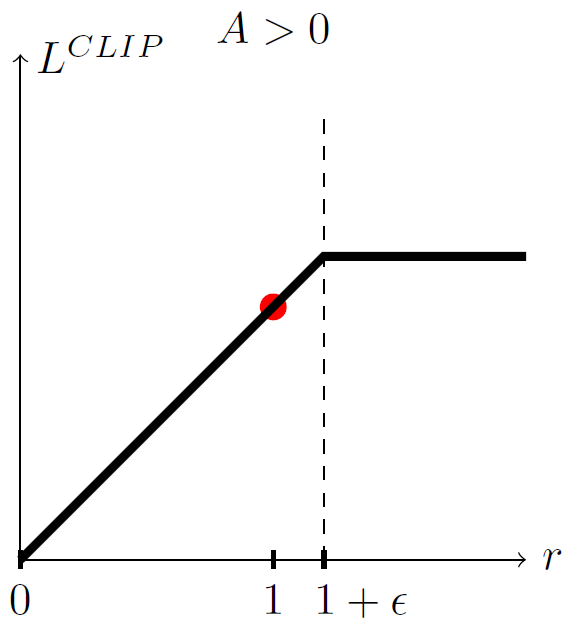
1. Advantage A > 0
이 경우 해당 action은 좋은 action이므로,
policy는 이 action을 더 자주 선택하도록 업데이트된다.
하지만 ratio가 1 + ϵ 을 넘어가면 더 이상 업데이트하지 않는다.
즉 너무 빠르게 확률이 증가하는 것을 막는다.
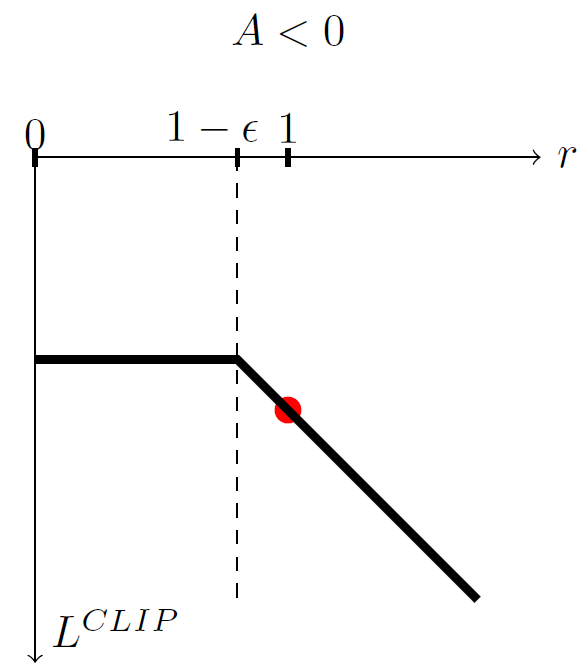
2. Advantage A < 0
이 경우 해당 action은 좋지 않은 action이므로,
policy는 이 action을 덜 선택하도록 업데이트된다.
하지만 ratio가 1 - ϵ 보다 작아지면 더 이상 업데이트하지 않는다.
즉 확률이 너무 급격히 감소하는 것도 막는다.
직관적인 해석
정리하면 PPO는 다음과 같은 방식으로 업데이트를 수행한다.
- 좋은 action이면 확률을 증가시키되 너무 많이 증가하지 않도록 제한
- 나쁜 action이면 확률을 감소시키되 너무 많이 감소하지 않도록 제한
즉 PPO는 policy 업데이트를 보수적으로 수행하도록 만드는 알고리즘이라고 볼 수 있다.
이러한 방식은 이론적으로 완벽히 유도된 식이라기보다는 실험적으로 안정적인 성능을 보인 경험적 설계(empirical design)이다. 실제로 다양한 환경에서 PPO는 안정적이고 강력한 성능을 보여주는 reinforcement learning 알고리즘으로 널리 사용되고 있다.
Pseudo Code
PPO의 수도코드는 매우 간단하다. 전체 과정은 다음과 같이 반복된다.

1. 데이터 수집
먼저 현재 policy를 사용하여 환경에서 데이터를 수집한다.
- T timesteps 동안 policy를 실행하거나
- N개의 trajectory를 수집한다.
이 과정을 통해 상태, 행동, 보상 등의 trajectory 데이터가 생성된다.
2. Advantage 계산
다음으로 모든 timestep에 대해 Advantage 값을 계산한다.
Advantage는 policy gradient에서 trajectory의 품질을 평가하는 값으로 사용된다.
실제 PPO 구현에서는 단순한 A(s, a) = Q(s, a) − V(s) 대신 Generalized Advantage Estimation (GAE)를 자주 사용한다.
GAE는 기존 Advantage보다 variance와 bias 사이의 trade-off를 더 잘 조절할 수 있어 실제 실험에서 더 좋은 성능을 보인다.
여기서 중요한 점은 Advantage 값은 뉴럴 네트워크의 gradient와 직접 연결되지 않는 상수 값이라는 것이다.
따라서 보통 detach된 상태에서 계산된다.
3. 여러 번 업데이트 (SGD)
기존의 on-policy policy gradient 알고리즘에서는 데이터를 한 번 사용하고 버리는 경우가 많았다.
하지만 PPO에서는 안정적인 업데이트를 보장하는 장치가 추가되었기 때문에 같은 데이터를 여러 번 사용하여 업데이트할 수 있다.
따라서 수집한 데이터를 이용해 L^CLIP(θ) objective를 기준으로 여러 번 SGD(Stochastic Gradient Descent)를 수행한다.
이때 업데이트 횟수는 epoch 수로 결정되는 hyperparameter이다.
예를 들어 3 epochs나 10 epochs 등으로 설정할 수 있으며, 환경이나 실험 조건에 따라 성능이 달라질 수 있다.
PPO 실험 결과
논문에서는 PPO의 성능을 기존 강화학습 알고리즘들과 비교하기 위해 Atari 게임 환경에서 실험을 수행하였다.
비교 대상 알고리즘은 다음과 같다.
- A2C (Advantage Actor-Critic) : 이전에 배운 A3C에서 asynchronous 구조를 제거한 버전.
A3C는 여러 worker가 비동기적으로 업데이트 / A2C는 데이터를 모은 뒤 동기적으로 한 번에 업데이트 - ACER (Actor-Critic with Experience Replay): DQN의 experience replay를 actor-critic 구조에 적용한 알고리즘.
이를 위해 강력한 off-policy correction 기법을 사용하는데, 이때 발생하는 bias를 줄이기 위해 Q-function을 학습하고, Retrace Q라는 off-policy evaluation 으로 보정한다. - PPO
총 49개의 Atari 게임 환경에서 실험이 진행되었으며, 두 가지 기준으로 성능을 평가하였다.
평가 기준
논문에서는 다음 두 가지 기준을 사용하여 알고리즘의 성능을 비교하였다.
- 학습 과정 전체에서의 평균 episode reward → 학습이 얼마나 빠르게 진행되는지를 평가하는 기준
- 마지막 100 episode의 평균 reward → 최종 성능이 얼마나 좋은지를 평가하는 기준
각 게임 환경에서 세 알고리즘을 3번씩 학습시킨 뒤 평균 성능을 측정하였다.
Discrete한 Atari 환경 실험 결과
49개의 Atari 게임에서 각 기준별로 가장 좋은 성능을 보인 알고리즘의 개수는 다음과 같다.

이를 통해 다음과 같은 특징을 확인할 수 있다.
- 학습 속도 기준에서는 PPO가 49개 중 30개 환경에서 가장 좋은 성능을 보였다.
- 최종 성능 기준에서는 ACER가 더 좋은 결과를 보이는 경우가 많았다.
Continuous Control 환경 실험 결과

논문에서는 Atari 환경뿐 아니라 continuous control 환경에서도 PPO의 성능을 평가하였다.
이를 위해 MuJoCo 환경의 7가지 문제를 사용하였다.
사용된 대표적인 환경은 다음과 같다.
- HalfCheetah-v1 / Hopper-v1 / InvertedDoublePendulum-v1 / InvertedPendulum-v1
- Reacher-v1 / Swimmer-v1 / Walker2d-v1
각 환경에서 모든 알고리즘은 동일하게 1 million step 동안 학습하도록 설정하였다.
또한 비교 대상 알고리즘은 다음과 같다.
- A2C / TRPO / Vanilla Policy Gradient / CEM / PPO (clip version)
실험에서는 A3C 대신 A2C를 사용하였다. A2C가 구현이 더 간단하면서도 성능이 안정적이기 때문이다.
그래프를 보면 대부분의 환경에서 PPO가 안정적으로 높은 성능을 보이는 것을 확인할 수 있다.
특히 PPO의 clipped objective 버전이 다른 알고리즘들보다 다음과 같은 특징을 보였다.
- 학습이 안정적으로 진행됨
- 성능이 빠르게 상승함
- 여러 환경에서 일관된 성능
반면 다른 알고리즘들은 환경에 따라 성능 변동이 큰 경우가 있었다.
따라서 PPO는 discrete 환경 (Atari)과 continuous control 환경 (MuJoCo)
모두에서 안정적인 성능을 보이는 알고리즘임이 확인되었다.
특히 PPO의 clip 방식 objective가 다양한 환경에서 좋은 성능을 보였으며, 이러한 이유로 PPO는 이후 많은 연구에서 강화학습의 기본 baseline 알고리즘으로 널리 사용되고 있다.
'딥러닝 모델 > DQN for Cloud-Edge Caching' 카테고리의 다른 글
| 모바일 Edge Caching의 개념과 강화학습의 필요성 (0) | 2026.03.12 |
|---|---|
| Edge–Cloud 패러다임에서의 Offloading의 개념 (0) | 2026.03.12 |
| [강화학습 기초 12] Asynchronous Advantage Actor-Critic (A3C) (0) | 2026.03.11 |
| [강화학습 기초 11] Actor-Critic 알고리즘 총정리 (Q, Advantage, TD) (0) | 2026.03.09 |
| [강화학습 기초 10] Policy Gradient와 REINFORCE 알고리즘 구현 (0) | 2026.03.04 |