딥마인드 DQN
Deep-Q Learning의 이론이 실제로 폭발적인 성과를 낸 순간이 바로 딥마인드의 DQN 논문이다.
2013년 발표된 “Playing Atari with Deep Reinforcement Learning”은 Q-Learning과 딥러닝을 결합해 아타리 게임을 인간 수준 이상으로 플레이하는 결과를 보여주었다.

기존 Q-Learning은 모든 Q(s,a)를 테이블에 저장해야 했다.
하지만 아타리 게임은 입력이 이미지로, 상태 공간이 사실상 무한에 가깝기 때문에 테이블 방식은 불가능하다.
DQN은 상태를 이미지 그대로 입력으로 받아, 신경망이 직접 Q값을 출력하도록 설계했다.
즉, 게임 화면 → 신경망 → 각 행동의 Q값 구조다.

논문 결과를 보면 학습이 진행될수록 두 가지가 함께 상승한다.
첫째는 Score, 즉 에피소드 동안 얻은 누적 보상이다.
둘째는 Average Action Value로, 선택된 행동들의 평균 Q값이다.
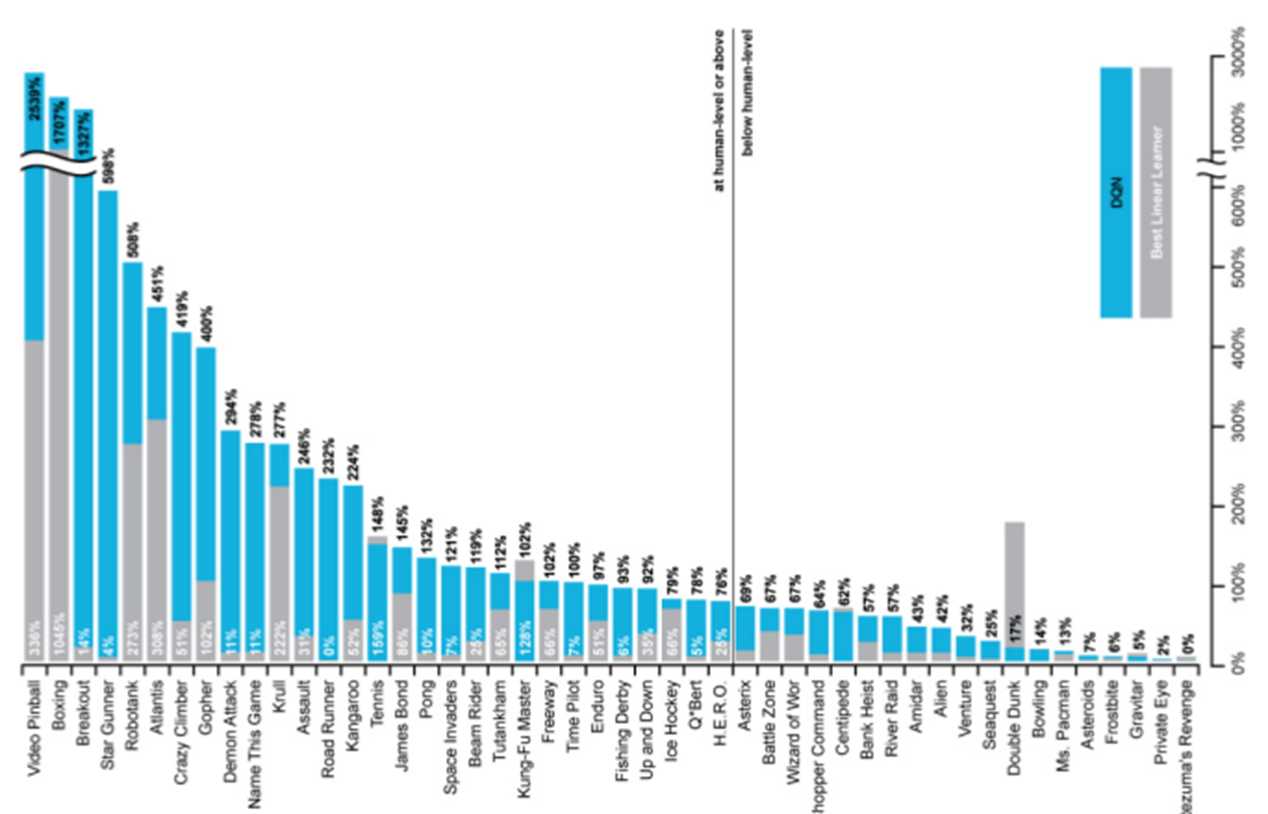
학습이 안정적으로 진행되면 Q값 예측이 점점 정교해지고, 실제 점수도 함께 증가한다.
또한 여러 게임에서 인간을 능가하는 성능을 보였고, 단 하나의 알고리즘으로 49개 게임을 처리했다는 점이 핵심이다.
DQN의 핵심 아이디어
DQN은 기본적으로 다음 구조를 따른다.
- 현재 상태 s를 입력한다.
- 신경망이 각 행동의 Q값을 출력한다.
- 가장 큰 Q값을 가진 행동을 선택한다.
- 보상 r과 다음 상태 s′를 관측한다.

- 벨만 최적 방정식에 따라 target을 만든다.
- 현재 Q값과 target의 차이를 줄이도록 학습한다.
즉 Deep-Q Learning의 이론을 그대로 구현한 것이라고 할 수 있다.
DQN의 구현 : CartPole 예제
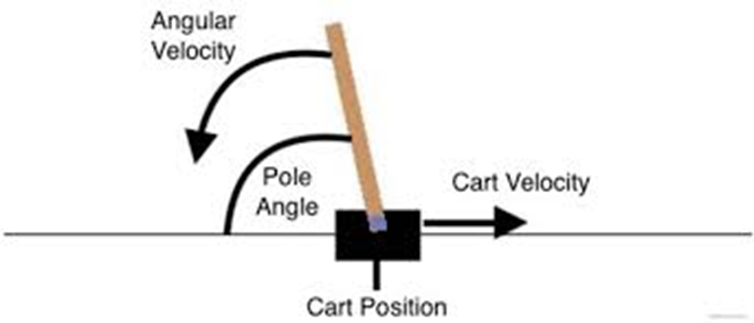
CartPole은 막대기를 쓰러뜨리지 않도록 카트를 좌우로 움직이는 문제다.
상태는 4차원 벡터(카트 위치/속도, 막대 각도/각속도)이며, 행동은 좌/우 두 가지다.
한 스텝 버틸 때마다 보상 1점을 받는다.
DQN의 핵심 라이브러리


gym은 환경을 가져오기 위해 필요한 라이브러리이다.
collections는 뒤에서 다룰 replay_buffer를 구현하기 위해 필요하다.
hyperparameter는 학습이 잘 되는 적절한 값을 찾으면 된다.
이때 buffer_limit은 replay buffer의 사이즈를 나타낸다.
Q Network 구조


입력 차원은 4, 출력 차원은 2이다.
Hidden layer로 128개 노드를 가진 Fully Connected Layer 두 개와 ReLU function를 사용한다.
구조는 다음과 같다: 4 → 128 → 128 → 2
Layer의 개수, 혹은 노드 수를 바꿀수록 학습 성능이 달라지게 된다.
출력은 두 행동의 Q값이다.
이때 딥러닝 네트워크를 정의할 때는 torch.nn의 nn.Module을 상속받아 클래스를 만들면 이것이 뉴럴넷이 된다.
뒤의 forward 함수는 linear combination과 non-linear activation을 2번 수행하고 마지막에 최종 q_value를 리턴한다.
sample_action은 epsilon greedy를 적용한다.
coin toss(0~1 사이의 랜덤한 실수)를 해서 epsilon보다 작으면 랜덤하게 두 액션 중 하나를 고르고,
epsilon보다 크면 가장 value가 컸던 액션을 고른다.
Loss 함수
DQN의 Loss는 TD target과 현재 Q값의 차이다.

코드에서는 smooth_l1_loss를 사용해 더 안정적으로 학습한다.

target = r + gamma * max_q_prime (max q’) * done mask로 설정된다.

max_q_prime은 q_target 네트워크를 가져와서 s_prime(s')을 넣었고,
그럼 s'에서 할 수 있는 action들에 대한 q_value들이 나왔을 것이다.
그 중 가장 좋은 값을 max()로 구하는 것이다.
max(1)[0]은 인덱싱을 해주는 부분, max operator를 하면 list 형태로 값과 index가 같이 나오기 때문!
unsqueeze는 minibatch가 있기 때문에 차원을 맞춰주기 위해 필요하다.
DQN의 기술적 Technique
1. Experience Replay (리플레이 버퍼)
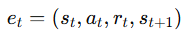
강화학습에서는 데이터가 시간 순서대로 생성된다.
만약 이 데이터를 생성된 순서대로 바로 학습에 사용하면 어떤 문제가 생길까?
- 연속된 데이터는 서로 강하게 상관되어 있다.
- 최근 경험에만 과도하게 영향을 받는다.
- 신경망이 특정 패턴에 과적합될 수 있다.
이를 해결하기 위해 등장한 것이 Replay Buffer다.
Replay Buffer의 아이디어는 다음과 같다.
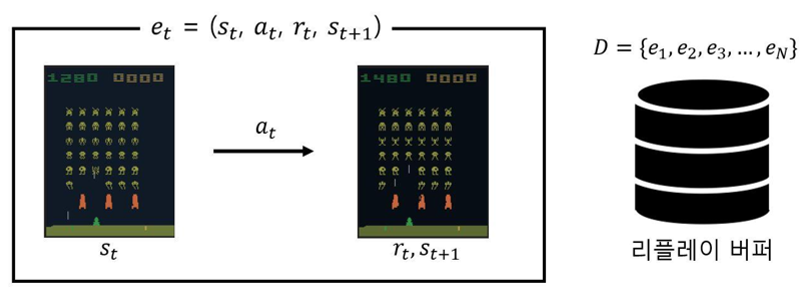
- 경험을 buffer에 저장한다.
- 학습할 때는 무작위로 mini-batch를 샘플링한다.
- 과거 경험을 반복 재사용한다.
이 방식은 두 가지 효과를 만든다.
- 데이터 상관성을 줄인다.
- 샘플 효율을 높인다.
또한 DQN은 off-policy 알고리즘이기 때문에 과거 정책으로 모은 데이터도 사용할 수 있다.
이것이 Replay Buffer가 가능한 이유다.
ReplayBuffer 함수를 살펴보면,

- ReplayBuffer는 버퍼에 넣는 것(put),
- 버퍼에서 뽑는 것(sample),
- 버퍼의 크기(size)로 구성된다.
- put 함수에서 transition은 (s, a, r, s’)의 pair를 말한다.(s에서 a를 했더니 리워드 r을 받아 s’에 도착)
- 그럼 collection의 deque(FIFO)으로 buffer를 관리한다.
- sample(self, n) 하면 buffer 중 랜덤하게 n개를 골라 뽑아준다.
- random.sample로 mini_batch가 구성되고, for loop을 돌면서 s, a, r, s_prime끼리 모아서 tensor로 바꿔서 리턴한다.
- size는 현재 buffer에 아이템이 몇 개 들어와 있는지를 나타낸다.
2. Target Network (타깃 네트워크)

다음 문제는 TD target 자체가 움직인다는 점이다.
DQN의 Loss는 다음과 같다.
그런데 여기서 오른쪽 Q(s',a')도 같은 네트워크라면 어떻게 될까?
- 예측값이 바뀌면
- target도 동시에 바뀐다.
- 즉, 정답이 계속 도망간다.
이 때문에 학습이 매우 불안정해진다.
이를 위한 해결책으로 네트워크를 두 개 둘 수 있다.
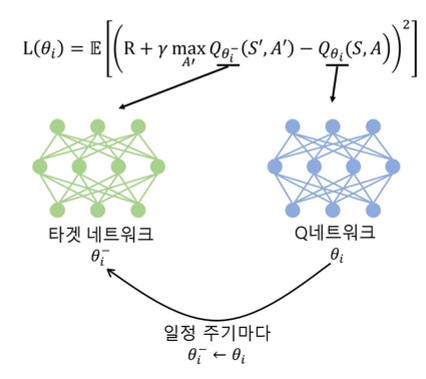
- Q Network (학습 대상)
- Target Network (정답 계산용, 고정)
Target Network는 일정 주기마다 Q Network의 가중치를 복사한다.
즉, target은 일정 시간 동안 고정된 기준이 된다.
DQN의 main 함수

이제 main 코드로 넘어갈 차례이다.
일단 CartPole-v1에 해당하는 env 객체를 생성한다.
그 다음으로 Target Network Technique를 쓰기 위해 Class의 instance를 2개를 만든다. (q, q_target)
q_target은 q에 있는 애를 주기적으로 복사해온다. (load_state_dict)
Replay Buffer Technique를 위해 memory라는 ReplayBuffer를 만든다.
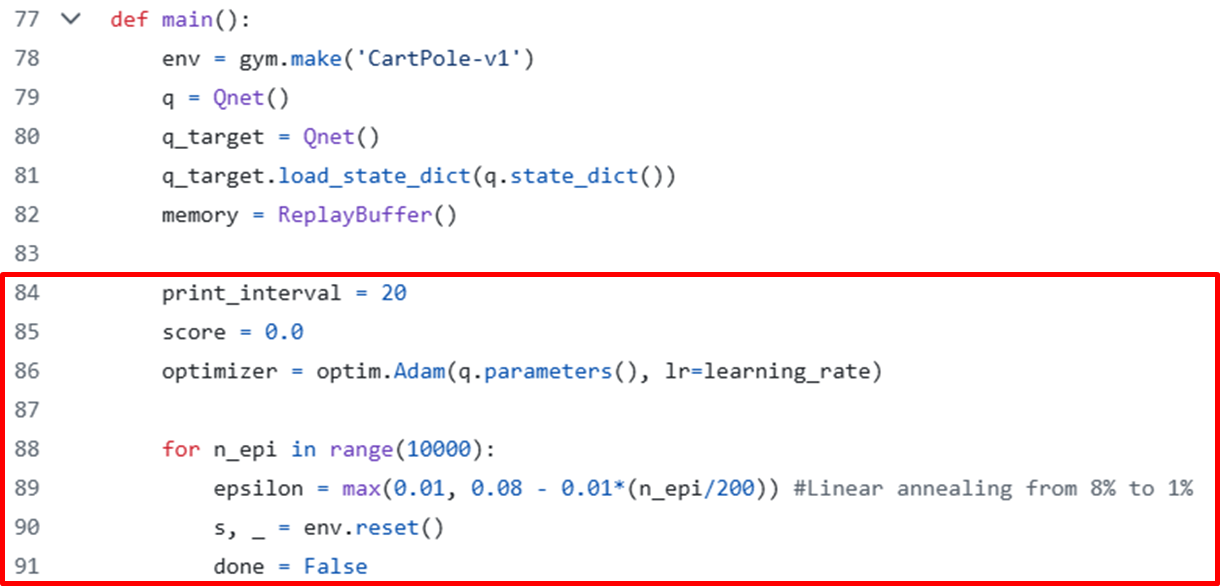
optimizer는 q_target의 파라미터가 아닌 q의 파라미터만 학습한다. (q_target의 파라미터는 q에 있는 것을 불러오면 되니까)
(실제로 q_target이 print_interval마다 불러오도록 뒤에서 구현되어 있다)
그 뒤 경험을 쌓는 for loop으로 넘어간다.
이 epsilon 부분은 Exploration과 Explitation의 균형을 맞추는 부분이다.
이 부분은 DQN에서도 Exploration과 Exploitation의 균형을 맞추기 위한 부분으로, ε-greedy 전략을 사용한다.

일정 확률 ε로는 무작위 행동을 선택해 새로운 정보를 탐험하고, 나머지 확률로는 가장 큰 Q값을 선택한다.
여기에서는 epsilon을 처음에는 0.08 정도로 크게 하다가 0.01로 점점 줄어들도록 한다.
학습이 진행될수록 ε를 점점 줄여 탐험을 줄이고 활용을 늘리는 구조이다.
위 trade-off 관계 사이의 sweet spot을 찾아야 함.

이후 환경을 리셋하고 하나의 에피소드가 뒤쪽의 while문에서 일어난다.
a = q.sample_action으로 action을 하나 고르고, env.step(a)에서 action을 수행한다.
그럼 다음 상태(s_prime)와 리워드(R), 에피소드 종료 여부(done)를 반환한다.
(done은 맨 마지막 상태의 value를 0으로 만들기 위해 기록해야 하는 정보)
그 다음 transition 하나를 메모리에 저장을 한다.
r을 100으로 나눠준 이유는 학습의 안정성을 위해서이다. (보통 리턴의 합이 10 미만이 되도록 잡아준다)
이 while loop에서 step을 수행하다가 while문이 종료되면 하나의 에피소드가 끝난다.

에피소드가 끝나면 학습 함수인 train 함수를 호출한다.
이때 Replay Buffer에 샘플이 2000개 이상 쌓여야 학습을 한다.
만약 샘플이 부족하다면 학습하지 않고 바로 다음 에피소드로 넘어간다. (에피소드는 총 10000번 진행)
중간중간 점수를 출력하면서 q_target을 update 해준다.
시뮬레이션 결과

200점이 넘으면 훌륭한 스코어로 볼 수 있는데, 처음엔 스코어가 10점 정도에서 머물다가,
에피소드가 반복될수록 score가 점차 커짐을 확인할 수 있다.
그 이유는 코드상에서 Replay Buffer내의 샘플이 2000개가 넘어가기 전까지는 (에피소드 200) 학습이 일어나지 않기 때문이다.
에피소드 200 이후부터는 score가 굉장히 빠르게 증가한다.
n_episode는 지금까지 경험한 에피소드의 수이다.
epsilon 값도 코드대로 8%에서 점차 줄어듦을 확인할 수 있다.
전체 코드
!pip install numpy==1.23.5
import gym
import collections
import random
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
#Hyperparameters
learning_rate = 0.0005
gamma = 0.98
buffer_limit = 50000
batch_size = 32
class ReplayBuffer():
def __init__(self):
self.buffer = collections.deque(maxlen=buffer_limit)
def put(self, transition):
self.buffer.append(transition)
def sample(self, n):
mini_batch = random.sample(self.buffer, n)
s_lst, a_lst, r_lst, s_prime_lst, done_mask_lst = [], [], [], [], []
for transition in mini_batch:
s, a, r, s_prime, done_mask = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
done_mask_lst.append([done_mask])
return torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_mask_lst)
def size(self):
return len(self.buffer)
class Qnet(nn.Module):
def __init__(self):
super(Qnet, self).__init__()
self.fc1 = nn.Linear(4, 128)
self.fc2 = nn.Linear(128, 128)
self.fc3 = nn.Linear(128, 2)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def sample_action(self, obs, epsilon):
out = self.forward(obs)
coin = random.random()
if coin < epsilon:
return random.randint(0,1)
else :
return out.argmax().item()
def train(q, q_target, memory, optimizer):
for i in range(10):
s,a,r,s_prime,done_mask = memory.sample(batch_size)
q_out = q(s)
q_a = q_out.gather(1,a)
max_q_prime = q_target(s_prime).max(1)[0].unsqueeze(1)
target = r + gamma * max_q_prime * done_mask
loss = F.smooth_l1_loss(q_a, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
def main():
env = gym.make('CartPole-v1')
q = Qnet()
q_target = Qnet()
q_target.load_state_dict(q.state_dict())
memory = ReplayBuffer()
print_interval = 20
score = 0.0
optimizer = optim.Adam(q.parameters(), lr=learning_rate)
for n_epi in range(10000):
epsilon = max(0.01, 0.08 - 0.01*(n_epi/200)) # Exploration과 Exploitation
# Linear annealing from 8% to 1%
s = env.reset()
done = False
while not done:
a = q.sample_action(torch.from_numpy(s).float(), epsilon)
s_prime, r, done, info = env.step(a)
done_mask = 0.0 if done else 1.0
memory.put((s,a,r/100.0,s_prime, done_mask))
s = s_prime
score += r
if done:
break
if memory.size()>2000:
train(q, q_target, memory, optimizer)
if n_epi%print_interval==0 and n_epi!=0:
q_target.load_state_dict(q.state_dict())
print("n_episode :{}, score : {:.1f}, n_buffer : {}, eps : {:.1f}%".format(
n_epi, score/print_interval, memory.size(), epsilon*100))
score = 0.0
env.close()
if __name__ == '__main__':
main()
출처 : 노승은 강사님의 "바닥부터 배우는 강화학습"
바닥부터 배우는 강화 학습 | 노승은 - 교보문고
바닥부터 배우는 강화 학습 | 강화 학습 기초 이론부터 블레이드 & 소울 비무 AI 적용까지 이 책은 강화 학습을 모르는 초보자도 쉽게 이해할 수 있도록 도와주는 입문서입니다. 현업의 강화 학습
product.kyobobook.co.kr
'딥러닝 모델 > DQN for Cloud-Edge Caching' 카테고리의 다른 글
| [강화학습 기초 10] Policy Gradient와 REINFORCE 알고리즘 구현 (0) | 2026.03.04 |
|---|---|
| [강화학습 기초 9] Policy 기반 강화학습과 Policy Gradient 이론 (Value 기반 vs Policy 기반) (0) | 2026.03.04 |
| [강화학습 기초 7] Deep Reinforcement Learning의 핵심 (Value Network와 Deep-Q Learning) (0) | 2026.03.03 |
| [강화학습 기초 6] Temporal Difference를 통한 step 기반 가치 평가 (MDP를 모를 때) (0) | 2026.03.03 |
| [강화학습 기초 5] Monte Carlo를 통한 에피소드 기반 가치 평가 (MDP를 모를 때) (0) | 2026.03.02 |