Monte Carlo Learning이 “에피소드가 끝날 때까지 기다렸다가 리턴 전체를 평균내는 방식”이었다면,
Temporal Difference Learning은 한 스텝만 지나도 즉시 업데이트하는 방식이다.
즉, Full-Return이 아니라 One-Step Bootstrapping에 기반한 방법이다.
MDP의 전이 확률 P와 보상 함수 R을 모르는 상황에서 정책 π의 가치 Vπ(s)를 추정해야 한다는 문제 설정은 동일하다.
차이는 “언제, 무엇을 target으로 업데이트하느냐”에 있다.
Monte Carlo의 한계
Monte Carlo는 하나의 에피소드를 끝까지 진행해 Return을 구하고, 이를 직접 평균내는 방식이다.
그러나 이 리턴은 에피소드가 종료되어야만 계산할 수 있다.

여기서 자연스러운 질문이 나온다.
- 종료 상태가 없는 non-terminating MDP에서는 어떻게 할 것인가?
- 굳이 끝까지 기다리지 않고 지금 당장 업데이트할 수는 없는가?
이 질문에 대한 답이 바로 Temporal Difference Learning이다.
벨만 기대 방정식의 수식 상의 아이디어
벨만 기대 방정식에서의 가치 함수는 다음에서 출발했다.
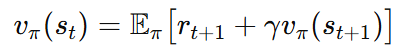
그리고 가치 함수를 Return으로 나타내면 다음과 같다.
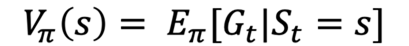
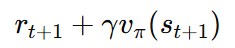
그렇다면 왼쪽 수식 부분을 여러 번 샘플링 해 평균내도 되지 않을까?
이 항을 우리는 TD target이라고 부른다.
따라서 TD Learning의 알고리즘은 다음과 같다.
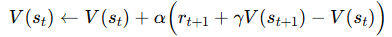
여기서 괄호 안의 항을 TD error라고 한다.
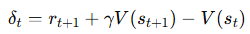
TD target의 아이디어

그런데 문제는 우리가 왼쪽의 값인 다음 상태의 가치를 모른다는 것이다. (미래를 알 수는 없다)
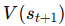
때문에 우리는 왼쪽과 같은 현재 추정치 V를 사용한다. (이것이 바로 bootstrapping이다)
이 V값을 써도 되는 이유가 증명이 되지는 않았지만, 아주 복잡한 Neural Net을 쓸 경우 놀랍게도 이것이 매우 잘 작동한다.
아래와 같은 에피소드를 생각해보자.
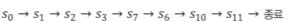
그럼 s0의 value는 s1의 value를 이용해서 update된다.
s1의 value는 s2의 value를 이용해 update된다.
따라서 이 과정에서는 총 8번 업데이트가 일어나며, 에피소드가 종료될 때까지 기다릴 필요가 없게 된다.
즉, 한 step만 밟으면 State value의 update가 이루어진다.

def main():
#TD
env = GridWorld()
agent = Agent()
data = [[0,0,0,0],[0,0,0,0],[0,0,0,0],[0,0,0,0]]
gamma = 1.0
reward = -1
alpha = 0.01
for k in range(50000):
done = False
while not done:
x, y = env.get_state()
action = agent.select_action()
(x_prime, y_prime), reward, done = env.step(action)
x_prime, y_prime = env.get_state()
data[x][y] = data[x][y] + alpha*(reward+gamma*data[x_prime][y_prime]-data[x][y]) // TD Learning
env.reset()
for row in data:
print(row)
if __name__ == '__main__':
main()
Monte Carlo Learning과 Temporal Difference Learning의 궁극적인 차이점
즉 Monte Carlo 방법과 Temporal Difference 방법 모두 Sampling 기반 추정의 방법론이다.
두 방법 모두 강화학습의 기본 알고리즘으로 활용이 된다.
Monte Carlo 방식
Monte Carlo Learning은 하나의 에피소드를 끝까지 수행한 뒤 계산된 sample의 평균으로 업데이트를 하게 된다.
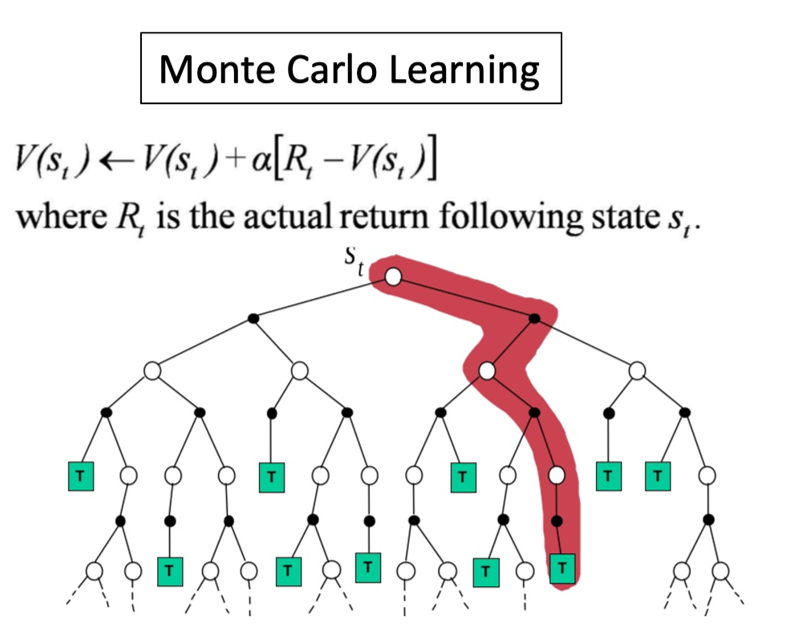
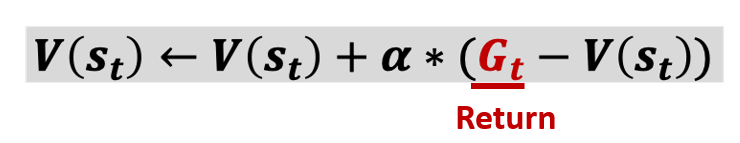

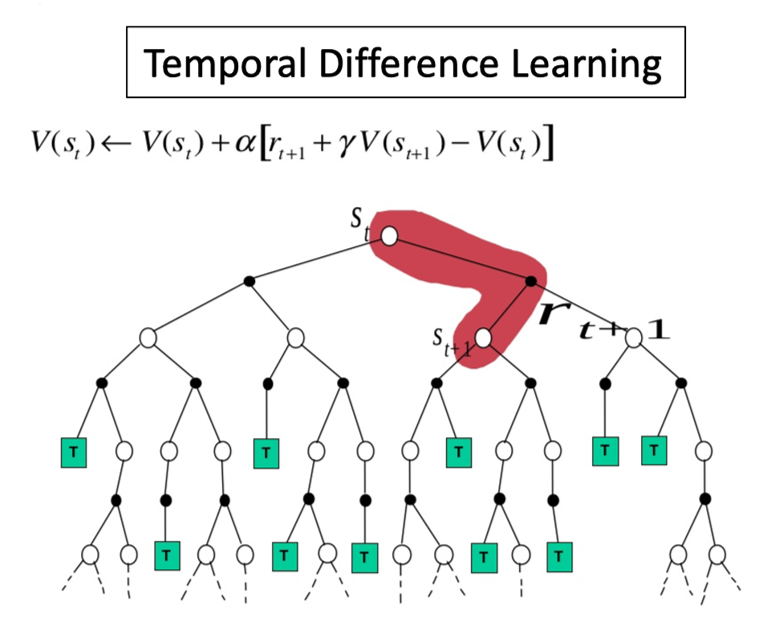
Temporal-Difference 방식
반면 Temporal-Difference Learning은 에피소드 중간마다 다음 step의 return값인 TD Target을 이용해 업데이트가 진행된다.

차이점 1 : 학습 시점
MC는 에피소드가 끝나야 학습이 가능하고, TD는 한 스텝만 끝나도 바로 학습이 가능하다.
따라서 TD가 학습 시점 면에서는 더 유연하게 사용 가능하다. 특히 에피소드가 끝나지 않는 MDP도 있기 때문에 이런 상황에서는 TD를 우월하게 사용할 수 있다.
차이점 2 : Bias
MC와 TD의 근간이 되는 식을 살펴보면 다음과 같다.

MC는 value function의 정의인 return의 기댓값으로부터 시작된 방법론으로, return을 여러 개 모아 평균을 내면 이론적으로 완벽하게 value 값을 얻을 수 있다.
따라서 MC는 unbiased estimate(편향되지 않은 추정치)라고 할 수 있다.
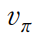
를 TD를 써서 unbiased로 만들려면 TD의 대괄호 안에 있는 것을 평균 내면 된다.
그런데 이 값은 절대 알 수가 없다.

를 구하려고 하는데 똑같은 값이 필요하다는 것은 말이 되지 않는다.
따라서 우리는 테이블에 존재하는 Vπ를 쓴는데, 이 값은 unbiased estimate가 아니다.
이걸 무한히 모은다고 해서 vπ에 도달한다는 이론 적 보장은 없지만 실제로는 굉장히 잘 작동한다.
그러나 결국 bias 기준에서는 Monte Carlo 방식이 더 우월하다.
차이점 3 : Variance
Variance는 실제적으로 까다로운 성질을 가지고 있다.
만약 정답이 500인 문제인데, 1번 머신은 0~1000 사이 숫자가 랜덤하게 나오고, 2번 머신에서는 505~510 사이 숫자가 랜덤하게 나온다고 하자.
이 상황에서 머신1과 머신2에서 각각 10개의 숫자를 뽑아 평균 낸다면?
이 경우 bias는 1번 머신이 좋지만 Variance까지 고려한 것은 2번 머신이 좋을 것이다.
MC에서 사용하는 Return을 얻기 위해 수많은 확률적 과정을 거치므로 Variance가 크다.
반면 TD는 한 스텝만 가면 되므로 확률적 과정이 2번밖에 없다. (Policy와 환경의 동전 던지기)
따라서 Temporal Difference가 Variance가 작기 때문에 Variance를 기준으로 보면 TD가 우월하다.
TD와 MC는 스펙트럼이다
TD target을 일반화하면 N-step TD를 만들 수 있다.

왼쪽과 같은 방식은 1 step TD라고 부른다.
그럼 우린 자연스럽게 N스텝 TD를 생각할 수 있다.

이 N step이 무한대로 수렴하면 그것은 곧 Monte Carlo 방식과 동일하다.
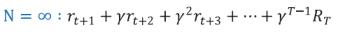
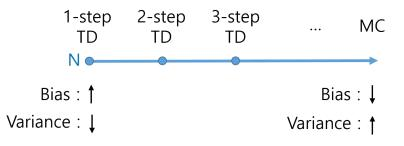
즉, TD와 MC는 완전히 별개의 개념이 아니라 스펙트럼의 개념이다.
한 쪽 끝에는 TD가 한 쪽 끝에는 MC가 있는 형태인 것이다.
TD에 가까워질수록 Bias는 커지지만 Variance는 작아지고,
MC에 가까워질수록 Bias가 작아지고 Variance는 커진다.
아마 이 사이에 Sweet Spot이 있을 수 있다.
이는 학습하기 전에는 알 수 없고, 시도를 통해서 찾아야 하는 hyperparameter가 된다.
정리
결국 Temporal Difference Learning은 “에피소드를 끝까지 기다리지 않는다”는 점에서 Monte Carlo와 본질적으로 다르다.
Full Return이 아니라 One-Step Bootstrapping을 사용한다.
모델을 몰라도, 에피소드가 끝나지 않아도, 매 스텝마다 학습이 가능하다.
이 특성 때문에 TD는 현대 강화학습 알고리즘(DQN, Actor-Critic 등)의 기반이 된다.
Monte Carlo가 정의에 충실한 방법이라면, TD는 벨만 구조를 직접 활용한 실용적 방법이라고 정리할 수 있다
'딥러닝 모델 > DQN for Cloud-Edge Caching' 카테고리의 다른 글
| [강화학습 기초 8] 딥마인드 DQN의 구조와 학습 테크닉 (Replay Buffer, Target Network) (0) | 2026.03.03 |
|---|---|
| [강화학습 기초 7] Deep Reinforcement Learning의 핵심 (Value Network와 Deep-Q Learning) (0) | 2026.03.03 |
| [강화학습 기초 5] Monte Carlo를 통한 에피소드 기반 가치 평가 (MDP를 모를 때) (0) | 2026.03.02 |
| [강화학습 기초 4] Dynamic Programming 기반 Solution (MDP를 알 때) (0) | 2026.03.01 |
| [강화학습 기초 3] 벨만 방정식(Bellman Equation) 유도하기 (0) | 2026.03.01 |