강화학습의 대부분 알고리즘은 결국 value를 어떻게 정의하고 계산하느냐에서 출발한다.
현재 상태가 얼마나 좋은지를 알아야, 이후 어떤 행동을 선택해야 할지 결정할 수 있기 때문이다.
이러한 value 계산의 이론적 뼈대를 제공하는 수식이 바로 벨만 방정식이다.
여기에서는 벨만 기대 방정식과 벨만 최적 방정식을 단계적으로 유도하고,
왜 이런 형태가 나오는지 재귀적 구조와 확률적 해석 관점에서 정리한다.
벨만 기대 방정식 0단계 : Value의 정의에서 출발하기
강화학습에서 상태 가치 함수는 다음과 같이 정의된다.

여기서 Gt는 리턴(Return), 즉 미래 보상의 누적 합이다.
이를 전개하면 아래와 같이 된다.
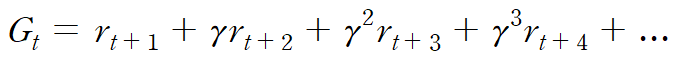

여기서의 핵심은 다음과 같은 재귀적 구조에 있다.
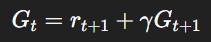
이 식을 기대값 정의에 대입하면,

이것이 벨만 기대 방정식을 유도하기 위한 가장 기본적인 형태다.
여기서 반드시 기대값 (E)가 들어가야 한다.
동일한 상태에서 시작하더라도, 에피소드마다 다음 보상과 다음 상태는 달라질 수 있기 때문이다.
이는 정책에 의한 확률성과 환경 전이 확률이라는 두 가지 stochastic 요소 때문이다.

벨만 기대 방정식 1단계 : Qπ와 Vπ의 상호 표현하기
1-1단계: q_π를 이용해 v_π 표현하기
상태 s의 가치는 그 상태에서 선택 가능한 모든 행동의 가치의 평균이다.
단, 단순 평균이 아니라 정책에 따른 확률 가중 평균이다.

이는 “현재 상태의 가치는, 그 상태에서 각 행동을 선택할 확률 × 그 행동의 가치”를 모두 더한 것이라는 의미다.

1-2단계: q_π를 이용해 v_π 표현하기
이제 반대로, 행동 가치 함수는 다음과 같이 정의된다.

즉, 행동 가치 함수는
- 현재 행동을 했을 때의 즉시 보상
- 다음 상태로 전이될 확률 × 다음 상태의 가치
를 모두 더한 것이다.
여기서 중요한 점은 전이 확률 P는 환경이 결정한다는 점이다.
정책은 행동 선택에만 관여하고, 그 이후의 상태 전이는 환경의 확률적 특성에 의해 결정된다.
벨만 기대 방정식 2단계 : 벨만 기대 방정식 유도
앞의 두 식을 합치면 다음과 같은 두 식이 나온다.

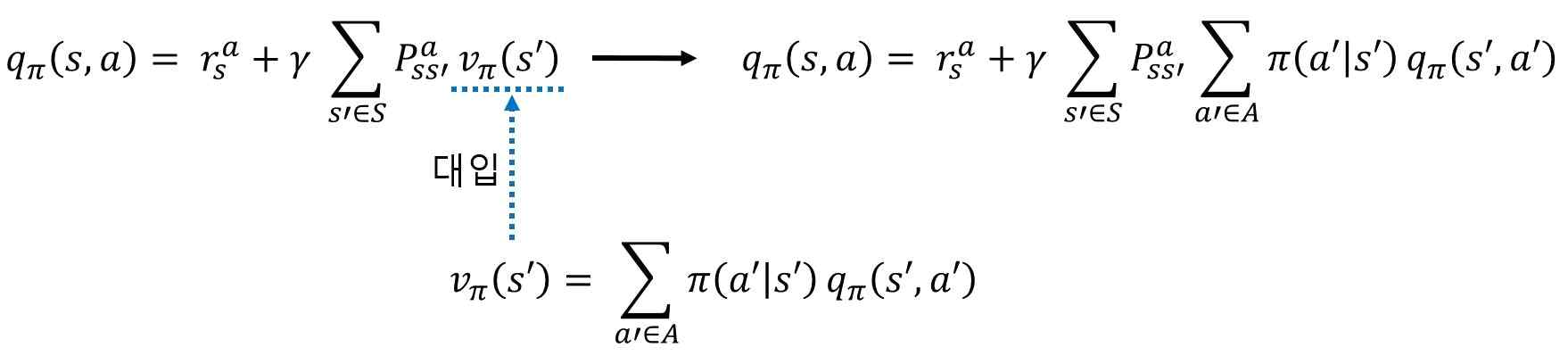
이것이 전이 확률을 명시한 벨만 기대 방정식의 완성형이다.
위 과정을 정리하면 정리하면 아래와 같다.

- 0단계: 전이 확률을 모를 때의 재귀 형태
- 1단계: v_와 q_의 상호 표현
- 2단계: MDP의 전이 확률을 명시한 완전한 형태
벨만 최적 방정식 0단계 : 최적 가치의 정의
벨만 최적 방정식에서는 이제 정책이 아니라 “최적 정책”을 고려한다.
최적 방정식은 모든 정책 중 가장 좋은 정책을 따랐을 때의 가치 (= optimal value)에 대한 식인데,
이때 *가 optimal value를 나타내는 표지다.
이는 아래와 같이 정의된다.

각 기호의 의미는 다음을 나타낸다.

벨만 최적방정식 0단계는 아래와 같이 표현된다.
벨만 기대 방정식과 달라진 점은 max 연산자가 생긴다는 것이다.
그리고 Expectation 안에 정책 (=π)가 없다. (= 정책에 대한 가중평균이 사라진다)
그 외 큰 틀은 기대방정식과 유사하다.
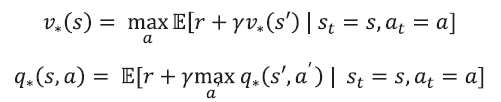
위 식의 의미는 s의 최적 value (v*)는 당장의 리워드를 하나 받고, 그 다음 상태의 value의 기댓값 중 가장 높은 것을 의미한다.
벨만 기대 방정식에서는 π가 있었는데 여기서는 그 대신에 기댓값 연산자가 들어갔다.
원래 π에 의해 action을 고르고, 전이확률에 의해 다음 상태가 정해진 것과 달리,
벨만 최적 방정식에서는 π에 의해 action을 고르지 않고, 단지 할 수 있는 action 중 가장 좋은 것을 고르게 된다.
그 결과 수식에서 π가 존재할 이유가 없다 (= 최적의 a를 이용해 가장 높은 v를 구하기 때문)
그럼에도 여전히 기댓값 연산자가 필요한 이유는,
π에 의한 Expectation을 불필요하더라도 환경에 의한 확률분포는 여전히 존재하기 때문이다.
벨만 최적 방정식 1단계 : v*와 q* 이해하기
벨만 기대방정식과 마찬가지로 2단계 수식은 1단계 수식 2개를 조합해서 만드는 수식이다.
따라서 핵심은 1단계를 잘 이해하는 것이다.
1-1단계 : q*를 이용해 v* 구하기

위 식은 q*를 알 때 v*를 계산하는 방법이다.
벨만 기대 방정식과 달리 weighted sum을 하지 않는데, 각 action을 선택할 확률과 무관하게 더 큰 action value를 구하면 그것에 optimal value가 되기 때문이다.

여기서 다음과 같은 의문이 들 수 있다.
당장은 a1의 actio value가 1, a2의 action value가 2로, a1이 더 낮지만,
그 뒤의 과정에 의해 종합적으로 a1의 action value가 더 좋아질 수도 있지 않나?
이건 오해이다. q*의 값은 이미 최종 episode의 끝까지를 모두 고려한 것이다.
따라서 q*는 현재 상태 s에서 a1을 고르고, 그 뒤에 어떤 policy pile을 따라서 MDP를 끝까지 갔을 때의 얻을 수 있는 value 중 가장 좋은 것을 고른 상태이다.
1-2단계 : v*를 이용해 q* 구하기
이제 반대로 v*를 이용해 q*를 구하는 수식이다.
s에서 a를 선택했을 때의 optimal value는 우선 a를 선택했을 때의 리워드를 받고,
그 다음 상태에 도달하게 되는 optimal value들의 확률의 곱과 같다.

여기서는 기대방정식처럼 확률을 weighted sum을 하고 있는데, 그 이유는 action은 내가 가장 좋은 policy를 선택할 수 있지만,
그 action으로 인해 내가 어떤 state로 도달할지는 환경이 가지는 특성으로, P에 의해 결정되기 때문이다.
벨만 최적 방정식 2단계 : Q-learning의 핵심 함수 유도하기
이제 1단계의 수식을 대입하면 가장 간단하게 2단계 수식을 유도할 수 있다.


이 중 q*에 해당하는 두 번째 식은 뒤에서 나올 Q-learning과 Deep Q-Network(DQN)의 이론적 기반이 된다.
벨만 방정식의 의미
벨만 방정식의 핵심은 다음으로 요약된다.
- 현재의 가치는, 즉시 보상 + 할인된 미래 가치이다.
- 그리고 그 미래 가치는 다시 동일한 구조를 가진다.
즉, 벨만 방정식은 가치 함수의 자기 자신에 대한 재귀적 정의다.
강화학습이 가능한 이유는 바로 이 재귀 구조 덕분이다.
미래 전체를 직접 계산하지 않아도, 한 단계 앞만 고려하는 식으로 문제를 분해할 수 있기 때문이다.
정리
- 벨만 기대 방정식은 주어진 정책 하에서의 가치 재귀식이다.
- 벨만 최적 방정식은 최적 정책을 가정한 가치 재귀식이다.
- 기대 연산자는 환경의 확률성을 처리하기 위해 필요하다.
- max 연산자는 최적 행동 선택을 의미한다.
- Q-learning은 벨만 최적 방정식의 반복적 근사 과정이다.
'딥러닝 모델 > DQN for Cloud-Edge Caching' 카테고리의 다른 글
| [강화학습 기초 6] Temporal Difference를 통한 step 기반 가치 평가 (MDP를 모를 때) (0) | 2026.03.03 |
|---|---|
| [강화학습 기초 5] Monte Carlo를 통한 에피소드 기반 가치 평가 (MDP를 모를 때) (0) | 2026.03.02 |
| [강화학습 기초 4] Dynamic Programming 기반 Solution (MDP를 알 때) (0) | 2026.03.01 |
| [강화학습 기초 2] Markov Decision Process (0) | 2026.02.27 |
| [강화학습 기초 1] 강화학습의 핵심 개념 (에이전트, 환경, 리워드) (0) | 2026.02.27 |