지도학습과 강화학습
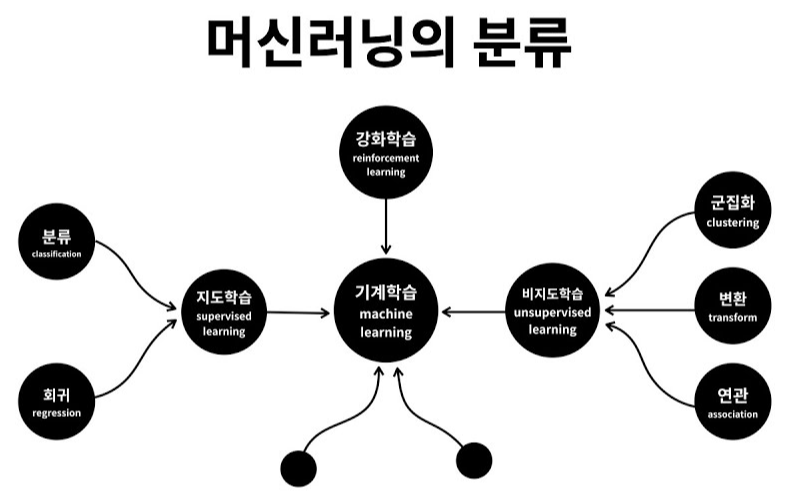
기계학습 (Machine Learning)은 크게 지도학습(Supervised Learning), 비지도학습(Unsupervised Learning),
그리고 강화학습(Reinforcement Learning)으로 구분된다.
지도학습은 정답(label)이 주어진 데이터를 기반으로 입력과 출력의 매핑을 학습한다.
이 방식은 기존 데이터 분포와 정답 품질에 강하게 의존하며, 본질적으로 지도자의 성능을 크게 뛰어넘기 어렵다는 한계를 가진다.
즉, 모델의 upper bound가 데이터에 의해 사실상 제한된다.
반면 강화학습은 명시적인 정답이 존재하지 않는다.
대신 에이전트가 환경과 상호작용하며 시행착오(trial-and-error)를 통해 전략을 학습한다.
이 과정에서는 특정 정답을 모방하는 것이 아니라, 장기적인 성과를 극대화하는 방향으로 스스로 정책을 개선한다.
따라서 이론적으로 성능의 upper bound가 고정되어 있지 않다.
만약 AlphaGo가 순수 지도학습 기반이었다면 인간 기보를 모방하는 수준을 넘기 어려웠을 것이다.
하지만 강화학습을 통해 스스로 새로운 전략을 탐색하면서 인간을 능가하는 성능에 도달했다.
이것이 강화학습의 근본적인 차별점이다.
순차적 의사결정 문제
강화학습은 본질적으로 순차적 의사결정 문제(Sequential Decision Making Problem)를 해결하는 방법론이다.
직관적으로 강화학습은 다음과 같이 설명할 수 있다.
“일단 행동해보고,
결과가 좋으면 더 하고,
나쁘면 덜 하는 과정”
이를 보다 엄밀하게 정의하면 다음과 같다.
“순차적 의사결정 문제에서,
누적 보상을 최적화하기 위해,
시행착오를 통해 행동을 교정하는 과정”

여기서 핵심은 ‘순차적’이라는 점이다.
현재의 행동은 미래의 상태와 보상에 영향을 미친다.
즉, 단발성 예측이 아니라 시간에 걸친 의사결정의 연쇄를 다룬다.
대표적인 예시는 다음과 같다.
- 주식 투자: 현재의 매수/매도 결정이 미래 자산에 영향을 준다.
- 게임 플레이: 한 수의 선택이 이후 게임 흐름을 바꾼다.
- 자율주행: 현재 조향과 가속 결정이 미래 위치와 안전성에 영향을 준다.
강화학습은 이러한 문제를 수학적으로 모델링하고, 장기적인 관점에서 최적의 전략을 찾는다.
리워드 (Reward)
강화학습에서 가장 중요한 개념은 리워드(Reward)이다.
리워드의 가장 중요한 특징을 정리하면 다음과 같다.
1) 리워드는 ‘어떻게’가 아니라 ‘얼마나’이다
리워드는 행동이 옳았는지 그 자체를 직접 알려주지 않는다.
단지 결과가 좋았는지, 그리고 얼마나 좋았는지를 수치로 표현한다.
즉, 리워드는 명령이나 설명이 아니라 평가 점수에 가깝다.
에이전트는 이 스칼라 신호만을 기반으로 정책을 개선해야 한다.
2) 리워드는 스칼라 값이다
리워드는 일반적으로 하나의 실수 값(scalar)으로 주어진다.
좋은 결과에는 큰 값, 나쁜 결과에는 작은 값(혹은 음수)이 부여된다.
강화학습의 목표는 다음을 최대화하는 것이다.
Expected Cumulative Reward (기대 누적 보상)
즉, 단기적인 보상이 아니라 장기적으로 누적된 보상의 기대값을 최대화하는 것이 목적이다.
3) 리워드는 희소하고 지연될 수 있다
현실 세계의 많은 문제에서 리워드는 다음과 같은 특징을 가진다.
- Sparse: 자주 주어지지 않는다.
- Delayed: 행동 직후가 아니라 한참 뒤에 주어진다.
예를 들어 체스에서는 중간에 점수가 주어지지 않고, 승패가 결정되는 순간에만 보상이 주어진다.
이 경우 어떤 행동이 최종 결과에 기여했는지 추적하는 것이 어려워진다.
이를 신용할당 문제(Credit Assignment Problem)라고 한다.
강화학습의 철학적 기반 : Reward Hypothesis
강화학습의 철학적 기반은 Reward Hypothesis이다.
이 철학의 핵심은 모든 목표는 기대 누적 보상을 최대화하는 문제로 표현 가능하다는 것이다.
만약 어떤 문제를 보상 함수로 정식화할 수 없다면, 강화학습을 적용하기 어렵다.
따라서 강화학습에서 가장 중요한 설계 요소는 알고리즘이 아니라 ‘보상 설계’인 경우가 많다.
에이전트와 환경
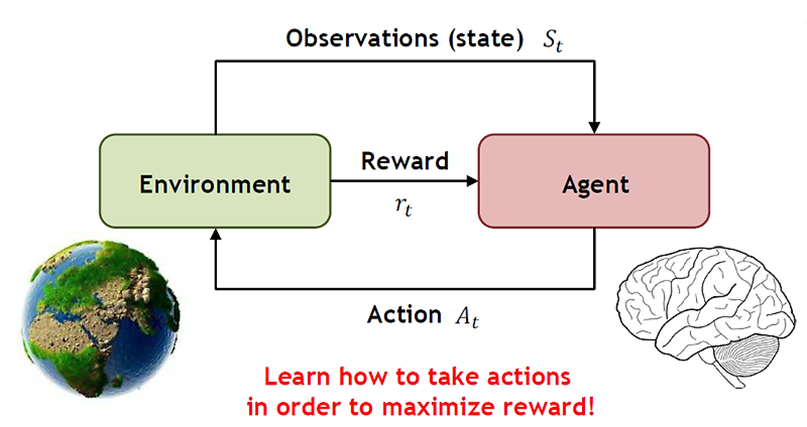
강화학습은 에이전트(Agent)와 환경(Environment)의 상호작용으로 정의된다.
- 강화학습에서는 에이전트(agent)가 환경(environment) 속에서,
- 상태(state)를 관찰하고,
- 행동(action)을 선택하고,
- 그 결과로 보상(reward)을 받는 과정을 계속 반복하게 된다.
- 이 과정이 순차적으로 여러 step에 걸쳐 일어난다. (→ 순차적 의사결정 문제!)
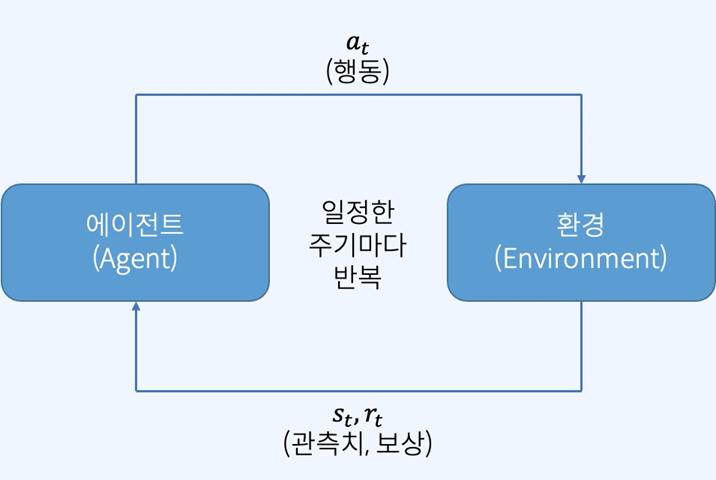
이 상호작용을 수학적으로 표현하면 아래와 같다.
시간 t에서:
- 에이전트는 환경으로부터 상태 s_t와 보상 r_t를 받는다.
- 이를 바탕으로 행동 a_t를 선택한다.
- 행동은 환경에 전달된다.
- 환경은 상태를 s_{t+1}로 전이시키고,
- 새로운 보상 r_{t+1}과 상태 s_{t+1}를 에이전트에게 전달한다.
이 루프가 반복되면서 학습이 이루어진다.
에이전트의 유형

강화학습 에이전트는 크게 세 가지로 구분된다.
- Value-Based
각 행동의 가치를 추정하고, 가장 가치가 높은 행동을 선택한다.
대표적으로 Q-learning 계열이 있다. - Policy-Based
행동의 확률분포를 직접 모델링한다.
각 행동을 확률적으로 샘플링하여 탐색을 수행한다. - Actor-Critic
정책(Actor)과 가치 평가기(Critic)를 동시에 사용한다.
Critic이 Actor의 정책을 평가하고, 그 평가를 바탕으로 정책이 업데이트된다.
최근의 많은 고성능 알고리즘이 이 구조를 따른다.
Exploitation vs Exploration
강화학습의 본질적인 딜레마는 Exploration과 Exploitation의 균형이다.

- Exploration: 새로운 정보를 얻기 위해 모험적인 행동을 한다.
- Exploitation: 이미 알고 있는 최선의 전략을 활용한다.
Exploration이 부족하면 더 나은 전략을 발견하지 못한다.
Exploitation이 부족하면 이미 좋은 전략을 충분히 활용하지 못한다.
강화학습은 이 두 가지 사이의 trade-off에서 최적의 균형점을 찾는 과정이다.
ε-greedy, Boltzmann exploration, UCB 등 다양한 기법들이 이 균형을 조정하기 위해 제안되었다.
'딥러닝 모델 > DQN for Cloud-Edge Caching' 카테고리의 다른 글
| [강화학습 기초 6] Temporal Difference를 통한 step 기반 가치 평가 (MDP를 모를 때) (0) | 2026.03.03 |
|---|---|
| [강화학습 기초 5] Monte Carlo를 통한 에피소드 기반 가치 평가 (MDP를 모를 때) (0) | 2026.03.02 |
| [강화학습 기초 4] Dynamic Programming 기반 Solution (MDP를 알 때) (0) | 2026.03.01 |
| [강화학습 기초 3] 벨만 방정식(Bellman Equation) 유도하기 (0) | 2026.03.01 |
| [강화학습 기초 2] Markov Decision Process (0) | 2026.02.27 |