Edge-to-cloud의 의미

Edge-to-Cloud Architecture는 계산 작업을 Edge, Fog, Cloud에 지능적으로 분산하는 분산 아키텍처 패러다임이다.
이것이 등장한 이뉴는 전통적인 클라우드 중심 모델의 한계 때문이다.
Traditional한 Cloud-centric 모델의 경우 높은 지연시간의 문제가 반드시 발생했다.
IoT 디바이스 → 원격 데이터센터 → 디바이스로 왕복하는 과정에서 지연이 100ms 이상 발생할 수 있는데,
이것은 자율주행 차량의 충돌 회피와 같은 상황에서 매우 치명적인 문제이다.
또한 다양한 IoT 기기들이 생성하는 고해상도 영상, LiDAR, PLC 등의 센서 데이터는 Uplink를 포화시킬 수 있다.
raw data의 지속적인 전송은 매우 비효율적이고 높은 cost를 초래한다.
마지막으로 순수한 클라우드 기반의 접근은 단일 장애 지점을 유발한다.
이는 곧 네트워크 장애, 클라우드 서비스 중단 시 운영이 완전히 마비될 수 있다는 한계를 가진다.
이런 상황에서 Edge-to-Cloud 구조는 다음의 강점을 가지게 된다.
| 기능 (Feature) | 엣지 (Edge) | 클라우드 (Cloud) |
| 지연 시간 | μs~ms (실시간) | 100ms+ (비결정적) |
| 연산 비용 | 제한적, 에너지 효율적 | 대규모, 탄력적 |
| 보안성 | 데이터가 로컬에 머무름 | 암호화·확장 가능 |
| AI 역할 | 실시간 추론 | 모델 학습·조정 |
| 복원력 | 오프라인/간헐 연결에서도 동작 | 중앙 제어·조정 |
결국 Edge-to-Cloud는 단순히 클라우드를 대체하는 개념이 아니라,
현대의 실시간·보안·효율적 처리 요구를 만족시키기 위한 진화된 형태의 분산 컴퓨팅 모델인 셈이다.
이때 엣지와 클라우드를 연결하는 핵심 기술로는 다음이 있다.
- 엣지 AI (AI at the Edge):
TensorFlow Lite, NVIDIA Jetson, OpenVINO 등으로 ms 단위 의사결정 수행 - 프로토콜 스택:
MQTT, CoAP, gRPC 등 경량 메시징 프로토콜 - 하이브리드 오케스트레이션:
KubeEdge, Azure IoT Edge, AWS Greengrass 등으로 분산 워크로드 및 모델 동기화 관리 - 연합 학습 (Federated Learning):
엣지에서 로컬 학습 후 모델 업데이트만 클라우드로 전송,
개인정보 보호 강화 및 대역폭 절감
Edge-Cloud System의 4계층

Devices (디바이스)
가장 아랫 단에 위치하는 디바이스의 IoT 프로토콜은 다음이 있다.
| 기능 | Wi-Fi | ZigBee | Bluetooth(BLE) | LoRa/LoRaWAN | NB-IoT |
| 주파수 대역 (Frequency Band) | 2.4 GHz / 5 GHz | 2.4 GHz (글로벌), 868/915 MHz | 2.4 GHz | Sub-GHz (예: 868/915 MHz) |
LTE 면허대역 (예: Band 8, 20) |
| 통신 거리 (Range) | 실내 약 50 ~ 100 m | 홉당 10 ~ 100 m (메시 가능) | 약 10 ~ 100 m | 농촌 최대 15 ~ 20 km |
약 1 ~ 10 km |
| 토폴로지 (Topology) | 스타 / 인프라 구조 | 메시, 스타, 트리 | 스타 / P2P | 게이트웨이를 통한 스타형 |
기지국 기반 스타형 |
| 데이터 전송률 (Data Rate) |
최대 1 Gbps (Wi-Fi 6) | 최대 250 kbps | 최대 2 Mbps (BLE 5.0) |
0.3 ~ 50 kbps | 약 20 ~ 250 kbps |
| 전력 소모 (Power Consumption) |
높음 | 매우 낮음 | 낮음 | 초저전력 | 낮음 (긴 배터리 수명용) |
| 지연시간 (Latency) | < 10 ms | 약 30 ~ 100 ms | < 3 ms | 높음 (약 1 ~ 10 초) | 중간 ~ 높음 (1 ~ 10 초) |
| 대역폭 효율 (Bandwidth Efficiency) |
높음 | 중간 | 중간 | 낮음 | 낮음 |
| 허브당 디바이스 수 (Device Count per Hub) |
보통 30 ~ 50대 | 메시 구조로 60,000대 이상 |
최대 8대 (클래식), BLE 20대 이상 | 게이트웨이당 수백만대 가능 |
셀당 10만대 이상 (Massive IoT) |
| 보안 (Security) | WPA2/WPA3 | AES-128 | AES-128 | AES-128 + 네트워크/세션키 | LTE 등급 보안 + SIM 인증 |
| 활용 사례 (Use Cases) | 스마트 가전, IP 카메라 |
조명, 센서, 미터링 | 웨어러블, 헬스, 비콘 | 농업, 원격 센싱, 트래킹 |
스마트 미터링, 자산 추적, 주차 |
| 인터넷 연결성 (Internet Connectivity) |
네이티브 IP 기반 | ZigBee→IP 게이트웨이 필요 |
게이트웨이 또는 스마트폰 필요 | LoRaWAN 서버 필요 |
셀룰러 기반 네이티브 IP |
구성요소 (Components)
- 센서: 온도, 압력, 진동, GPS, 영상 등 텔레메트리 데이터 수집
- 액추에이터: 엣지 추론 결과에 따른 물리적 제어 (모터, 밸브 등)
- 임베디드 컴퓨트:
- NVIDIA Jetson – 엣지 AI 추론 및 컴퓨터 비전
- Raspberry Pi / BeagleBone – 경량 엣지 제어 또는 게이트웨이
- MCU 및 FPGA – 산업용 저전력 결정론적 제어
핵심 기능 세부
- 로컬 네트워크 조정: 디바이스 간 LAN/WAN 트래픽 관리
- 데이터 처리 및 감축: 노이즈 제거, 압축, AI/ML 모델 1차 적용
- 캐싱 및 버퍼링: 지연 최소화 및 연결 불안정 대응
- 제어 루프 실행: 센서 피드백 기반 실시간 액추에이터 조정
- 가상화: 경량 오케스트레이터 (K3s, KubeEdge, MicroK8s) 를 이용한 컨테이너 워크로드 운영
Edge Layer (엣지 계층)

Edge Layer는 실제 학습이 이루어지는 핵심 계층이다.
다음과 같은 구성 요소로 이루어진다.
- Edge Node / AIoT Devices: 차량, 센서, 카메라, 스마트폰 등 로컬 디바이스
- Edge Controller: 엣지 영역 내 여러 디바이스를 관리하고 로컬 모델을 집계
엣지 계층의 가상화 기법은 다음이 있다.
| 항목 | K3s | KubeEdge | MicroK8s |
| 크기 | 약 100 MB 전체 | 약 150 MB (Cloud + EdgeCore) | 약 200–300 MB Snap 이미지 |
| RAM 사용량 | 약 500–600 MB | EdgeCore 150 MB, CloudCore 250 MB | 약 1 GB+ (대시보드 포함) |
| 엣지 네이티브 지원 | 부분적 | 완전 지원 | 미지원 |
| 오프라인 동작 | 제한적 | 완전 엣지 자율 운영 | 미지원 |
| IoT 지원 | X | 디바이스/트윈 지원, MQTT 매퍼 | X |
| CPU 아키텍처 | ARMv7, ARM64, x86, x86_64 |
ARM, ARM64, x86, x86_64 | ARM, ARM64, x86 (Ubuntu 기반) |
| 메시징 | X | MQTT 브로커 + EventBus | X |
| 보안 | TLS, RBAC, Secrets | 상호 TLS, TokenAuth, 보안 터널 | TLS, RBAC, AppArmor |
| 적합 환경 | 경량 K8s 클러스터 | 분산 IoT/엣지 배포 | DevOps 테스트, Snap 기반 K8s 데모 |
엣지 계층의 로컬 운영체제를 비교하면 다음과 같다.
| 기능 | Yocto | Buildroot | Debian / Ubuntu |
| 커스터마이징 수준 | 매우 높음 | 높음 | 낮음 |
| 시스템 크기(Footprint) | 최소 (선택적 구성) | 작음 | 큼 |
| 패키지 매니저 | 없음 (정적 이미지) | 없음 | APT |
| 학습 난이도 | 높음 | 중간 | 쉬움 |
| 주요 사용처 | 상용 임베디드 제품, 복잡한 시스템 | 소형 프로토타입, 고정 기능 디바이스 | 범용 컴퓨터, 서버형 엣지 |
사용할 수 있는 소프트웨어는 다음과 같다.
- 운영체제: Yocto Linux, Ubuntu Core 등
- 엣지 런타임: KubeEdge, Azure IoT Edge 등
- 경량 AI 모델: TensorFlow Lite, OpenVINO, ONNX Runtime
| 항목 | TensorFlow Lite (Google) | OpenVINO Toolkit (Intel) | ONNX Runtime (Microsoft) |
| 초점 | 경량 AI 모델 디자인 및 서빙 | Intel 하드웨어용 추론 최적화 | 프레임워크 간 모델 호환성 및 배포 |
| 모델 형식 | .tflite (TensorFlow 변환) | IR (.xml/.bin) | .onnx |
| 주요 용도 | 모바일/IoT 엣지 추론 (ARM 기반) | 컴퓨터 비전, Intel 가속 AI | 범용 플랫폼 추론 및 HW 가속 |
| 모델 호환성 | TensorFlow 전용 | TF, ONNX, Caffe, MXNet 등 | ONNX 기반 (PyTorch, TF, Scikit-learn) |
| 최적화 하드웨어 | ARM CPU, NPU, Edge TPU | Intel CPU/GPU/VPU/FPGA | CPU/GPU/NPU (Windows/Linux/Android) |
| 하드웨어 가속 | CPU, GPU, Coral TPU | Intel iGPU, VPU, OpenCL, oneDNN | CUDA, TensorRT, DirectML 등 |
| 양자화 지원 | 8-bit, float16 | INT8, FP16, BF16 (백엔드 의존) | 백엔드 별 INT8 및 FP16 지원 |
| 배포 플랫폼 | Android, iOS, Linux, MCU (TFLM) | Windows, Linux, Yocto, OpenCL 임베디드 |
Windows, Linux, macOS, Android 등 |
| 툴체인 | TensorFlow + TFLite Converter | Model Optimizer + Inference Engine | ONNX Exporters + Runtime |
| 사용 편의성 | TensorFlow 사용자에게 매우 높음 | Intel HW에 최적, 타 HW 설정 복잡 | 매우 유연 하나 ONNX 변환 필요 |
| 커뮤니티 | 모바일 AI 생태계 활발 | Intel 개발자 네트워크 | MS/NVIDIA/HuggingFace 연합 생태계 |
Network Layer (네트워크 계층)

Network Layer는 엣지–클라우드 간 모델 동기화에 필요한 통신 인프라를 담당한다.
다음 두 가지 네트워크로 구분된다.
- 유선 네트워크 (Wired Network): 전화선, 케이블, 광섬유 등 고정 연결
- 무선 네트워크 (Wireless Network): 4G, 5G, ZigBee, RFID, Wi-Fi, Bluetooth 등
이 계층은 모델 업로드/다운로드가 원활하게 이루어지도록 지원한다.
이 과정에서 MQTT, CoAP, OPC UA, HTTP, QUIC과 같은 다양한 프로토콜이 사용될 수 있다.
주요 프로토콜은 다음과 같다.
- MQTT:
경량 Pub-Sub 프로토콜로 저대역폭, 고지연, 불안정 네트워크에 적합. 산업 및 소비자 IoT에 광범위 사용. - OPC UA:
산업용 M2M 프로토콜로 암호화 및 계층적 데이터 모델 지원. PLC 및 제조 라인 연동에 적합. - 5G / LTE:
초저지연 및 고속 통신, MEC (모바일 엣지 컴퓨팅) 시나리오에 적합. - REST / gRPC:
클라우드 내 마이크로서비스 간 통신에 사용. 특히 gRPC는 AI/ML 서비스에 고성능.
Network Layer는 지연(latency)과 대역폭이 학습 효율에 매우 영향을 미친다.
Cloud Layer (클라우드 계층)

주요 기능
- 전역 엣지 도메인을 감시·조정하는 중앙 오케스트레이터 역할
- 대규모 배치 처리, 모델 학습, 장기 데이터 보존, 정책 기반 관리
- 수천 개의 엣지 노드를 조정하며, 탄력적 컴퓨팅과 중앙화된 AI 학습 기반을 제공
주요 구성요소
- 데이터 웨어하우징: AWS S3, Azure Blob, GCP BigQuery
- 빅데이터 분석 파이프라인: Hadoop, Spark, Athena, Databricks
- ML/AI 학습: GPU 클러스터 또는 SageMaker, Vertex AI 등 관리형 서비스
- OTA 업데이트: 모델 및 소프트웨어를 엣지로 배포
- 오케스트레이션 툴: Kubernetes, KubeEdge, OpenYurt, IoT Greengrass
- 대시보드 & 분석: 실시간 시스템 상태, 비즈니스 지표 시각화
- CI/CD 파이프라인: 엣지 애플리케이션 자동 배포
- 디지털 트윈: 가상화된 시스템 모델링
- API 게이트웨이: 엣지 데이터를 외부 시스템과 연동
Application Layer (응용 계층)

스마트 교통 애플리케이션(Smart Transportation Apps) 이 위치한 최상위 계층으로,
Application Layer 단에서 클라우드에서 완성된 Global Model 을 활용해 실제 서비스를 제공할 수 있다.
대표적인 예시로 교통 혼잡 예측, 자율주행 경로 최적화, 사고 감지 및 응급 대응 시스템 등이 있다.
Edge Cloud System 시나리오 - Federated learning
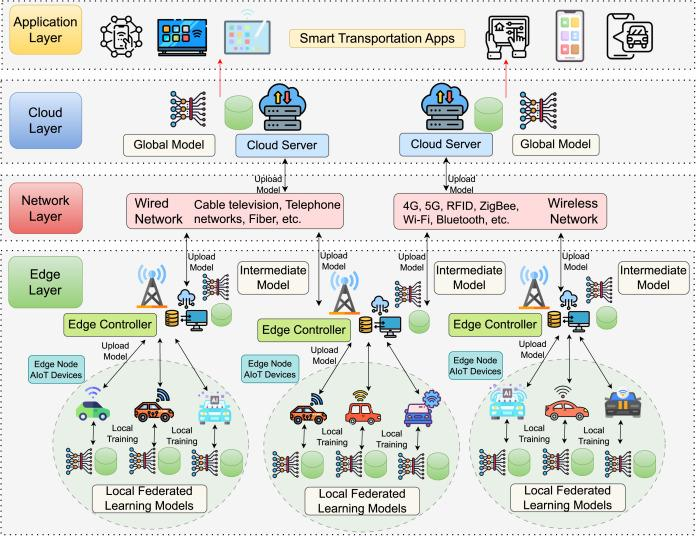
Edge Cloud System의 동작은 어떻게 될까?
이를 보기 위해 스마트 교통 환경에서의 연합학습 상황을 기반으로 Edge-Cloud 협력 학습 구조의 동작을 확인해보자.
위 시나리오에서 Edge Cloud System은 총 4개의 Architecture로 나눌 수 있다.
각 엣지 노드는 Local Training 을 수행하여 Local Federated Learning Model 을 학습하고, 그 결과를 Edge Controller 로 업로드하는데, Tensorflow Lite가 defacto Standard이다.
NVIDIA Jetson을 Edge Layer에서 사용한다면 굉장히 smart하고 powerful하게 동작할 수 있겠지만,
비용적인 Limitation이 존재한다.
Edge Controller는 여러 로컬 모델을 집계하여 Intermediate Model 을 생성하고, 이를 클라우드에 업로드하게 된다.
그 다음 Intermediate Model은 Network Layer를 거쳐서 Cloud 서버로 전송된다.
Cloud 서버는 쿠버네티스 컨테이너 형태로 동작하며, Intermediate 모델을 통합해 Global 모델을 생성하게 된다.
이 Global 모델은 Application Layer로 올라가서 다양한 분석을 수행할 수 있게 된다.
또한, Global 모델은 다시 Edge Node로 재배포되어 다음 라운드의 학습을 시작하게 된다.
'Cloud & Edge 인프라 > Cloud & Edge Computing' 카테고리의 다른 글
| Edge Device에서 사용할 수 있는 OS 총정리 (0) | 2025.11.22 |
|---|---|
| Edge Device의 분류와 종류 (프로토콜, 메모리, 배터리) (0) | 2025.11.22 |
| Edge Computing을 위한 오픈소스와 상업 플랫폼들 (0) | 2025.10.10 |
| Edge System의 4가지 Foundation Technology (0) | 2025.10.10 |
| Edge의 Data Privacy를 보호하는 Federated Learning (0) | 2025.10.10 |