강화학습이 순차적 의사결정 문제를 푸는 방법론이라면,
Markov Decision Process(MDP)는 그 문제를 수학적으로 정의하는 틀이다.
강화학습 알고리즘은 모두 어떤 형태로든 MDP 위에서 동작한다.
즉, 우리가 풀고자 하는 문제를 MDP 형태로 정식화할 수 있어야 강화학습을 적용할 수 있다.
MDP의 구성요소에는 S(상태), P(상태 전이 확률), R(보상), γ (할인율), A(행동)이 있다.
이 글에서는 Markov Process에서 시작해 Markov Reward Process를 거쳐,
Markov Decision Process까지 단계적으로 정리한다.
Markov Process
(MDP의 구성 요소 5가지 중 : S(상태), P(상태 전이 확률), R(보상), 𝛾(할인율), A(행동))
1) Markov Process란 무엇인가
아래는 대학생의 생활패턴을 Markov Process로 도식화한 것이다.
학생은 Facebook 상태에서 90%의 확률로 Facebook을 하지만, 10%의 확률로 class1으로 갈수도 있다.
class1에서는 50%의 확률로 Facebook을 하거나, 50%의 확률로 class2로 이동한다.
class2에서는 20%의 확률로 Sleep을 하거나, 80%의 확률로 class3으로 이동한다.
class3에서는 40%의 확률로 Pub을 가거나, 60%의 확률로 Pass를 거쳐 Sleep으로 이동한다.
Pub에서는 40%의 확률로 다시 class2로 돌아가거나, 40%의 확률로 class3로 돌아가거나, 20%의 확률로 class1으로 향한다.

Markov Process(MP)는 상태(State)와 상태 전이 확률로 구성된 가장 단순한 확률 과정이다.
시간이 한 step 진행될 때마다 상태가 확률적으로 변한다.
중요한 점은, 이 과정에는 의사결정이 없다. 단지 확률에 따라 상태가 변할 뿐이다.
이를 직관적으로 표현하면 바다 위에서 보트 하나로 떠다니는 상황이라고 할 수 있다.
어디로 갈지는 오직 확률에 의해 결정된다. 주체적인 선택은 없다.
Terminal State는 더 이상 상태 전이가 일어나지 않는 종료 상태이다.
위에서는 Sleep가 Terminal State이며, 여기에 도달하면 모든 과정이 끝난다.
Markov Process의 두 요소
Mrkov Process는 다음과 같은 2개의 요소로 정의된다.


전이확률을 행렬로 표현하면 n×n 행렬이 된다.
각 행의 합은 1이며, 이는 어떤 상태에서든 다음 상태로의 확률 합이 1이라는 의미이다.
Markov Property
모든 Markov 계열 모델의 핵심은 Markov Property이다.
미래는 오직 현재 상태에만 의존한다.
즉, 과거 전체가 아니라 현재 상태 하나로 미래를 설명할 수 있어야 한다.
이를 수식으로 표현하면 아래와 같다.

체스 게임을 생각해보자.
현재 체스판의 상태만 알면 다음 수를 계산할 수 있으며 과거에 어떤 경로로 그 상태에 도달했는지는 중요하지 않다.
오직 현재의 상태에 따라 미래를 설명할 수 있으므로 체스는 Markov하다.

반면, 자율주행에서 카메라 이미지 한 장만 본다면 현재 차량이 전진 중인지 후진 중인지 알 수 없다.
이 경우 Markov하지 않다.
하지만 t, t-1, t-2, t-3 시점의 연속 이미지가 있다면 상태는 더 Markov해진다.

정리하면, Markov성은 스펙트럼과 같다고 할 수 있다.
정보가 충분히 요약되어 있다면 Markov, 그렇지 않다면 비-Markov이다.
Markov Reward Process
(MDP의 구성 요소 5가지 중 : S(상태), P(상태 전이 확률), R(보상), 𝛾(할인율), A(행동))
Markov Process에 보상이 추가되면 Markov Reward Process(MRP)가 된다.
여기서는 각 State에 도달할 때마다 Reward가 추가된다.
Facebook 상태에만 계속 있게 되면 Reward는 -1점씩 누적된다.
각 class에 도달할 경우 -2점씩 누적되지만, 모든 수업을 다 들을 경우 10점의 Reward를 얻는다.
Pub에서는 1점의 Reward를 얻을 수 있다.

MRP에서는 MP에 비해 2개의 요소가 추가된다.

Reward(R) vs Return(G) (+ γ의 의미)
Reward는 특정 시점에 받는 즉시 보상이다.
그런데 γ는 무엇일까?
γ를 알기 위해서는 Return이 무엇인지를 알아야 된다.
Return은 미래 보상의 감쇠된 합으로, 뒤의 value function을 정의하기 위한 핵심 개념이다.
만약 MRP의 s0에서 r1을 받고 s1에 도달한 다음, r2를 받고 s2에 도달하는 에피소드를 생각해보자.
이는 다음과 같은 수식으로 표현할 수 있다.

그럼 이때 임의의 t 시점에 대해 미래 Reward의 합을 생각해볼 수 있다.
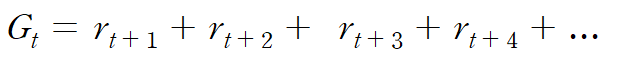
이때 미래 시점을 감쇠하여 생각해보면 R과 γ를 포함한 Return에 대한 수식이 나온다.

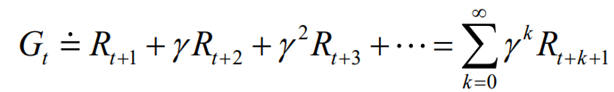
즉 𝛾는 미래 보상의 중요도를 조절한다.
𝛾 ≈ 0이라면 근시안적 agent가 되는 것이고 𝛾 ≈ 1이라면 장기적인 관점의 agent가 되는 것이다.
수학적으로 더 중요한 이유는 return을 bounded하게 만들기 위함이다.
무한 시간 동안 reward를 합하면 발산할 수 있는데 감쇠 인자가 이를 방지한다.
결국 Reward가 특정 시점에 받는 즉시 보상이라면 Return은 미래 보상의 감쇠된 합이다.
강화학습은 reward가 아니라 return을 최대화한다.
에피소드와 상태 가치 (State Value)
이때, Agent가 환경과 상호작용을 시작하고 끝날 때까지의 하나의 경험 과정을 에피소드라고 한다.
이는 Markov 모델에 대한 시퀀스 결과를 의미한다.

각 에피소드별로 Agent는 서로 다른 리워드를 경험하게 된다.

이때, 하나의 상태 (예를 들어 Class1)에서 경험할 수 있는 모든 에피소드의 기댓값을 그 상태의 가치 (Value)라고 표현할 수 있다.

Markov Decision Process (MDP)
(MDP의 구성 요소 5가지 중 : S(상태), P(상태 전이 확률), R(보상), 𝛾(할인율), A(행동))
이제 각 State에서 취할 수 있는 Action이 추가되면 Markov Decision Process (MDP)가 된다.
앞선 MP와 MRP에서는 상태 변화가 확률적으로 결정되었다. (배 위에 둥둥 떠있는 상태)
MDPB에서는 agent가 주체적으로 행동을 결정한다.
아래 도식에서 agent는 이제 Facebook을 할지, Quit할지, Study를 하러 갈지 Sleep을 할지 주체적으로 결정한다.
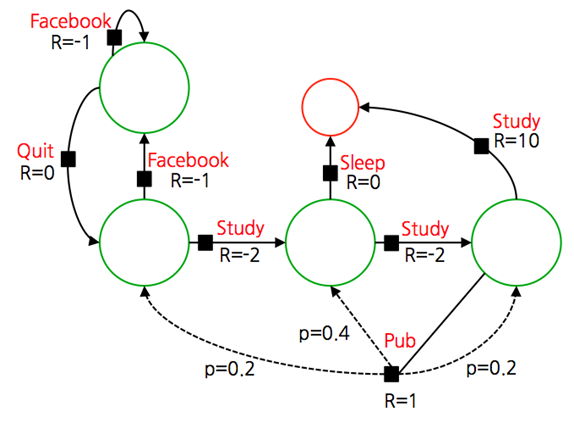
그렇다고 이때 확률적인 특성이 없어지는 것은 아니다.
Agent가 행동을 선택해도, 여전히 다음 상태는 확률적으로 결정된다.
위에서 Agent가 Pub을 가는 결정을 하더라도 class1~class3 중 어디로 갈지는 확률적으로 결정된다.
즉 MDP가 되면서 Action의 집합이 추가되고, 이로 인해 전이확률과 리워드에 action의 요소가 새롭게 추가된다.

여기서 전이확률은 S에서 a를 했을 때 S'에 도달할 확률이다.

Reward 함수 역시 action을 포함해 재정의되는데, 이때 action을 선택했을 때의 Reward의 기댓값으로 정의된다.

정책 (𝝅)과 행동 가치 (Action Value)
Policy는 agent의 행동 전략이다.
이는 상태 S에서 행동 a를 선택할 확률이다.
예를 들어 state s에서 action a_1을 선택할 확률이 60%,
state s에서 action a_2 선택할 확률이 40%라면 다음과 같이 표현할 수 있다.

이처럼 policy를 따르면 agent는 주어진 확률에 따라 action을 결정하게 된다.
학습을 통해 정책 𝝅를 조정해나가는 것이 강화학습의 목적이다.
앞서 상태 가치 (State Value)는 특정 state에서 기대할 수 있는 모든 에피소드의 Return (G)의 평균 (=기댓값)이었다.
마찬가지로 행동 가치 (Action Value)는 특정 action을 선택했을 때 앞으로 받을 총 return의 기댓값이다.
policy 𝝅를 따를 때 s에서 a를 선택했을 때 기대할 수 있는 Return은 다음과 같다.

즉, 정리하며 아래와 같다.
- 상태 s에서 행동 a를 먼저 선택하고
- 이후에는 정책 π를 따랐을 때
- 얻을 수 있는 기대 return
상태 가치 (State Value)와 행동 가치 (Action Value)의 관계

상태 가치 (State value)는 현재 상태에서 정책에 따라 선택된 행동의 행동 가치 (Action value)로 이어진다.
행동 가치 (Action value)는 해당 행동의 결과로 받는 보상 (Reward)과 다음 상태의 상태 가치 (State value)의 기댓값이다.
이처럼 상태가치 Vπ(s)와 행동가치 Qπ(s,a)는 서로를 통해 정의되는 재귀적 관계에 있다.
상태가치는 현재 상태 ss에서 정책 π에 따라 선택될 행동들의 행동가치를 확률적으로 평균낸 값이다.
즉, 정책이 확률적으로 행동을 선택한다면 상태가치는 그 행동가치들의 기댓값이 된다.
반대로 행동가치는 상태 s에서 특정 행동 a를 먼저 선택했을 때,
즉시 받는 보상과 그 다음 상태 s′의 상태가치의 기댓값으로 구성된다.
다시 말해, 상태가치는 행동가치의 정책 평균이고, 행동가치는 보상과 다음 상태가치의 합으로 표현된다.
이 관계는 벨만 기대 방정식(Bellman Expectation Equation)으로 정식화되며,
강화학습에서 가치 기반 방법과 정책 기반 방법을 연결하는 핵심 구조를 이룬다.
'딥러닝 모델 > DQN for Cloud-Edge Caching' 카테고리의 다른 글
| [강화학습 기초 6] Temporal Difference를 통한 step 기반 가치 평가 (MDP를 모를 때) (0) | 2026.03.03 |
|---|---|
| [강화학습 기초 5] Monte Carlo를 통한 에피소드 기반 가치 평가 (MDP를 모를 때) (0) | 2026.03.02 |
| [강화학습 기초 4] Dynamic Programming 기반 Solution (MDP를 알 때) (0) | 2026.03.01 |
| [강화학습 기초 3] 벨만 방정식(Bellman Equation) 유도하기 (0) | 2026.03.01 |
| [강화학습 기초 1] 강화학습의 핵심 개념 (에이전트, 환경, 리워드) (0) | 2026.02.27 |