Edge AI Chips
Edge 디바이스에서 직접 머신러닝 추론을 수행하도록 설계된 전용 프로세서이다.
저전력, 실시간 성능, 열 제약 조건 등에 맞게 최적화된 칩이다.
대표적으로 NVIDIA Jetson, Google Coral TPU, Intel Movidius, Apple Neural Engine 등이 있다.




NVIDIA Jetson
- 설명: GPU 기반의 엣지 AI 플랫폼으로, 실시간 비전 처리와 로보틱스에 특화됨.
- 특징: CUDA·TensorRT 지원으로 고성능 딥러닝 추론 가능.
- 활용 예: 산업용 로봇, 자율주행 드론, 스마트 카메라.
Google Coral TPU
- 설명: Google이 개발한 Tensor Processing Unit 기반의 초저전력 AI 칩.
- 특징: TensorFlow Lite 모델에 최적화되어 엣지 디바이스에서 고속 추론 가능.
- 활용 예: 스마트 센서, 소형 IoT 장치, 영상 인식 카메라.
Intel Movidius
- 설명: Vision Processing Unit(VPU) 으로, 영상 인식과 딥러닝 추론을 저전력으로 수행.
- 특징: 저전력 환경에서 CNN 기반 이미지 처리에 뛰어남.
- 활용 예: 드론, 감시 카메라, 스마트 홈 디바이스.
Apple Neural Engine (ANE)
- 설명: iPhone·iPad·Mac 등에 내장된 전용 신경망 연산 프로세서.
- 특징: 얼굴 인식, 음성 인식 등 온디바이스 AI 연산을 GPU/CPU와 분리해 처리.
- 활용 예: Face ID, Siri, 사진 분류, 실시간 번역 등.
5G Connectivity

5G는 5세대 이동통신 기술로, 이전 세대(4G LTE)보다 훨씬 빠른 전송 속도와 낮은 지연 시간을 제공한다.
초저지연(1~10ms)과 고대역폭, 네트워크 밀집화(densification)를 통해 엣지 환경에 최적화된 통신을 지원한다.
수많은 IoT 디바이스와 엣지 서버 간의 동시 연결을 가능하게 하며, 데이터 처리 효율을 극대화한다.
이때 5G는 MEC, 실시간 로보틱스, 자율주행차 등에서 핵심적인 연결 인프라 역할을 수행한다.
이를 통해 대규모 분산형 AI 학습이나 원격 제어 시스템에서도 안정적인 실시간 응답을 제공할 수 있다.
- eMBB (enhanced Mobile Broadband):
초고속 데이터 전송을 제공하여 3D/4K 영상, 클라우드 게임, VR/AR 등 대용량 멀티미디어 서비스를 지원한다. - mMTC (massive Machine Type Communication):
수많은 IoT 기기들이 동시에 연결되어 스마트홈, 스마트시티, 산업 자동화 등에서 대규모 센서 네트워크를 형성한다. - URLLC (Ultra-Reliable Low Latency Communication):
극도로 낮은 지연과 높은 신뢰성을 요구하는 자율주행, 원격 수술, 미션 크리티컬 통신을 가능하게 한다.
TinyML
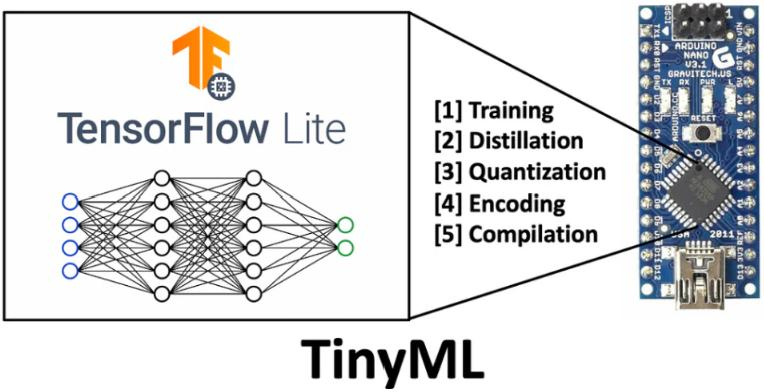
TinyML이란 초저전력 마이크로컨트롤러(일반적으로 1mW 미만) 에서 실행될 수 있도록 압축된 머신러닝 모델을 의미한다.
운영체제(OS)나 네트워크 연결 없이도 극단적 엣지 환경(extreme edge) 에서 지능형 처리를 가능하게 한다.
대표적으로 TensorFlow Lite for Microcontrollers, Edge Impulse 등이 있다.
TinyML은 다음과 같은 특성을 가진다.
- 초저전력
- 1mW 이하의 전력으로 동작하며, 배터리로 수년간 구동 가능하다.
- 항상 켜져 있어야 하는 센서 기반 시스템에 적합하다.
- 온디바이스 처리(On-Device Inference)
- 데이터를 클라우드로 전송하지 않고 디바이스 내부에서 즉시 처리한다.
- 개인정보 유출 위험을 줄이고, 네트워크 지연(latency)을 최소화한다.
- 경량화된 모델 구조
- TensorFlow Lite for Microcontrollers, Edge Impulse, PyTorch Mobile 등으로
모델을 양자화(Quantization), 가지치기(Pruning), 지식 증류(Distillation) 하여
수십 KB~수MB 메모리에서도 동작하도록 최적화한다.
- TensorFlow Lite for Microcontrollers, Edge Impulse, PyTorch Mobile 등으로
Network slicing

네트워크 슬라이싱은 하나의 물리적 네트워크 인프라(예: 5G 네트워크)를 여러 개의 가상 네트워크로 논리적으로 분리(Slice) 하여
각각의 애플리케이션, 서비스, 또는 사용자 그룹(테넌트)에 맞춤형 네트워크 환경을 제공하는 기술이다.
즉, 하나의 네트워크를 여러 개처럼 쪼개서 각 슬라이스마다 필요한 속도, 지연 시간, 안정성, 보안 수준 등을 다르게 설정하는 것을 말한다.
5G의 등장 당시 핵심 Concept으로 꼽혔지만 개별적인 Slicing 설정의 어려움으로 인해 제대로 구현되지 않다가,
최근 AI의 비약적인 발달로 상용화 가능성이 보이고 있다.
다음과 같은 특징을 가진다.
- 맞춤형 네트워크 구성 (Customization)
- 예를 들어, 자율주행차는 초저지연(1~10ms)이 중요하지만,
동영상 스트리밍 서비스는 높은 대역폭이 더 중요하다. - 슬라이싱을 통해 각각에 맞는 네트워크 자원을 따로 할당한다.
- 예를 들어, 자율주행차는 초저지연(1~10ms)이 중요하지만,
- 성능 격리 (Performance Isolation)
- 하나의 서비스가 트래픽이 폭주하더라도
다른 슬라이스에 영향을 주지 않도록 리소스가 완전히 분리된다. - 예: 공장 자동화 시스템과 사내 와이파이 서비스가 같은 네트워크를 써도 서로 간섭하지 않음.
- 하나의 서비스가 트래픽이 폭주하더라도
- QoS (Quality of Service) 보장
- 각 슬라이스는 필요한 대역폭, 안정성, 지연 시간을 계약 수준(SLA)에 따라 보장받는다.
- 예: 응급 의료 데이터 전송 슬라이스는 항상 최우선 순위를 가짐.
- End-to-End 구성 가능
- 단순히 무선 구간(5G 기지국)뿐만 아니라
코어 네트워크, 전송망, 클라우드 자원까지 슬라이스 단위로 관리 가능하다.
- 단순히 무선 구간(5G 기지국)뿐만 아니라
활용 사례 - 스마트시티 :
- 하나의 슬라이스 → 응급 차량 및 공공안전 서비스용 (초저지연, 높은 신뢰성)
- 다른 슬라이스 → CCTV 데이터 업로드 및 교통 모니터링용 (중간 수준 QoS)
- 또 다른 슬라이스 → 공공 와이파이 서비스용 (낮은 우선순위, 대역폭 중심)
'Cloud & Edge 인프라 > Cloud & Edge Computing' 카테고리의 다른 글
| Edge-Cloud System의 계층적 구조 (0) | 2025.10.10 |
|---|---|
| Edge Computing을 위한 오픈소스와 상업 플랫폼들 (0) | 2025.10.10 |
| Edge의 Data Privacy를 보호하는 Federated Learning (0) | 2025.10.10 |
| Edge Cloud Computing의 Usecase와 Challenge (0) | 2025.10.10 |
| Edge Application의 주요 지표인 Latency와 Bandwidth (0) | 2025.10.10 |