현대 네트워크는 단순히 데이터를 전달하는 인프라가 아니라 실시간 계산을 수행하는 분산 컴퓨팅 플랫폼으로 진화하고 있다.
특히 모바일 기기, IoT 장치, 자율주행 차량과 같은 수많은 End-device들이 등장하면서 네트워크는 새로운 문제에 직면하였다.
- 데이터는 폭발적으로 증가하고
- 사용자들은 초저지연 서비스를 요구하며
- 모바일 디바이스는 제한된 연산 능력과 배터리를 가진다
이 문제를 해결하기 위해 등장한 개념이 아래와 같다.
- Edge Computing
- Fog Computing
- Computation Offloading
이 글에서는 이러한 컴퓨팅 패러다임을 정리하고, 왜 이 문제가 강화학습(특히 DQN) 으로 이어지는지를 설명한다.
Device–Edge–Cloud 컴퓨팅 패러다임
전통적인 인터넷 구조에서는 대부분의 연산이 Cloud Datacenter에서 수행되었다.
그러나 모바일 환경에서는 이 구조가 치명적인 한계를 가진다.
- Cloud까지의 네트워크 지연(latency)
- Core network 트래픽 폭증
- 모바일 디바이스의 제한된 연산 능력
이를 해결하기 위해 등장한 구조가 3-tier computing architecture이다.

3-Tier Computing Architecture에서 계층은 End Devices → Edge/Fog Layer → Cloud Datacenter로 이어진다.
각 계층의 역할은 다음과 같다.
1. End Device Layer
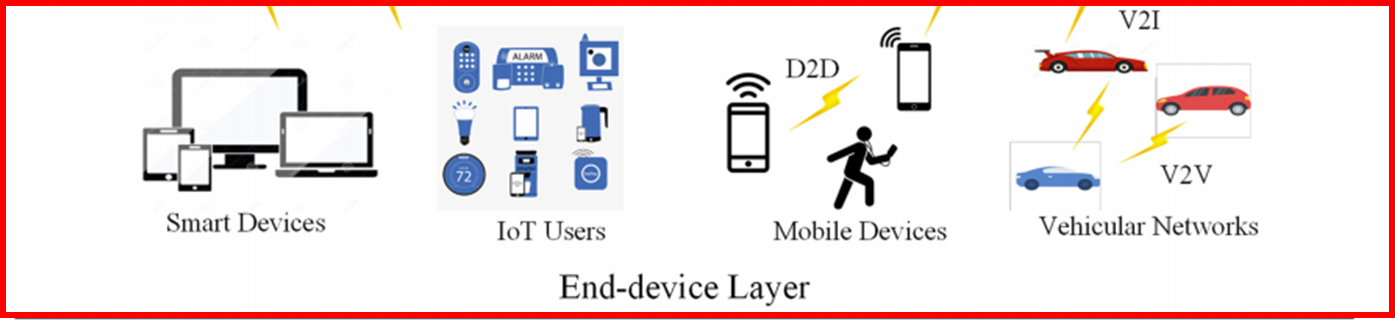
이 계층에는 다음과 같은 장치들이 포함된다: 스마트폰, IoT 센서, 스마트 차량, AR/VR 기기
이 장치들은 배터리 제한, 낮은 CPU/GPU 성능, 제한된 저장공간이라는 특징을 가진다.
따라서 대규모 연산을 로컬에서 처리하기 어렵다.
예를 들어 실시간 영상 분석, AR/VR 렌더링, 자율주행 perception, 대규모 데이터 분석 같은 작업은 모바일 장치에서 수행하기 어렵다.
2. Edge / Fog Layer
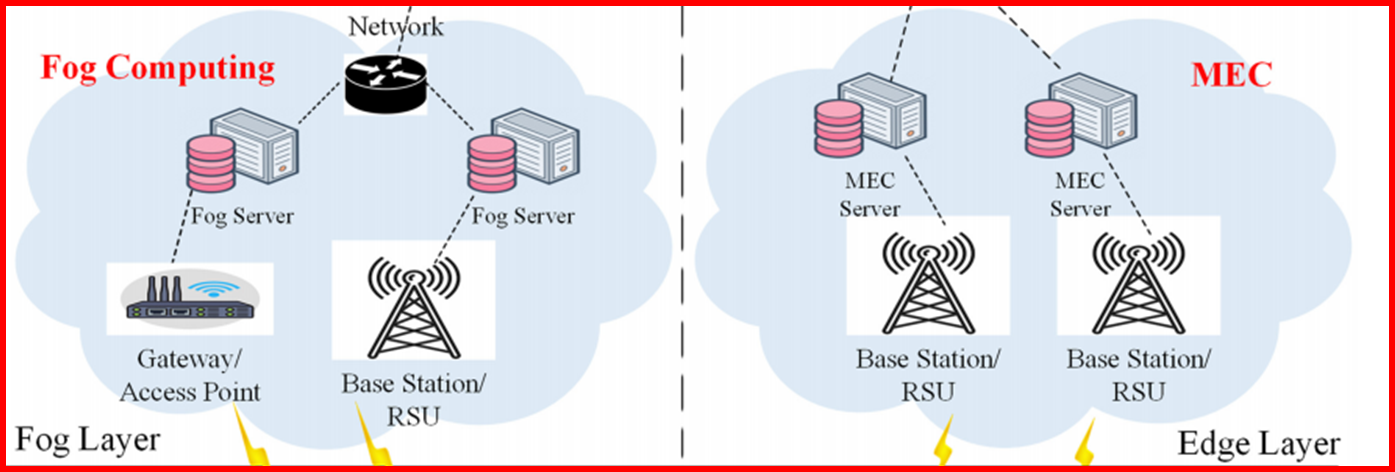
이 문제를 해결하기 위해 네트워크 가까이에 배치된 서버가 등장했다.
대표적인 예는 다음과 같다: Base Station, Access Point, RSU (Road Side Unit), Gateway, Edge Server
이 계층은 Cloud보다 가까운 위치에서 계산을 수행한다.
따라서 지연 감소, 네트워크 트래픽 감소, 사용자 경험 개선을 가능하게 한다.
특히 MEC (Multi-access Edge Computing) 은 이동통신 네트워크의 기지국에 서버를 배치하여 이러한 역할을 수행한다.
1.3 Cloud Layer

Cloud는 여전히 가장 강력한 컴퓨팅 자원을 제공한다.
특징은 다음과 같다.
- 대규모 GPU/CPU 클러스터
- 수천 개의 서버
- 대규모 데이터 저장
따라서 대규모 연산 작업은 Cloud에서 처리된다.
하지만 Cloud는 사용자와 물리적으로 멀기 때문에 네트워크 지연, 코어 네트워크 부하 문제가 발생한다.
Computation Offloading
Edge/Fog/Cloud 구조가 등장하면서 Computation Offloading이라는 새로운 개념이 등장했다.
이는 모바일 디바이스에서 수행해야 할 계산 작업을 Edge 또는 Cloud 서버로 전달하여 처리하는 것을 말한다.
이 방식은 다음과 같은 장점을 제공한다.
- 지연 감소
- 에너지 소비 감소
- QoS 향상
- 모바일 장치 성능 한계 극복
예를 들어 스마트폰에서 영상 객체 인식을 수행한다고 가정해보면 2가지 선택지가 있다.
- 로컬에서 처리
- Edge 서버로 offloading
이때 어떤 선택이 더 좋을지는 상황에 따라 다르다.
Offloading 의사결정 문제
Offloading에는 항상 trade-off가 존재한다.
Local Computing
장점 : 네트워크 전송이 없어서 즉시 실행이 가능함.
단점 : 연산 성능이 부족하고 에너지 소비가 증가함.
Edge / Cloud Offloading
장점 : 높은 연산 능력으로 빠른 처리가 가능함.
단점 : 네트워크 전송 지연이 발생하며 채널 상태에 영향을 받음
즉, 시스템은 항상 다음 질문을 해야 한다.
이 작업을 로컬에서 처리할 것인가
아니면 Edge/Cloud로 Offloading 할 것인가?
이 문제는 Offloading Decision Problem이라고 불린다.
Binary Offloading vs Partial Offloading
Offloading 방식은 크게 두 가지로 나뉜다.
1. Binary Offloading
전체 작업을 로컬에서 실행하거나 원격 서버에서 실행하거나,
둘 중 하나를 선택한다.
이 구조는 단순하지만 유연성이 떨어진다.
2. Partial Offloading
작업을 여러 개의 subtask로 나누어 처리한다.
예를 들어 Task = {T1, T2, T3, T4}와 같다면, 다음과 같은 작업이 가능하다.
- T1 → Local
- T2 → Edge
- T3 → Edge
- T4 → Cloud
이 방식은 훨씬 유연하지만 문제는 훨씬 복잡해진다.
특히 대부분의 작업은 T1 → T2 → T3와 같은 DAG (Directed Acyclic Graph) 구조를 가진다. (Task dependency가 존재한다)
이 2가지 의사결정 방식에 따라 Offloading 의사결정과 작업 처리 과정은 다음과 같이 정리할 수 있다.

- 시나리오 1은 작업을 Offloading할 수 없는 경우를 보여준다.
이 경우 작업은 실행을 위해 우선순위 큐에 들어간다. - 시나리오 2는 작업 전체를 원격 서버로 Offloading할 수 있는 경우를 나타낸다.
이때 전체 작업은 원격 서버의 가상 머신(VM)이나 컨테이너에서 실행된다. - 시나리오 3과 4는 end device가 Partial Offloading을 선택한 상황을 보여준다.
이 경우 작업 분할(task partitioning)이 수행되며 원래 작업은 여러 개의 서브태스크로 나뉜다.
종단 장치는 어떤 부분을 Offloading하고 어떤 부분을 로컬에서 실행할지 결정해야 한다.- 시나리오 3에서는 일부 Subtask가 Local 실행을 위해 end device의 우선순위 큐로 이동한다.
- 시나리오 4에서는 일부 Subtask가 적절한 서버로 Offloading되어 실행된다.
왜 강화학습이 Offloading 문제를 풀 수 있는가?
Offloading 문제는 다음 특징을 가진다.
- 네트워크 상태가 시간에 따라 변함
- 사용자 요청이 동적으로 발생
- Edge 서버의 부하가 계속 변화
즉, 환경이 계속 변하는 의사결정 문제이다.
이러한 문제는 전통적인 최적화로 해결하기 어렵다.
대신 State → Action → Reward 형태의 Sequential Decision Making 문제로 모델링하여 MDP로 정리할 수 있다.
State : 채널 상태, Edge 서버 부하, 캐시 상태, 사용자 요청
Action : Local execution, Edge offloading, Cloud offloading, Cache placement
Reward : latency 감소, energy 감소, QoS 향상
이 구조는 강화학습 문제와 완전히 동일하다.
'딥러닝 모델 > DQN for Cloud-Edge Caching' 카테고리의 다른 글
| Edge Caching에서 풀 수 있는 Problem들 (Layer별 관점) (0) | 2026.03.12 |
|---|---|
| 모바일 Edge Caching의 개념과 강화학습의 필요성 (0) | 2026.03.12 |
| [강화학습 기초 13] Proximal Policy Optimization (PPO) (0) | 2026.03.11 |
| [강화학습 기초 12] Asynchronous Advantage Actor-Critic (A3C) (0) | 2026.03.11 |
| [강화학습 기초 11] Actor-Critic 알고리즘 총정리 (Q, Advantage, TD) (0) | 2026.03.09 |