Multi Agent 구조의 취약점
멀티 에이전트 구조는 복잡한 문제를 병렬로 처리할 수 있다는 점에서 분명한 이점을 가진다.
그러나 실제로 장시간 실행되며 높은 신뢰성이 요구되는 에이전트 시스템에서는, 오히려 가장 취약한 선택이 되는 경우가 많다.
이 취약점의 원인은 성능이나 병렬성 자체가 아니라, Context와 의사결정의 일관성 붕괴에 있다.
에이전트의 신뢰성 이슈
장시간 실행되는 에이전트의 가장 중요한 요구사항은 신뢰성이다.
단 한 번의 정답보다, 긴 시간 동안 일관된 판단을 유지하는 것이 더 중요하다. 이 신뢰성의 핵심에는 Context Engineering이 있다.
에이전트는 매 순간 Context를 기반으로 행동을 선택한다.
Context에는 단순한 입력뿐 아니라, 지금까지 내려진 결정, 사용한 도구, 실패와 성공의 흔적이 모두 포함된다. 즉, 컨텍스트는 에이전트의 상태이자 기억이다.
멀티 에이전트 구조는 이 컨텍스트를 분산시킨다.
문제는 바로 이 지점에서 발생한다.
작업 분해는 곧 의미 분해다
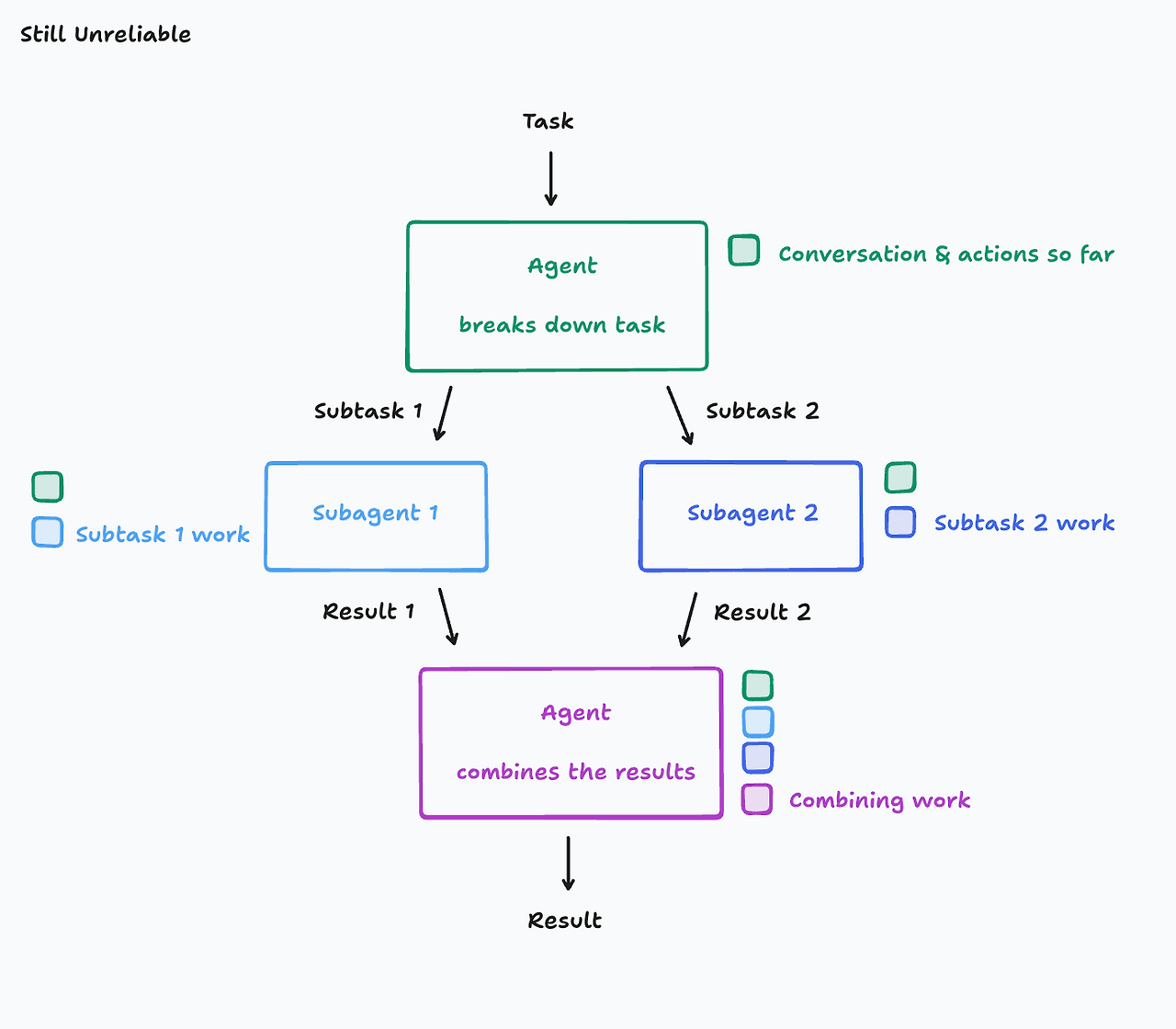
멀티 에이전트 구조는 보통 다음과 같은 패턴을 따른다.
- 메인 에이전트가 작업을 여러 하위 작업으로 분해한다
- 서브 에이전트들이 각 하위 작업을 수행한다
- 결과를 다시 결합한다
문제는, 작업을 분해하는 순간 의미 역시 분해된다는 점이다.

예를 들어 “Flappy Bird 클론을 만들어라”라는 작업은 단순해 보이지만, 여기에는 수많은 암묵적 가정이 들어 있다.
게임의 스타일, 물리감, 시각적 일관성, 사용자 경험 등은 명시적으로 적지 않아도 공유되어야 하는 맥락이다.
하지만 서브 에이전트는 이 암묵적 맥락을 완전히 공유하지 못한다.
각 에이전트는 자신이 받은 하위 작업과 제한된 컨텍스트를 기준으로 합리적인 결정을 내리지만, 그 결정들은 서로 다른 가정 위에서 내려진다.
따라서 멀티 에이전트 구조에서 의사결정은 지나치게 분산되고, 그 결과 시스템 전체의 신뢰성은 급격히 낮아진다.
Claude Code의 Sub Agent 아키텍처
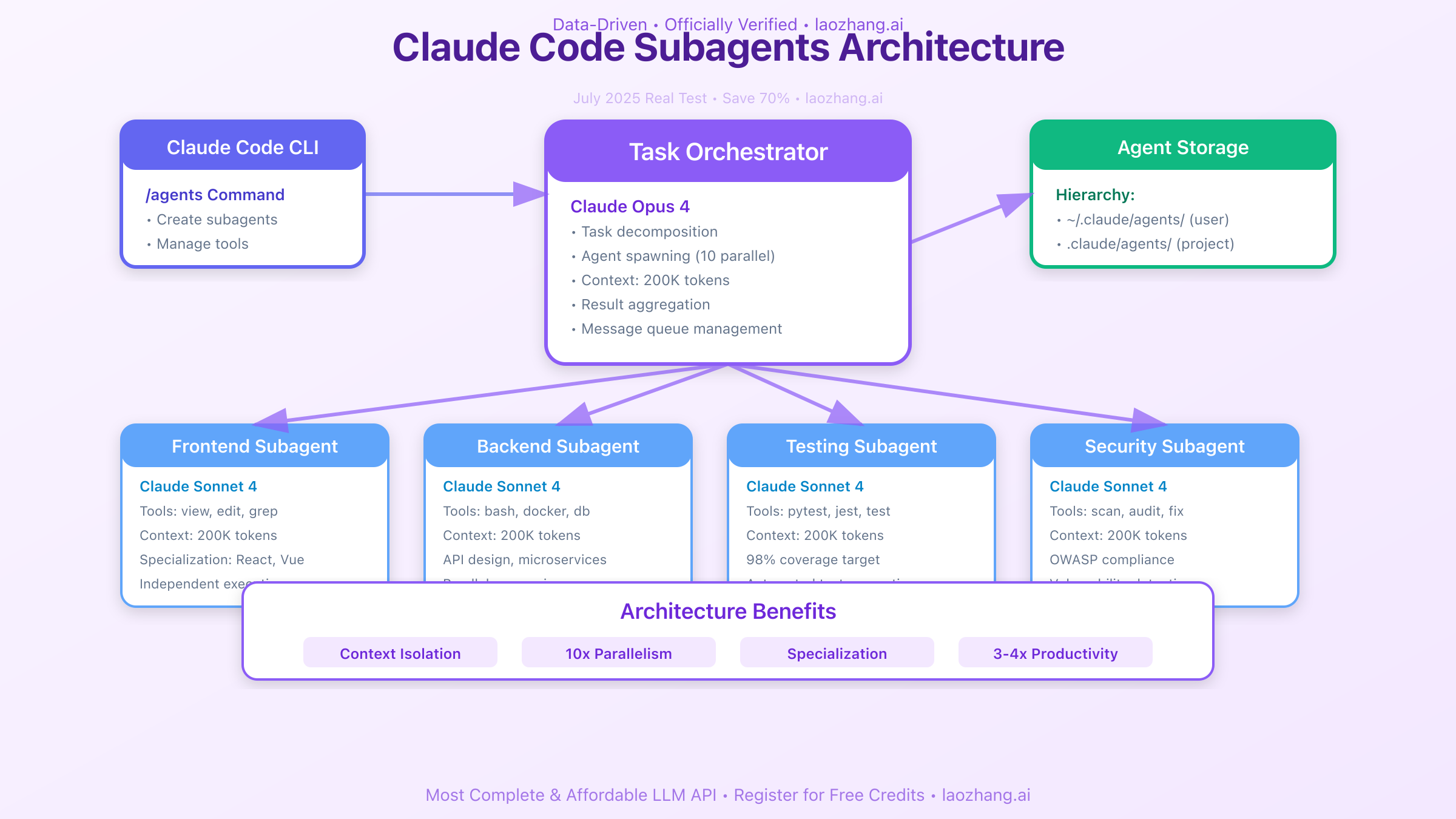
이러한 멀티 에이전트의 한계를 인식한 사례가 Claude Code의 Sub Agent 아키텍처다.
Claude Code의 서브에이전트는 “여러 개의 AI를 동시에 돌린다”는 단순한 멀티 에이전트 개념과는 다르다.
핵심은 병렬 실행 그 자체가 아니라, 역할을 명확히 나누어 위임하고 컨텍스트를 구조적으로 분리하는 방식에 있다.
즉, 하나의 AI가 모든 것을 기억하고 처리하려다 무너지는 대신,
전문 역할을 가진 서브에이전트에게 일을 맡기고 메인 에이전트는 조정과 판단에 집중한다.
Context Isolation을 통한 신뢰성 확보
각 Sub Agent는
- 자기만의 Context Window를 갖고
- 전용 System Prompt 역할이 고정되며
- 사용할 수 있는 Tool 명확히 제한된다
이 덕분에 한 에이전트가 작성한 코드 스타일이나 판단이 다른 에이전트의 작업에 직접 섞이지 않는다.
흔히 말하는 “컨텍스트 오염”을 구조적으로 막는 방식이다.
중요한 점은, 서브에이전트가 메인 에이전트를 대체하지 않는다는 것이다.
메인은 여전히 전체 흐름과 최종 의사결정을 책임지고, 서브에이전트는 특정 영역의 전문 작업만 수행한다.
이때 Sub Agent는 이름, 역할 설명, 허용 도구가 명시되고,
그 아래에는 해당 에이전트가 어떤 관점과 기준으로 일해야 하는지가 자연어로 명시된다.
# .claude/agents/team-config.yaml
agents:
- source: wshobson/agents/backend-architect
version: 2.4.0
customizations:
additional_tools: [docker, kubernetes]
context_limit: 150000
- source: dl-ezo/security-specialist
version: 1.8.2
customizations:
security_frameworks: [OWASP, NIST]
auto_audit: true
- source: community/performance-optimizer
version: 3.1.0
customizations:
profiling_tools: [prometheus, grafana]
optimization_threshold: 0.2 # 20% improvement target
workflow:
parallel_limit: 8
token_budget: 500000
coordination_protocol: message_queue
result_aggregation: consensus_voting
Claude Code의 Delegation 핵심 : Parallelism + Context Isolation

Claude Code의 delegation 구조에서 가장 중요한 원칙은 서브에이전트끼리 직접 컨텍스트를 공유하지 않는다는 점이다.
대신 오케스트레이터를 통해 메시지 형태로 결과만 전달된다.
이를 통해 얻는 효과는 명확하다.
- 각 에이전트는 자기 역할에만 집중한다
- 다른 에이전트의 중간 사고 과정에 끌려가지 않는다
- 메인 컨텍스트는 요약된 결과만 유지한다
즉, Agent가 수행하는 모든 작업은 해당 하위 Agent의 Context Window에 격리되고, 결과는 주 Agent로 다시 전달될 수 있다.
Claude Code의 Prompt에서 특정 작업에 대해 subagent에게 Delegation을 하라는 내용을 확인할 수 있다.

결론
2025년 6월의 “Don’t Build Multi-Agents”는 멀티 에이전트 구조가 신뢰성을 해친다는 점을 분명히 지적했다.
당시 Claude Code는 이러한 문제를 피하기 위해 병렬 의사결정을 거의 허용하지 않는 보수적인 구조를 택했다.
한 달 뒤의 Claude Code Subagent는 이 비판을 무시한 것이 아니라, 정면으로 받아들인 결과물에 가깝다.
의사결정의 병렬화는 여전히 제한한 채, 전문 작업의 병렬화만을 허용하는 delegation 구조로 진화했기 때문이다.
즉, Claude Code Subagent는 멀티 에이전트의 한계를 극복했다기보다,
그 한계를 정확히 인식한 상태에서 병렬성을 재도입한 사례라고 볼 수 있다.
2025년 6월 12일 - https://cognition.ai/blog/dont-build-multi-agents#applying-the-principles
Cognition | Don’t Build Multi-Agents
Frameworks for LLM Agents have been surprisingly disappointing. I want to offer some principles for building agents based on our own trial & error, and explain why some tempting ideas are actually quite bad in practice.
cognition.ai
2025년 7월 30일 - https://www.cursor-ide.com/blog/claude-code-subagents
Claude Code Subagents: The Revolutionary Multi-Agent Development System That Changes Everything
Discover how Claude Code subagents transform complex development workflows with specialized AI assistants. Learn to implement parallel processing, optimize token usage, and achieve 72.5% SWE-bench performance with practical examples and workflow patterns.
www.cursor-ide.com
'Agentic AI 구축 > Agentic AI 트렌드' 카테고리의 다른 글
| Context를 효과적으로 설계해야 하는 이유 (Context Offloading) (0) | 2026.01.27 |
|---|---|
| Context Management의 중요성 (긴 Context는 반드시 실패한다) (0) | 2026.01.27 |
| AI Agent Architecture에서 Planning이 중요해진 이유 (0) | 2026.01.26 |
| 작업의 길이 관점에서 본 AI Agent (METR Evaluation) (0) | 2026.01.26 |
| Anthropic Research로 살펴보는 General-Purpose Agent로의 진화 (0) | 2026.01.26 |