AWS AI First : 컨테이너에서 분산 AI 인프라까지
AI와 컨테이너는 이제 분리할 수 없다

AI는 더 이상 선택 사항이 아니다. 이미 우리는 AI와 함께 일하는 시대에 들어섰다.
컨테이너 기술을 계속 다루다 보니 자연스럽게 이런 질문이 생긴다.
“AI는 컨테이너와 함께 어떻게 진화하고 있는가?”
초기 AI 학습(Training)과 추론(Inference) 단계부터 이미 답은 명확했다.
Anthropic, OpenAI, 그리고 Adobe의 Firefly까지,
주요 AI 서비스는 쿠버네티스 기반 컨테이너 인프라 위에서 학습과 추론을 수행한다.
이 흐름 속에서 자연스럽게 떠오른 결론은 하나다.
AI 서비스를 만들고 싶다면 반드시 쿠버네티스를 이해해야 한다.
AWS가 선언한 AI First 전략


Amazon Web Services는 이러한 변화의 중심에서, 작년 하반기 ‘AWS AI First 전략’을 공식적으로 발표했다.
이 전략의 핵심은 단순하다.
이제는 전통적인 웹 서비스와 AI 기반 서비스가 같은 클라우드 인프라 위에서 동시에 돌아가야 한다
기존 서비스를 운영하던 기업이 AI를 접목해 빠르게 혁신하지 못하면,
시장은 기다려주지 않는다. 변화 속도를 따라가지 못하는 순간, 도태될 가능성은 매우 높다.
Telco에서 AX로: 산업 전반의 전환
이 변화는 클라우드 기업에만 국한되지 않는다.
국내 통신 3사, SK Telecom, KT, LG Uplus는 더 이상 자신들을 “Telco”라 부르지 말라고 한다.

“우리는 AX(AI Transformation) 기업이다.”
통신이라는 강력한 기존 인프라 위에 AI를 어떻게 접목해 새로운 가치를 만들고 고객에게 제공하느냐가 핵심 역량이 되었다.
이 과정에서 AI-RAN, 5G·6G 기술과 AI의 결합이 중요한 키워드로 떠오르고 있다.
이 흐름 속에서 기업 내부도 빠르게 바뀌고 있다.
AI 교육, AI 자격증, AI Fundamentals 이수는 이제 선택이 아니라 필수가 되었다.
AWS AI First 전략의 기술적 핵심
AWS가 말하는 AI First 전략은 단순한 슬로건이 아니다. 아래 네 가지 기술 축이 이를 뒷받침한다.
- 모델 배포: Amazon EKS 기반 대규모 모델 안정적 운영
- 자동 확장: 수요에 따라 인프라 자동 스케일링
- 개발 속도 향상: CI/CD 기반 빠른 실험과 배포
- 비용 최적화: 리소스 효율화를 통한 운영 비용 절감
기업 규모에 따른 AI 전략의 차이
이때 AI First 전략은 모든 기업에 동일하게 적용되지 않는다.
대기업
- 자체 Foundation Model을 직접 개발하거나
- 기존 Foundation Model을 커스터마이징하고 관리하는 역량 확보
스타트업
- Amazon Bedrock, Gemini 등 관리형 서비스를 활용
- 모델 개발보다는 서비스 구현과 실험 속도에 집중
- 프롬프트 엔지니어링 vs 파라미터 튜닝 중 전략적 선택
규모가 커질수록 문제는 더 복잡해진다.
GPU가 1대일 때는 단순하지만, 2대 이상이 되면 네트워크가 성능의 핵심 변수가 된다.
GPU 성능은 충분한데, 시뮬레이션 결과가 느리다면 문제는 대부분 네트워크다.
대역폭뿐 아니라 프로토콜, 드라이버, 스택 구성까지 영향을 미친다.
AWS의 비용 최적화: AI 인프라의 현실적인 과제

이때 AI 인프라는 비싸다.
특히 GPU 인스턴스는 하루 종일 켜두는 순간 비용이 눈덩이처럼 불어난다.
그래서 등장하는 전략이 Spot Instance다.
- 유휴 자원을 저렴하게 사용
- 1~2시간 단위 실험 후 결과만 로컬로 복사
- 실패해도 큰 부담 없음
AI 실험은 보통 파라미터가 조금씩 다른 여러 시뮬레이션을 동시에 돌린다.
퇴근 전 여러 실험을 병렬로 걸어두고, 밤 동안 자원을 최대한 활용한 뒤
결과만 확인하고 인스턴스를 종료하는 방식이 효율적이다.
이 과정에서 AutoML 개념이 중요해진다.
- 파라미터 자동 탐색
- 학습 종료 후 자동 리소스 해제
- 비용과 속도 모두 최적화
쿠버네티스가 만드는 비용 절감 효과

쿠버네티스의 진짜 강점은 자원 재배치다.
- 사용률이 낮은 노드를 자동 종료
- 두 노드의 자원을 하나로 합쳐 비용 절감
- 과도한 리소스를 더 작은 인스턴스로 축소
이러한 최적화가 반복될수록,
개발자는 속도는 빠르게, 비용은 낮게 AI 실험을 반복할 수 있다.
AI 실험의 자동화 사이클
AI First 전략의 완성은 자동화다.
- 매일 생성되는 시뮬레이션 결과
- 수동 접속이 아닌 이메일·리포트 자동 전달
- 결과를 기반으로 다음 실험을 자동 실행하는 Continuous Deployment
이 실험 → 분석 → 결정 → 배포 사이클이 돌아가야 AI 조직이 지속적으로 성장할 수 있다.
AWS Custom Silicon 전략: 하드웨어까지 통합

AWS는 AI 역량 확보를 위해 1000억 달러 규모 투자를 발표했다.

이는 아마존 CEO가 직접 “평생에 한 번 있을 기회”라고 표현할 정도다.
이 전략의 핵심은 하드웨어–소프트웨어 통합이다.
- 범용·저비용 인스턴스
- 추론 특화 인스턴스
- 처리 목적별 최적화 인스턴스
AI 워크로드에 맞춰 선택할 수 있는 옵션이 계속 늘어나고 있다.
분산 AI와 네트워크: RDMA의 시대

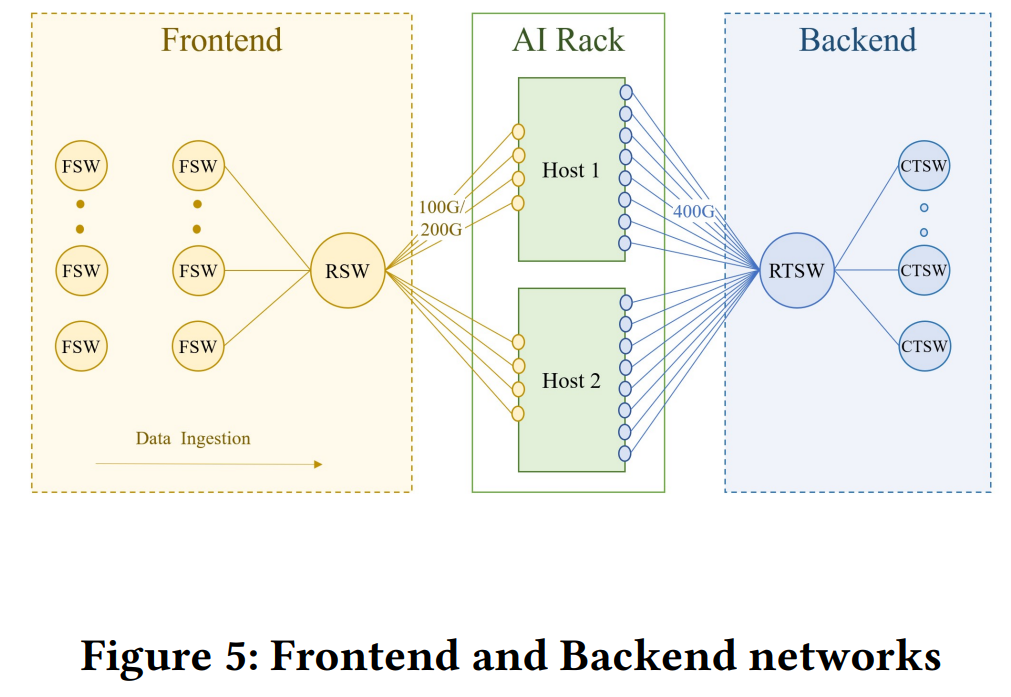
GPU로 넘어오며 기존 네트워크 방식에 한계가 생겼고, 이를 위해 RDMA라는 기술이 새롭게 등장했다.
왜 기존 네트워크 방식으로는 부족할까?
전통적인 네트워크 통신 구조에서는 다음과 같은 경로를 거친다.
GPU → CPU → 메모리 → 네트워크 → 메모리 → CPU → GPU
이 과정에서 발생하는 문제는 명확하다.
- CPU 개입으로 인한 오버헤드
- 메모리 복사로 인한 지연(latency)
- GPU가 많아질수록 병목 현상 급증
GPU 성능이 아무리 좋아져도, 통신이 느리면 전체 학습 속도는 네트워크 속도에 묶인다.
RDMA는 이 구조를 근본적으로 바꾼다.
- CPU와 메모리를 거치지 않고 / GPU ↔ GPU 간 직접 데이터 전송 / 커널 개입 최소화, 복사(copy) 제거
즉, 계산은 GPU가, 통신도 GPU가 직접 한다.
이로 인해 대규모 분산 학습에서 발생하는 통신 병목이 극적으로 줄어든다.
AI 학습, 특히 LLM이나 대규모 시뮬레이션은 대부분 다음 구조를 가진다.
- 데이터 병렬(Data Parallel) / 모델 병렬(Model Parallel) / 파이프라인 병렬(Pipeline Parallel)
이 모든 방식에서 공통적으로 발생하는 작업은 바로 GPU 간 Gradient / Parameter의 교환이다.
만약 GPU 수가:
- 1대 → 문제 없음
- 2대 → 네트워크 개념의 등장
- 8대, 16대, 64대 → 네트워크가 성능을 결정
이 지점에서 RDMA가 없으면, GPU를 추가할수록 오히려 효율이 떨어지는 역설이 발생한다.
특히 여기서 NVIDIA는 GPU 자체뿐 아니라 GPU 간 통신까지 포함한 전체 스택 최적화에 집중하고 있다.

- NVLink / NVSwitch (노드 내부)
- InfiniBand + RDMA (노드 간)
- NCCL 기반 집단 통신 최적화
이제 GPU 성능 경쟁은 단순한 연산 성능(TFLOPS)이 아니라,
GPU + 네트워크 + 소프트웨어 스택의 통합 경쟁으로 옮겨가고 있다.
여기서 많이 오해하는 부분이 있다. “네트워크가 느리면 대역폭을 키우면 되지 않나?”
하지만 RDMA의 핵심은 Bandwidth가 아니라 Latency와 CPU 개입 제거다.
- 프로토콜 설계 / 드라이버 성능 / 커널 바이패스 / 네트워크 카드(NIC)와 GPU 간 연동
이 중 하나라도 잘못되면, GPU는 놀고 있고 네트워크만 바쁘게 된다.
AWS와 같은 클라우드에서는 상황이 더 복잡하다.
가상환경, 멀티 테넌트, 보안 격리의 조건에서 RDMA를 안정적으로 제공하려면
인프라 설계 자체가 RDMA를 전제로 만들어져야 한다.
그래서 대규모 AI 학습을 제공하는 클라우드들은 전용 네트워크, AI 특화 인스턴스, RDMA 지원 Fabirc을 함께 제공한다.
GPU가 늘어나면서 RDMA는 필수 기술이 되었다.
- CPU·메모리를 거치지 않고 GPU 간 직접 통신
- 대규모 분산 학습에서 병목 최소화
이제 AI 성능 경쟁의 핵심은 GPU + 네트워크 통합 기술이다.
AWS Infra 통합의 완성: SageMaker, EKS, Bedrock

AI First를 위한 AWS의 AI 전략이 강력한 이유는 개별 서비스의 우수함이 아니라, 인프라 통합 완성도에 있다.
Amazon SageMaker, Amazon EKS, Amazon Bedrock는 각각 역할이 다르지만, 하나의 AI 라이프사이클 안에서 유기적으로 연결된다.
SageMaker는 데이터 준비부터 학습, 실험 관리, 배포까지 ML 전 과정을 담당하며,
EKS는 대규모 AI 워크로드를 컨테이너 기반으로 안정적으로 운영하는 중심 인프라 역할을 한다.
여기에 Bedrock은 Foundation Model을 직접 운영하지 않아도 되도록 하여,
기업이 모델 관리 부담 없이 AI 서비스를 빠르게 구현할 수 있게 해준다.
이 세 가지가 결합되면서 AWS는 “모델을 만들고, 배포하고, 운영하는 전 과정”을 하나의 플랫폼 안에서 해결하는 AI 인프라 통합 구조를 완성했다.
이는 단순한 클라우드 서비스 제공을 넘어, AI를 바로 비즈니스로 연결할 수 있는 실행 환경을 의미한다.
'Cloud & Edge 인프라 > AWS Cloud Platform' 카테고리의 다른 글
| AI First 시대로의 전환과 오픈소스의 중요성 (0) | 2026.01.15 |
|---|