Monte Carlo Learning의 개념
MDP의 전이 확률 와 보상 함수 을 모르는 상황에서는 더 이상 벨만 방정식을 직접 풀 수 없다.
즉, 기대값을 수식으로 계산할 수 없기 때문에, 실제 경험으로부터 값을 근사해야 한다.
이때 등장하는 접근이 샘플 기반 방법론이며, 그 대표적인 방식이 Monte Carlo Learning이다.
Monte Carlo 방법은 매우 직관적이다.
동전을 여러 번 던져 앞면이 나올 확률을 추정하듯이,
에이전트가 실제로 환경과 상호작용하며 얻은 샘플 리턴을 평균내어 상태 가치를 추정하는 방식이다.
가치 함수의 정의는 다음과 같다.
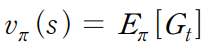
여기서 G는 Return값으로, 시점 t 이후 종료 시점까지의 누적 보상이다.
즉, Monte Carlo는 "리턴의 기댓값"이라는 정의를 에피소드를 무수히 반복하면서 직접 구현하는 방법이다.
에피소드 기반 업데이트 구조
마찬가지로 아래의 간단한 Grid World 문제를 생각해보자.

여기에서 달라진 점은 우리는 P와 R을 전혀 모르는 상황이다.
이때 보상이 정해져있지 않다는 것은 아니고, 단지 우리의 agent가 모르는 상황이다.
agent는 이제 이 Grid World를 이동하면서 하나의 에피소드를 경험하고 샘플을 얻게 된다.
작은 문제이기 때문에 테이블 기반 방법론을 쓴다.
임의 값으로 값을 초기화하고, agent를 랜덤으로 이동시킨다.
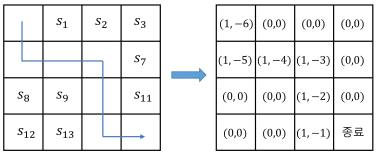
이 과정에서 여기서 첫 번째 값은 방문 횟수이다.
따라서 agent가 방문한 모든 칸의 앞의 값은 1씩 증가했다.
두 번째 값은 리턴이다.
이 문제에서 매 스텝 보상이 -1이라면, 어떤 상태에서 시작했을 때 종료까지 n스텝 걸렸으면 그 상태의 리턴은 대략 −n이 된다.
즉, 가치가 더 “덜 음수”일수록 집이 가깝거나(기대 종료 시간이 짧거나) 정책상 유리한 위치라고 볼 수 있다.

이 Monte Carlo Learning의 특징은 종료가 되기 전까지는 리턴을 알 수 없다는 것이다.
그냥 해보면서 언젠가 종료가 되면, 그때 딱 멈추고 지나온 경로에 대한 값들을 업데이트하는 것이다.
이걸 엄청나게 많이 해서 평균을 내는 것이 목적이다.
리턴 G의 계산법은 다음과 같았다.
γ를 1이라고 놓아 감쇠가 없다고 가정하였다.
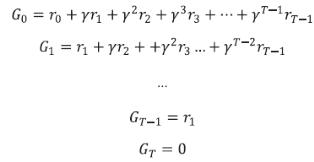
이 에피소드를 아주 여러 번 하면 이 테이블이 특정 값으로 가득 찰 것이고,
그때 각 상태마다 오른쪽 값을 왼쪽 값으로 나눠주면 된다. 이것이 평균이다.

점진적 업데이트의 도입
그런데 일단 수십만 번 돌려보고, 마지막에 평균을 구해도 되지만, 보통은 다음 점진식으로 쓰는 경우가 많다.
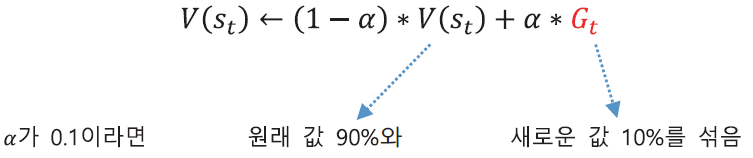
혹은,

이 식은 다음 장의 TD Learning 업데이트 형태와 직접적으로 연결된다.
def main():
env = GridWorld()
agent = Agent()
data = [[0,0,0,0],[0,0,0,0],[0,0,0,0],[0,0,0,0]]
gamma = 1.0
reward = -1
alpha = 0.001
for k in range(100000):
done = False
history = []
while not done:
action = agent.select_action()
(x,y), reward, done = env.step(action)
history.append((x,y,reward))
env.reset()
cum_reward = 0
for transition in history[::-1]:
x, y, reward = transition
data[x][y] = data[x][y] + alpha*(cum_reward-data[x][y]) // 점진적 업데이트
cum_reward = reward + gamma*cum_reward
for row in data:
print(row)
if __name__ == '__main__':
main()
이를 기반으로 실제 5만 개의 Episode를 활용해 구한 값은 다음과 같다.

이를 10만 번, 100만 번 점점 더 진행할수록 벨만 기대방정식으로 구한 이론값과 가까워지게 될 것이다.
이론 값은 아래와 같았다.

'딥러닝 모델 > DQN for Cloud-Edge Caching' 카테고리의 다른 글
| [강화학습 기초 7] Deep Reinforcement Learning의 핵심 (Value Network와 Deep-Q Learning) (0) | 2026.03.03 |
|---|---|
| [강화학습 기초 6] Temporal Difference를 통한 step 기반 가치 평가 (MDP를 모를 때) (0) | 2026.03.03 |
| [강화학습 기초 4] Dynamic Programming 기반 Solution (MDP를 알 때) (0) | 2026.03.01 |
| [강화학습 기초 3] 벨만 방정식(Bellman Equation) 유도하기 (0) | 2026.03.01 |
| [강화학습 기초 2] Markov Decision Process (0) | 2026.02.27 |