점점 길어지는 Context와 나타나는 한계들
대규모 언어 모델의 Context Window는 빠르게 확장되고 있다.
수십만 토큰은 이제 기본이고, 최근에는 수백만에서 Llama 4 Scout처럼 수천만 토큰 컨텍스트를 지원하는 모델까지 등장했다.
그러나 “컨텍스트만 충분히 길면 에이전트는 자연스럽게 똑똑해질 것”이라는 기대와 달리 그러나 실제 에이전트 시스템에서 긴 컨텍스트는 기대만큼 잘 작동하지 않는다.
오히려 컨텍스트가 길어질수록 새로운 실패 양상이 구조적으로 발생한다.
긴 Cointext가 대표적으로 실패하는 방식은 아래와 같이 4가지로 정리된다.
(https://www.dbreunig.com/2025/06/26/how-to-fix-your-context.html)
- 컨텍스트 오염(Context Poisoning)
환각이나 기타 오류가 컨텍스트에 포함되어, 이후 반복적으로 참조되는 경우 - 컨텍스트 분산(Context Distraction)
컨텍스트가 지나치게 길어져 모델이 학습을 통해 얻은 지식을 무시하고 컨텍스트 자체에 과도하게 집중하는 경우 - 컨텍스트 혼란(Context Confusion)
컨텍스트에 포함된 불필요한 정보가 모델에 의해 사용되어 저품질의 응답이 생성되는 경우 - 컨텍스트 충돌(Context Clash)
컨텍스트에 새로 누적된 정보나 도구가 프롬프트 내의 다른 정보와 충돌하는 경우
이 네 가지 문제는 모두 하나의 원인으로 귀결된다.
컨텍스트에 들어간 모든 정보는 반드시 응답에 영향을 미친다. 결국 문제는 모델의 성능이 아니라 정보 관리 방식이다.
Context를 관리하는 해법들
가장 초기의 해법 : RAG는 여전히 유효하다
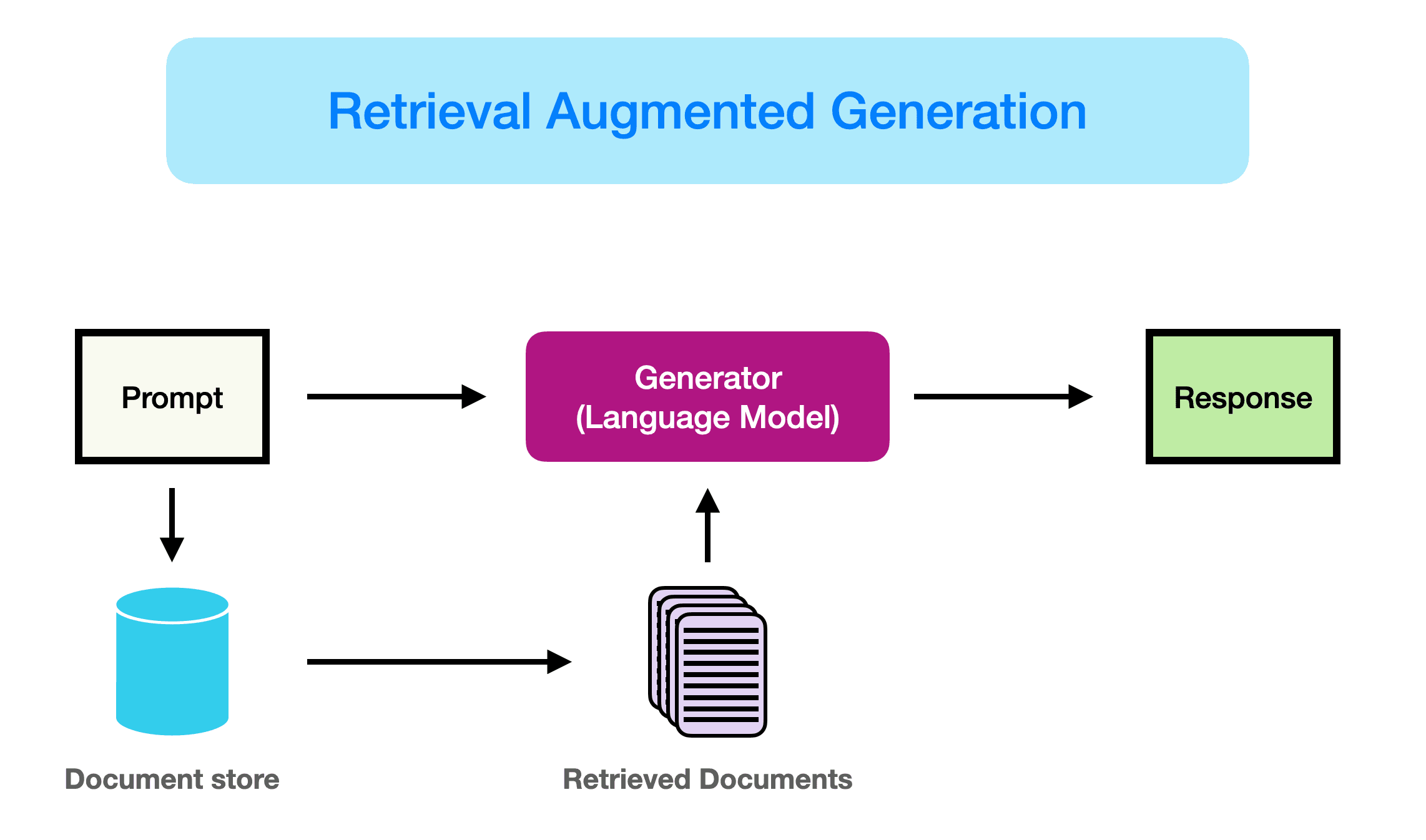
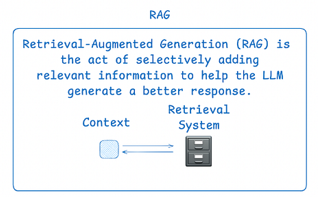
검색 증강 생성(Retrieval-Augmented Generation, RAG)은 필요한 정보만 선별적으로 Context에 추가하는 가장 기본적인 Context 관리 기법이다. Context가 길어질수록 RAG는 불필요해 보이지만, 실제로는 정반대다.
Context Window가 확장될 때마다 “RAG는 죽었다”는 논쟁이 반복된다. "그냥 LLM에 다 넣어버리자”는 것.
하지만 Context에 잡동사니를 마구잡이로 넣으면, 그 잡동사니는 그대로 응답 품질을 떨어뜨린다.
Context가 길어질수록 선별의 중요성은 오히려 커진다.
Tool Loadout: 도구도 Context의 일부다

Tool Loadout은 컨텍스트에 포함할 도구 정의를 관련 있는 것만 선택하는 전략이다.
이 개념은 게임에서 특정 상황에 맞춰 무기와 장비를 고르는 로드아웃 개념에서 가져왔다.

도구 선택의 가장 단순한 방법은 도구 설명 자체에 RAG를 적용하는 것이다.
RAG-MCP 연구에서는 도구 설명을 벡터 데이터베이스에 저장하고, 입력 프롬프트에 따라 관련 도구만 선택하는 방식을 제안했다.



DeepSeek-v3를 대상으로 프롬프트를 구성했을 때,
연구팀은 도구 수가 30개를 넘는 순간부터 올바른 도구를 선택하는 것이 매우 중요해진다는 사실을 발견했다.
30개를 넘기면 도구 설명 간의 내용이 서로 겹치기 시작하며 혼란이 발생한다.
100개를 넘으면 모델은 거의 확실하게 테스트에 실패했다.
RAG 기법으로 도구 수를 30개 미만으로 제한했을 때, Prompt 길이는 크게 줄었고 도구 선택 정확도는 최대 3배까지 향상되었다.
더 작은 모델의 경우, 문제는 30개에 도달하기 훨씬 이전부터 발생한다.
Less is More 논문은 Llama 3.1 8B가 46개의 도구를 제공받았을 때는 벤치마크에 실패하지만, 19개의 도구만 제공했을 때는 성공한다는 점을 보여주었다. 이는 컨텍스트 윈도우의 한계 문제가 아니라, 컨텍스트 혼란의 문제다.
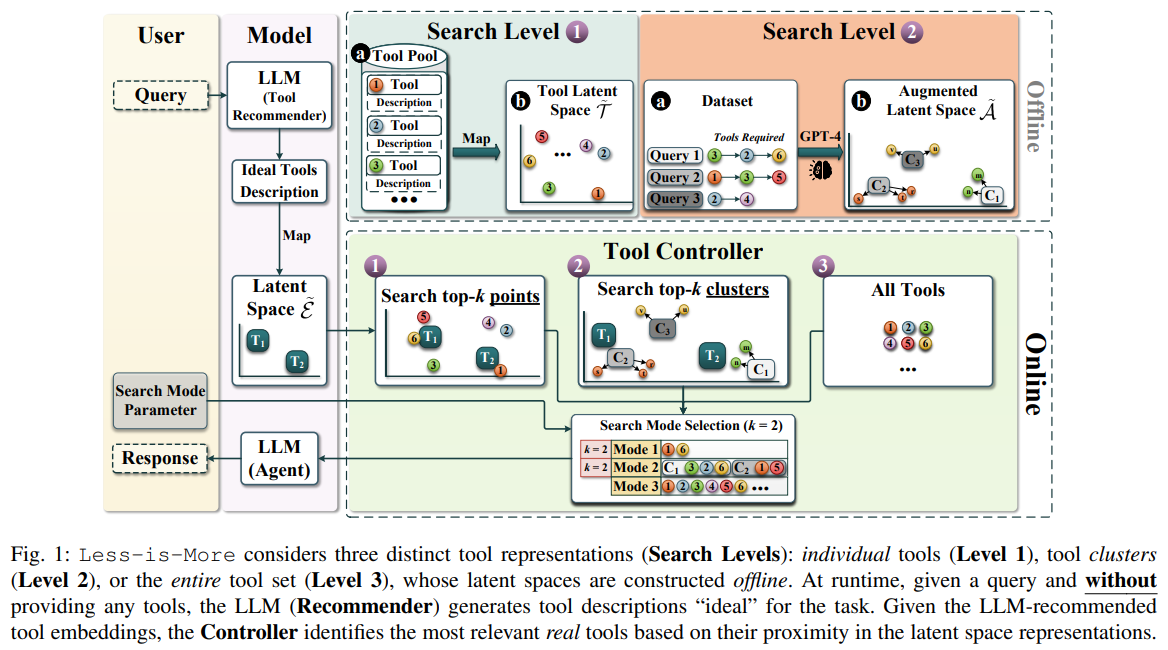
이 문제를 해결하기 위해 Less is More 연구팀은 LLM 기반 도구 추천기를 사용해 동적으로 도구를 선택하는 방법을 제안했다. LLM에게 “사용자 쿼리에 답하기 위해 필요하다고 ‘생각하는’ 도구의 수와 종류”를 추론하게 하고, 그 결과를 의미 기반 검색(다시 말해 도구 RAG)을 통해 최종 로드아웃으로 결정했다.
이 방법을 Berkeley Function Calling Leaderboard에서 테스트한 결과, Llama 3.1 8B의 성능은 44% 향상되었다.
이런 식으로 작은 Context를 유지하면 전력 소비 감소와 속도 향상이라는 장점도 얻을 수 있다.
Manus의 Context Engineering 전략
대규모 언어 모델이 빠르게 발전하면서 에이전트의 성능 역시 모델 자체에서 나온다고 착각하기 쉽다.
그러나 Manus 팀의 결론은 분명하다. 에이전트의 실제 성능, 비용, 안정성은 모델보다 컨텍스트를 어떻게 설계하느냐에 의해 결정된다. 컨텍스트는 단순한 입력이 아니라, 에이전트의 상태이자 메모리이며 실행 환경이다.
컨텍스트의 크기보다 구조가 중요하다
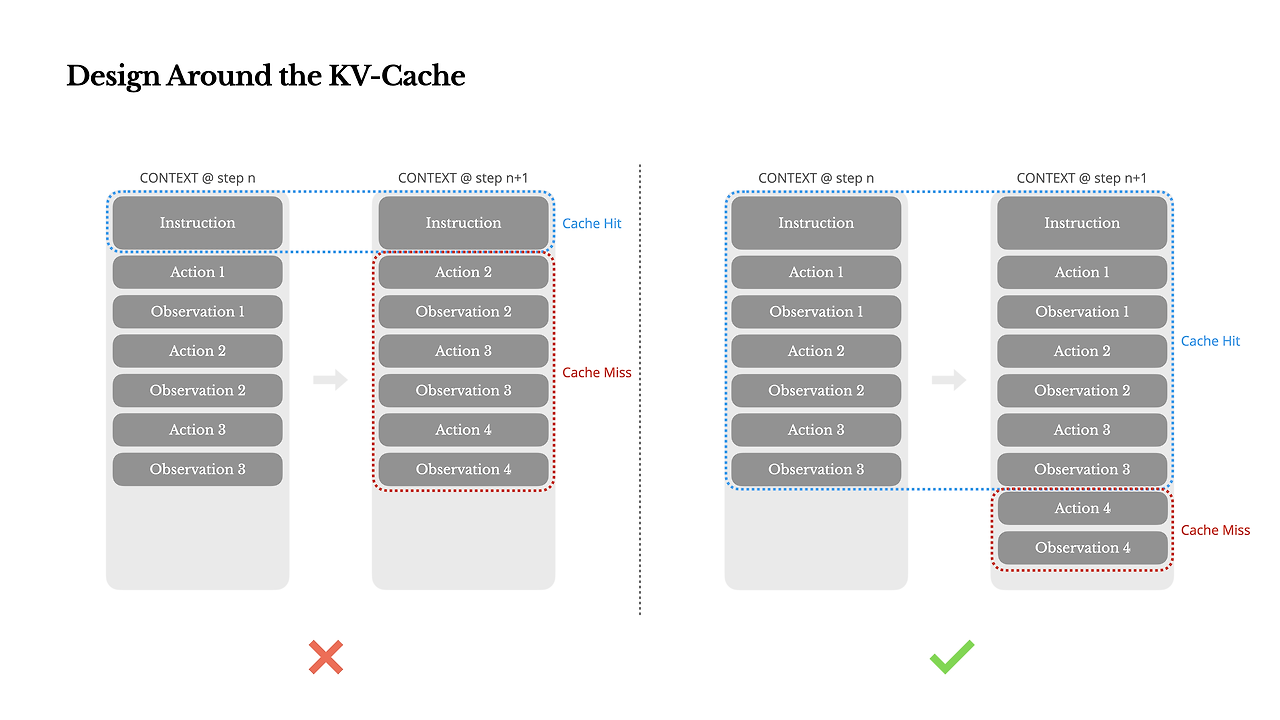
에이전트 루프에서는 출력보다 입력이 압도적으로 많다. 매 스텝마다 관찰과 행동이 누적되기 때문이다.
이 구조에서 가장 중요한 지표는 KV-cache 히트율이다.
프롬프트 접두사가 조금이라도 바뀌면 캐시는 즉시 무효화되고, 지연 시간과 비용은 급격히 증가한다.
이를 방지하기 위해 Manus는 시스템 프롬프트를 절대적으로 고정하고, 컨텍스트를 append-only로 유지한다.
과거의 관찰이나 행동을 수정하지 않으며, 직렬화 결과가 항상 동일하도록 설계한다.
컨텍스트를 동적으로 바꾸는 대신, 안정적인 구조 위에서 캐시 효율을 극대화하는 것이 핵심 전략이다.
컨텍스트는 유지하고, 행동만 제어한다
에이전트가 많은 도구를 사용할수록 자연스럽게 “필요한 도구만 그때그때 넣자”는 발상이 나온다.
그러나 도구 정의를 컨텍스트에서 추가하거나 제거하면, 캐시가 깨지고 이전 행동과의 연결성이 무너진다.
Manus는 컨텍스트를 수정하지 않는다.
대신 디코딩 단계에서 토큰 로짓을 마스킹해 행동 공간을 제한한다.
특정 상태에서는 응답만 가능하게 하고, 특정 상태에서는 정해진 접두사를 가진 도구만 선택하도록 유도한다.
이 방식은 컨텍스트 안정성과 행동 제어를 동시에 만족시키는 현실적인 해법이다.
Anthropic의 Context Quarantine(=Isolation) 전략
컨텍스트 격리(Context Quarantine)는 컨텍스트를 각각 독립된 전용 스레드로 분리하고, 각 스레드를 하나 이상의 LLM이 개별적으로 사용하도록 하는 방식이다.
컨텍스트가 지나치게 길지 않고, 관련 없는 내용이 섞여 있지 않을 때 더 나은 결과가 나온다는 점은 이미 잘 알려져 있다.
이를 달성하는 한 가지 방법은 작업을 더 작고 분리된 작업들로 나누고, 각 작업마다 자체적인 컨텍스트를 갖도록 하는 것이다.


Anthropic은 컨텍스트 격리(Context Quarantine 또는 Isolation)를 통해 문제를 해결한다.
핵심은 주 Agent의 전체 State를 그대로 Sub Agent에게 넘기지 않는 것이다.
주 Agent는 각 Sub Agent에게 필요한 정보만 가공한 컨텍스트를 전달한다.
Sub Agent는 독립된 Context 공간에서 검색, 분석, 코딩을 수행하고, 결과만 구조화된 형태로 주 Agent에게 반환한다.
이 방식은 메인 Context를 요약된 의사결정 정보 중심으로 유지하게 하고, 각 Sub Agent도 자기 역할에 최적화된 Context만 관리하게 만든다. 이는 병렬화가 가능한 리서치 작업에서 특히 효과적이다.
Planning과 Context Offload의 관계
컨텍스트 오프로드는 단순히 토큰을 아끼기 위한 최적화 기법이 아니다.
이는 Planning을 장기적으로 유지하기 위한 구조적 선택이다.
에이전트에서 Planning은 단일 추론이 아니라, 시간에 따라 진화하는 상태다.
계획은 처음 세워지고, 실행 과정에서 수정되며, 때로는 다시 검증되어야 한다.
하지만 이 모든 과정을 대화 히스토리 안에만 유지하려 하면, 컨텍스트는 빠르게 비대해지고 결국 붕괴한다.
따라서 중요한 질문은 “계획을 어디에 둘 것인가”다.
Manus와 Anthropic은 계획을 Context 내부가 아니라 Context 외부에 두어 이 문제를 해결한다.
파일 시스템을 Context Offload 수단으로 사용하기

파일 시스템은 컨텍스트를 오프로드하기 위한 매우 효과적인 수단이다. 핵심 이유는 단순하다.
컨텍스트 창 밖에 정보를 저장해두고, 필요할 때 다시 읽을 수 있기 때문이다.
Anthropic의 Multi-Agent Researcher는 연구 계획을 디스크에 작성해 보존한다.
리서치가 진행된 뒤, 최종 보고서를 생성할 때 이 계획을 다시 읽어 처음의 의도와 결과가 일치하는지 검증한다.
계획이 단발성 프롬프트가 아니라, 지속적으로 참조되는 기준점 역할을 하는 것이다.
Manus 역시 같은 접근을 취한다. todo.md 파일에 작업 계획을 저장하고, 이를 반복적으로 읽고 수정한다.
획은 컨텍스트에서 사라지지 않고, 파일 시스템이라는 외부 공간에 안정적으로 유지된다.
이로 인해 에이전트는 긴 시간 동안 작업을 수행하면서도 방향을 잃지 않는다.
Tool Observation Offload : Token 폭발 방지
파일 시스템은 Planning뿐 아니라, 토큰 소모가 큰 도구 호출을 오프로드하는 데도 매우 유용하다.
특히 검색 도구나 브라우저 도구는 raw observation 자체가 수천, 수만 토큰이 되는 경우가 흔하다.
이를 그대로 Context에 넣으면, 모델은 정보를 처리하기도 전에 Context 한계에 도달한다.
Manus는 이러한 원시 관찰 데이터를 디스크에 저장하고, Context에는 요약본만 남긴다.
Agent는 요약을 통해 도구 결과를 이해하고, 필요할 경우에만 파일을 다시 읽는다.
이 방식은 다음을 동시에 만족시킨다.
- 원시 데이터가 컨텍스트를 잠식하지 않는다
- 정보는 영구적으로 보존된다
- 에이전트는 요약을 통해 판단을 이어갈 수 있다
이는 실제로 Manus에서 광범위하게 사용되는 패턴이다.
파일 시스템 = Agent의 Long-term Memory
여기서 가장 중요한 관찰은, 파일 시스템이 단순한 저장소가 아니라 Agent의 외부 기억 장치로 기능한다는 점이다.
Context는 본질적으로 휘발성이다. 반면 파일 시스템에 저장된 정보는 시간에 따라 보존된다.
이를 통해 에이전트는 다음과 같은 능력을 갖게 된다.
- 장기 계획을 유지한다
- 과거의 결정을 다시 검토한다
- 긴 작업 경로를 따라 누적된 상태를 보존한다
필요할 때는 파일을 다시 읽어 메시지 형태로 컨텍스트에 재주입할 수 있다.
즉, 파일 시스템은 컨텍스트 밖에 존재하지만, 언제든 컨텍스트로 되돌릴 수 있는 기억이다.
이 구조는 긴 경로(long-horizon task)를 수행하는 에이전트에게 결정적인 이점을 제공한다.
'Agentic AI 구축 > Agentic AI 트렌드' 카테고리의 다른 글
| Context Isolation 관점에서 본 Multi-Agent 구조의 한계와 Sub Agent Delegation (0) | 2026.01.27 |
|---|---|
| Context Management의 중요성 (긴 Context는 반드시 실패한다) (0) | 2026.01.27 |
| AI Agent Architecture에서 Planning이 중요해진 이유 (0) | 2026.01.26 |
| 작업의 길이 관점에서 본 AI Agent (METR Evaluation) (0) | 2026.01.26 |
| Anthropic Research로 살펴보는 General-Purpose Agent로의 진화 (0) | 2026.01.26 |