LangChain의 구조
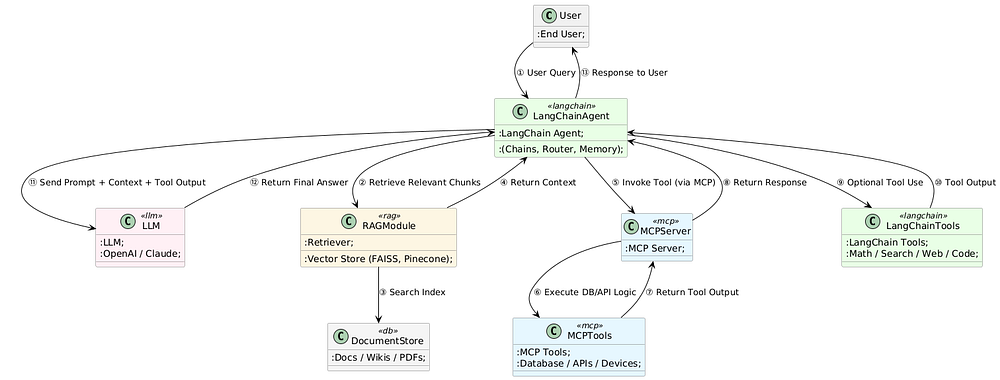
LangChain의 구조를 정리하면 위와 같은 식으로 동작한다.
LangChain은 아래의 "REACT: Synergizing Reasoning and Acting In Language Models"라는 논문의 아이디어를 기반으로 탄생한 Framework이다.
LangChain Agent는 내부적으로 다음의 Loop를 반복해서 돈다.
- Tool 목록 + 설명을 LLM에 보여줌
- MCP Tool이든, LangChain Tool이든, 결국은
- 이름, 무슨 일을 하는지 설명, 입력 포맷(스키마)
위와 같은 정보를 프롬프트(또는 OpenAI tool spec)로 LLM에게 넘겨줌.
- 이름, 무슨 일을 하는지 설명, 입력 포맷(스키마)
- MCP Tool이든, LangChain Tool이든, 결국은
- Decide(): “지금 무엇을 할까?”
- LLM에게 현재 대화 상태 / 작업 목표 / 사용 가능한 Tool 목록을 주고 다음과 같이 묻는다.
- “지금 바로 답을 출력할래? 아니면 어떤 Tool을 쓸래? 쓴다면 어떤 입력으로?”
- Action(): Tool 호출
- LLM이 “Tool A를 이런 입력으로 호출하겠다”라고 텍스트로 결정하면,
- 프레임워크(LangChain)가 실제 MCP Tool API를 호출해서 실행한다.
- Observation: Tool 실행 결과를 다시 LLM에게 보여줌
- Tool에서 나온 JSON/텍스트/결과를 LLM에게 다시 넣고,
- “이 결과를 보고 다음에 뭘 할래?”라고 다시 묻는 구조이다.
- 반복
- LLM이 또 Decide() → Action() → Observation…
LangChain의 구조적 한계
이런 LangChain의 구조는 Tool이 몇 개 되지 않을 때는 그럭저럭 잘 동작한다.
왜냐하면 LLM 입장에서 선택지가 적기 때문에 "이 상황에선 이런 Tool을 쓰면 되겠구나"라는 것을,
Prompt만으로도 학습하거나 추론할 수 있기 때문이다.
그래서 작은 시스템에서는 LLM에게 Tool 목록을 던져주고 알아서 골라 쓰게 하는 방식이 꽤 잘 먹힌다.
문제는 MCP Tool이 수십, 수백 개가 되고, 이 Tool들이 Side Effect를 가지기 시작하면 발생한다.
이 경우 다음의 문제가 발생한다.
(1) 액션 공간 폭발
- LLM은 매 스텝마다:
- 어떤 Tool을 쓸지? (수십 개 중 하나)
- 어떤 순서로 이어갈지?
- 어느 시점에 “이제 답을 끝낼지?”
- 이게 사람이 보기엔 “워크플로우 설계 문제”인데,
- LangChain Agent에선 그걸 전부 LLM의 토큰 단위 추론에 맡겨버리는 구조라서,
- 길어질수록, 복잡해질수록, 분기 많을수록 점점 불안정해지게 된다.
결과적으로 필요 없는 Tool을 호출한다든지, 같은 Tool을 반복 호출하는 순환 루프에 빠진다던지, 중간 상태를 잃어버려서 앞뒤가 안 맞는 액션을 한다든지 하는 문제가 생김.
(2) 글로벌 상태/컨텍스트 관리의 한계
복잡한 시스템에서는:
- “현재 세션이 어떤 리소스를 이미 잡고 있는지”
- “어떤 Tool 호출이 선행 조건인지(예: 로그인 → 세션 발급 → 그 세션으로만 API 호출 가능)”
- “어느 호출이 실패했고, 롤백이 필요한지”
같은 시스템 레벨 상태를 관리해야 하는데,
- LangChain Agent는 이걸 대부분 “프롬프트 속 자연어 설명 + LLM의 임시 기억”에 의존함.
- 코드/그래프 레벨로 강제되고 검증되는 State machine이 아니라,
- “LLM이 잘 기억하겠지…”에 기대는 구조라
- 스텝이 길어질수록 컨텍스트 깨지고, 순서 꼬이고, 일관성이 깨지기 쉬움.
(3) 에러 처리/예외 상황에서 취약
- MCP Tool이 네트워크 오류, 타임아웃, 이상한 응답을 줄 수 있음.
- 이때:
- 재시도할지?
- 다른 Tool로 fallback 할지?
- 사용자에게 오류를 전달할지?
- 이런 로직을 명시적 코드로 짜는 게 아니라, 대충:
- “에러가 나오면 적절히 재시도해” 같은 프롬프트 문장으로 LLM에게 부탁하는 수준이기 때문에,
- 특정 상황에선 잘 처리되다가, 다른 상황에선 이상하게 행동하는 식의 non-deterministic behavior가 나옴.
Opaque한 LangChain의 한계를 극복하기 위한 LangGraph의 등장
따라서 현재 구조에서는 Agent의 "생각 과정"이 대략 다음과 같이 된다.
- LangChain: ‘도구 리스트 + 설명 + 지금까지의 대화 + Tool 결과’를 프롬프트에 몽땅 넣고,
“이제 다음 스텝을 계획해봐” 라고 LLM에 요청 - LLM 내부에서 일어나는 건:
- 토큰 레벨 확률에 따라 “어떤 Tool을 선택할지”, “어떤 입력을 줄지”를 생성하는 과정인데,
- 이게 코드/그래프 형태의 명시적인 로직이 아니라, 완전히 블랙박스임.
즉, 왜 이 시점에서 Tool A가 아닌 Tool B를 골랐는지, 왜 에러에서 재시도가 아닌 종료를 선택했는지,
왜 똑같은 프롬프트와 똑같은 Tool 목록에서 언제는 잘 동작하고, 언제는 이상한 Tool을 쓰는지,
이걸 분석/디버깅하기가 엄청 까다롭다는 의미에서 opaque하다고 할 수 있다.

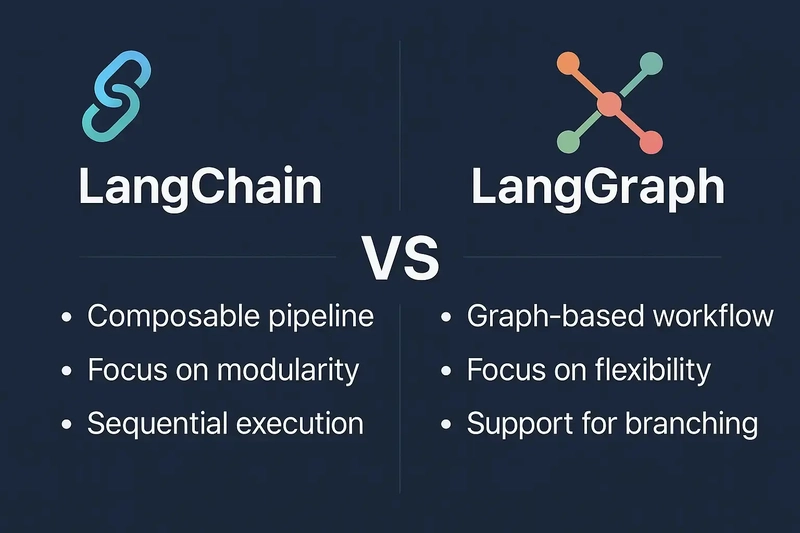
이런 문제를 개선하고자 나온 것이 LangGraph이다.
기존의 BlackBox라고 할 수 있는 Chain 형태를, State Machine 기반의 상태/노드/엣지 기반의 Workflow로 명시적으로 구조화함으로 인해서 LLM의 너무 큰 자율성을 제한시키는 구조이다.
- LLM은:
- “어떤 노드에서 어떤 결정을 내릴지” 혹은
- “노드 내부의 세부 로직을 채우는 역할” 정도로 한정
→ 이런 식으로 가면:
- 어떤 경로로 Tool이 호출될 수 있는지 정적 구조가 눈에 보이고,
- 특정 제약을 코드/그래프 수준에서 강제할 수 있고,
- 디버깅/테스트/리플레이가 훨씬 쉬워졌다는 장점이 있다.
다음 포스트에서 LangGraph의 구조에 대해 구체적으로 살펴볼 것.
'Agentic AI 구축 > LangChain & LangGraph' 카테고리의 다른 글
| [LangGraph 기초 2] Edge의 개념 (병렬 실행과 분기) (0) | 2026.01.03 |
|---|---|
| [LangGraph 기초 1] Node와 State의 개념 (0) | 2026.01.03 |
| LangChain과 LangChain 생태계 총정리 (LangChain, LangGraph, LangSmith) (0) | 2025.12.16 |
| LangChain에서 HuggingFace의 오픈소스 LLM 모델 (Llama 시리즈) 사용하기 (0) | 2025.12.11 |
| LangChain에서의 MCP 구현 설명 (@tool의 의미) (0) | 2025.11.05 |